기계어, 어셈블리, 고급언어
기계어
0과 1로 이루어진 언어로 직접 cpu,memory등을 제어하는 저급언어이다.
어셈블리
어셈블리어는 기계어를 묶어서 기호화한 것이다.
기계어 명령어를 ADD 등과 같이 알아보기 쉬운 심볼로 일대일 대응시킴.
assembler를 통해서 기계어로 변환과정을 거쳐야 한다.
어셈블리는 기계어를 기호로 표현해놓았기 때문에 기계의 동작과정을 잘 알고 있어야 사용가능
고급언어
고급 언어는 자연어에 가까운 언어이다.
고급언어로 작성한 코드는 기계어로 번역이필요하다.
번역을 하는 장치는 컴파일러와 인터프리터가 있다. 컴파일러 고급 언어에는 c,c++등이 해당하고
인터프리터 고급 언어에는 python 등이 해당한다.
컴파일러 고급 언어는 소스코드를 통째로 머신 코드로 바꾸고
인터프리터 고급 언어는 line by line으로 기계어로 바꿔서 실행한다.
컴파일러 고급 언어는 소스코드 내에 잘못된 것이 있으면 컴파일 자체가 수행되지 않고
인터프리터 고급 언어는 실행과정에서 문제가 발생할 수 있다.
컴파일러, 링커
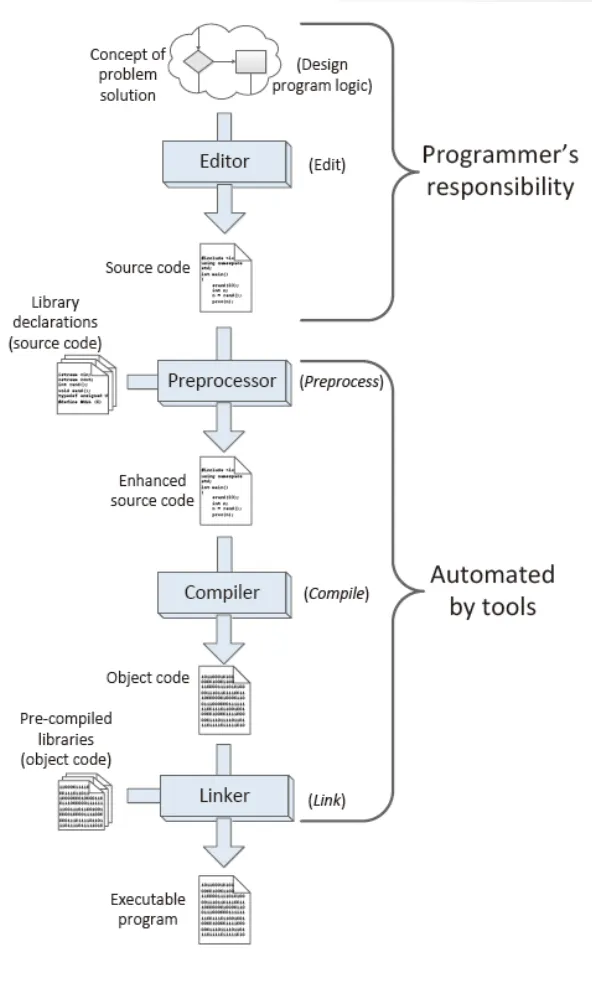
build: 에디터로 작성된 소스코드를 실행가능한 파일로 바꾸는 것
빌드 툴을 통해서 build과정을 거친 소스코드는 실행파일이 된다.
빌드 툴은 preprocessor, compiler, Linker로 구성됨
preprocessor: library파일 포함 및 매크로 변환 작업 등 전처리.
compiler: 소스코드를 object code로 바꿈. object code는 기계어 혹은 어셈블리 코드이다. 여러개의 소스코드는 각각 컴파일되고 Linker에 의해서 실행파일로 연결됨.
Linker: 목적코드를 링킹해서 실행파일로 만듦. 라이브러리는 쉽게 사용하기 위해서 미리 만들어놓은 목적코드라고 할 수 있으며 Linking과정은 라이브러리와 연결하는 과정 또한 포함.
visual studio
solution = 프로젝트의 묶음. 프론트와 백엔드 두개의 프로젝트가 하나의 솔루션 안에 들어감.
콘솔 프로그램 = 터미널에서 사용하는 프로그램
.sln = solution관리 파일, .proj = project관리 파일
solution을 build하면 포함된 모든 project가 build되고 project build는 개별 project만 build함
build할 때 debug mode를 사용하면 디버그 정보를 포함하기 때문에 배포시에는 release 사용
Static Libary, Dynamic Library
static library는 compile time에 Linking되면서 실행파일에 포함됨. .dll파일 등이 있음.
dynamic library는 프로그램 실행과정에서 가져와서 연결됨
컴파일 에러, 런타임 에러
컴파일 에러는 Syntax Error, Type Check Error, 파일 참조 에러 등 컴파일링되는 과정에서 발생하는 에러로 컴파일러가 문제를 일으킨 소스코드 라인을 알려준다.
런타임 에러는 소스코드가 이미 실행가능한 프로그램으로 성공적으로 컴파일 된 이후 발생하는 에러로 프로그램의 실행중에 발생하는 에러이다. divide by zero, Null reference, Memory 부족 에러 등이 있다.
Process memory Layout
실행가능한 파일을 실행하면 CPU는 HDD에서 프로그램을 읽어와 RAM에 로드하며 프로세스는 메모리 공간을 할당받는다. 프로그램이 저장되는 메모리 공간은 Code, Data, Stack, Heap Segment로 나뉜다
Code(text) Segment ⇒ Instruction이 포함된 object file. text segment에 있는 명령어를 변경하지 못하도록 read-only메모리 공간으로 지정됨. 프로세스가 종료될 때까지 유지됨.
Data Segment ⇒ 전역변수와 static변수를 저장한다.
Stack ⇒ 컴파일 타임에 크기가 결정되며 메모리 상위 주소에서 하위 주소로 쌓인다. SP(Stack Pointer)레지스터는 스택의 가장 상단을 가리키며 스택이 push될때마다 값이 조정된다. 하나의 함수가 호출될 때 push된 값들의 집합을 stack frame이라고 한다. 새로운 함수가 호출될 때 stack에 공간이 할당되고 지역변수, 리턴주소, 매개변수(레지스터 값) 등을 포함한다. 컴파일러에 의해 자동으로 관리된다.
Heap ⇒ 동적 메모리 할당이 수행되는 공간이다. 런타임에 크기가 결정되며 프로그래머에 의해 관리된다.

main
C/C++ 프로그램에서는 반드시 main함수가 하나 존재해야 하며 프로그램이 시작되면 OS에 의해서 main함수가 호출되고 main함수가 종료되면 프로그램이 종료된다.
std (Standard libary)
standard의 약자로 C++ 표준 라이브러리의 네임스페이스이다.
cin, cout, vector등 다양한 클래스와 함수를 포함하고 있다.
#includ <iostream>
using namespace std;
int main(){}
C++
복사
using namespace std는 std네임스페이스 내의 이름을 더 간편하게 사용할 수 있게 해준다.
하지만 cin, cout, STL등을 사용하려면 해당 헤더 파일을 include해야한다.
using namespace std를 사용하지 않으면 기본적으로 global(전역) namespace를 사용한다.
global namespace는 사용자 정의 함수나 변수가 속하는 namespace이다.
std에 포함되어 있는 기능들 예시
•
std::thread, std::mutex 등 쓰레드 동기화 기능
•
std::random 랜덤숫자 생성 함수
•
std::exception 예외 처리 관련 클래스
preprocessing directive
전처리문은 컴파일하기 전 동작해서 소스코드를 변경시킨다. 전처리문은 #으로 시작하며 include는 해당하는 파일을 copy해서 소스코드에 paste하여 코드를 변경시킨다.
iostream은 입출력 stream과 관련된 라이브러리이며 cout,cin등의 함수를 포함한다.
#include <iostream>
int main(){
int x;
std::cin >> x;
std::cout << "Hello world!" << x << std::endl;
return 0;
}
C++
복사
<< 는 insertion operator이다.
>>는 extraction operator이다.
return 0;은 작성하지 않아도 자동으로 추가되어 에러는 발생하지 않는다. 아무 문제없이 프로세스가 종료된 경우에 0을 리턴한다.
declaration & definition, initialization
declaration: 변수의 이름과 타입을 컴파일러에게 알려준다. 선언에서는 변수가 메모리 공간을 할당받지 않는다.
definition: 변수를 실제로 생성하고 메모리 공간을 할당하는 과정.
선언과 정의가 동시에 이루어질 수 있지만 선언만 이루어지는 경우도 있다
initialization: 변수의 초기값을 설정함. 초기화하지 않고 변수를 사용하면 의도하지 않은 값이 들어있음.
extern int x; //declaration만 이루어짐
int x; // declartion과 definition이 동시에 이루어짐
int x = 10; //declaration, definition, initialization
C++
복사
type casting
int main() {
int x = 7, y = 3, z1;
double z2;
//z1은 int type이므로 손실이 발생해서 23이 할당됨
z1 = static_cast<double>(x) / y * 10;
//z2는 double type이기 때문에 23.33..이 할당됨
z2 = static_cast<double>(x) / y * 10;
std::cout << z1 << " " << z2 << std::endl;
}
C++
복사
static_cast를 통해서 컴파일 타임에 타입 체크를 수행할 수 있다. 런타임에 에러가 발생할 가능성이 있다.
실수를 정수형 변수에 저장하면 손실이 발생하기 때문에 compiler warning이 발생
floating point
sign, mantissa, exponent로 이루어짐.
#include <iostream> int main() {
double one = 1.0, one_fifth = 1.0 / 5.0,
zero = one - one_fifth - one_fifth - one_fifth - one_fifth - one_fifth;
std::cout << "one = " << one << ", one_fifth = " << one_fifth
<< ", zero = " << zero << '\n';
}
C++
복사
1에서 0.2를 5번 빼도 결과가 0이 아닌 이유는 부동 소수점 연산 과정에서 발생하는 오차 때문이다. 이진수로 나타낼 때 무한소수가 발생하는 경우 정확히 표현할 수 없으며 0.25, 0.125와 같이 이진수로 나타낼 수 있는 경우가 아닌 0.2와 같은 경우 근사값으로 저장하며 연산과정에서 작은 오차가 발생함.
boolalpha
std::cout << std::boolalpha << a<< std::endl;
C++
복사
std::cout으로 true, false를 출력할 때 true는 1, false는 0으로 출력되기 때문에 사용함.
overflow
#include <iostream> int main() {
unsigned char ch1 = 100, ch2;
ch2 = ch1 + 156;
std::cout << static_cast<int>(ch2) << std::endl;
}
C++
복사
unsigned char의 범위는 0~255이며 ch2의 값이 256이 되면 범위를 초과하게 되고
255의 binary인 1111 1111에서 1을 초과하면 0001 0000 0000이 되고
char은 1바이트이므로 결과값은 0이 되는 오버플로우가 발생한다.
postfix, prefix
#include <iostream> int main() {
int x = 10, y = 7, z;
z = ++x * y--;
std::cout << x << std::endl; // 11
std::cout << y << std::endl; // 6
std::cout << z << std::endl; // 77
}
C++
복사
prefix/postfix는 변수 앞/뒤에 붙는 연산자로 side effect로 값을 증가 혹은 감소 시킨다.
prefix는 변수의 값을 변경한 후의 값을 리턴하고
postfix는 변경되기 전 변수의 값을 리턴하고 값을 변경한다.
auto
auto count = 0;
auto ch = 'Z';
auto limit = 100.0;
// auto x;
C++
복사
assign되는 값으로부터 자동으로 타입을 추론한다. 선언만 할때는 사용할 수 없다.
pointer
포인터 = memory address를 저장하는 변수
#include <iostream>
int multiply(int x, int y) {
return x * y;
}
int evaluate(int (*f)(int, int), int x, int y) { // function pointer
return f(x, y);
}
int main() {
int x1 = 10;
int *p1 = &x1;
int **pp1 = &p1;
**pp1 = 11;
std::cout << x1 << std::endl; // 11
*p1 = 12;
std::cout << x1 << std::endl; // 12
std::cout << evaluate(&multiply, 2, 3) << '\n'; // 6
}
C++
복사
p1은 x1의 주소를 가리키는 포인터.
pp1은 포인터 int타입 변수의 주소를 가리키는 포인터 p1을 가리키는 더블 포인터
& ⇒ address operator. 주소값을 반환함.
* ⇒ dereferencing operator. 포인터가 가리키는 주소에 있는 값에 접근함.
주소와 정수의 연산은 자동으로 데이터타입의 메모리사이즈를 곱해서 더해주는 주소연산으로 casting됨.
function pointer는 함수를 가리키는 포인터.
Reference variable
int x;
int& r = x;
C++
복사
참조형 변수는 특정 변수에 대한 별칭이다. 원래 변수와 동일한 메모리 주소를 공유하며 참조변수를 통해서 원래 변수의 값을 수정하거나 접근할 수 있다. 참조변수는 선언시 반드시 초기화해야 하며 다른 변수에 재할당할수 없음.
참조변수를 이용해서 함수에 인자를 전달하면 복사를 피할 수 있어서 성능이 향상됨.
Pass by Reference, Pass by Address, Pass by value
pass by value는 변수의 복사본을 생성하는 방식이다. 복사된 변수는 함수의 범위 내에서 지역변수로 사용되며 원래 변수의 값에는 영향을 주지 않는다. 함수에서 return되는 값도 변수의 복사본이다. 함수 외부에 있는 원본 변수의 값이 보호되는 장점이 있다.
//int type포인터를 반환하는 함수. pass by address로 인자를 받음
int *Fn(int *p1, int *p2) { return *p1 > *p2 ? p1 : p2; }
int main() {
int x = 10, y = 20;
int *p = Fn(&x, &y);
*p += 5;
std::cout << x << std::endl;
std::cout << y << std::endl;
}
C++
복사
pass by address는 주소값을 인자로 전달해서 포인터로 주소값을 저장함.
void increment(int& num) {
num++;
}
int main() {
int value = 5;
increment(value); // value는 6으로 변경됨
}
C++
복사
pass by reference는 변수를 인자로 전달하면 참조변수를 사용해서 직접 변수를 참조하는 방법. pass by reference를 사용하면 Null체크가 필요없고 dereferencing할 필요가 없다.
static array, dynamic array
static array는 처음에 크기를 할당하고 사용하며 쓰이지 않는 부분이 있기 때문에 메모리 사용이 비효율적이다. 또한 지정한 범위를 넘어가는 경우를 처리할 수 없다.
dynamic array를 사용하면 runtime에 new와 delete 연산자를 통해서 메모리를 할당 및 해제할 수 있다.
일반적인 지역변수는 스코프 안에서 사용된 후 메모리 공간이 반환되는데 동적으로 할당한 메모리는 프로그램이 종료될 때까지 메모리에 남아있기 때문에 delete으로 해제해주지 않으면 memory leak이 발생한다.
int a[10];
int b[10];
b = a; // 불가능
// a == &a[0]
// a[i] == *(a+i)
C++
복사
static array의 주소는 runtime에 결정되는것이 아니라 상수로 이미 결정되어있음.
배열의 이름은 첫번째 요소의 주소값과 동일하다. 배열을 함수의 인자로 전달할 때 배열 자체가 전달되는것이 아니라 배열의 주소값을 전달한다. 주소값에 정수를 더하면 type의 byte크기만큼 더해져 다음 element의 주소값이 된다.
vector
#include <iostream>
#include <utility>
#include <vector>
using namespace std;
void print(std::vector<double> v) {
for (int i = 0; i < v.size(); ++i) [
std::cout << v[i] << ", ";
}
std::cout << std::endl;
}
int main() {
std::vector<double> v0 = { 1 }, v1(3), v2(3, 2); //vector선언하는 방법
print(v0); // 1
print(v1); // 0, 0, 0
print(v2); // 2, 2, 2
vector<pair<int, string>> vec;
vec.push_back(make_pair(1, "apple"));
for (const auto &p : vec) {
cout << "key:" << p.first << ", value:" << p.second << endl;
}
return 0;
}
C++
복사
vector는 동적으로 메모리를 할당하기 위해서 존재함. c++ STL에서 제공하며 내부적으로 메모리를 자동으로 관리하고 객체가 더이상 필요없어졌을 때 자동으로 메모리가 해제됨. dynamic memory는 사용자가 직접 메모리를 할당하고 해제해야 함. vector는 크기가 동적으로 변경되며 필요에 따라 자동으로 크기가 늘어나거나 줄어듦.
pair는 두 개의 값을 함께 묶어주는 자료구조로, pair<type1,type2>의 형태를 가진다.
p.first, p.second와 같이 첫번째, 두번째 값에 접근할 수 있다.
string
char 배열은 고정길이 배열이며 마지막은 null문자로 끝나야 한다.
string은 c++ STL에서 제공되는 클래스로 dynamic memory를 사용하여 크기를 자동으로 조절한다. 따라서 사용자가 메모리를 신경 쓸 필요가 없다.

Input, Output Streams
stream = 데이터를 입력하거나 출력하는 통로 역할을 하는 추상적인 개념.
input stream은 키보드 입력(std::cin), 파일 읽기, socket에서 데이터 읽어오기 등이 있음
output stream은 콘솔 출력(std::cout), 파일 쓰기, socket으로 데이터 전송 이 있음
std::cin은 사용자 입력을 임시로 저장하기 위해서 buffer를 사용함
// std::cin >> x;
// std::cout << x;
// cin.operator>>(x);
// cout.operator<<(x);
// cout.operator<<(x).operator<<('\n');
#include <iostream>
#include <limits>
int main() {
int x;
std::cout << "Please enter an integer: ";
while (!(std::cin >> x)) {
std::cout << "Bad entry, please try again: ";
std::cin.clear();
//입력 버퍼에 남아있는 모든 문자를 줄바꿈 문자를 만날때까지 무시
//이전 입력에서 남아있는 불필요한 데이터를 제거해서 다음 입력이 올바르게 처리되게 함
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), '\n');
}
std::cout << "You entered " << x << '\n';
}
int main() {
std::string line;
// cin에서는 space를 종료로 간주하기 때문에 getline을 사용해야 space까지 포함해서 받는다.
getline(std::cin, line);
std::cout << "You entered: \"" << line << "\"" << '\n';
}
C++
복사
ifstream은 input file stream으로 파일에서 데이터를 읽어오기 위한 스트림 클래스.
ofstream은 output file stream으로 파일에 데이터를 쓰기 위한 스트림 클래스.
#include <iostream>
#include <fstream>
#include <string>
//ifstream
int main() {
std::ifstream inFile("input.txt"); // 파일 열기
if (!inFile) { // 파일 열기 실패 시
std::cerr << "Unable to open file input.txt";
return 1; // 오류 코드 반환
}
std::string line;
while (std::getline(inFile, line)) { // 파일에서 한 줄씩 읽기
std::cout << line << std::endl; // 읽은 내용 출력
}
inFile.close(); // 파일 닫기
return 0;
}
//ofstream
int main() {
std::ofstream outFile("output.txt"); // 파일 열기
if (!outFile) { // 파일 열기 실패 시
std::cerr << "Unable to open file output.txt";
return 1; // 오류 코드 반환
}
outFile << "Hello, World!" << std::endl; // 파일에 데이터 쓰기
outFile.close(); // 파일 닫기
return 0;
}
C++
복사
Separating Method Declarations/Definitions
// Point.h
#ifndef Point.h
#define Point.h
class Point {
double x;
double y;
public:
Point(double x, double y);
double get_x() const;
double get_y() const;
};
#endif
#ifdef __linux__
// 리눅스에서만 실행되어야 하는 코드
#endif
#ifdef __ANDROID__
// 안드로이드에서만 실행되어야 하는 코드
#endif
// Point.cpp
Point::Point(double x, double y) : x(x), y(y) {}
double Point::get_x() const { return x; }
double Point::get_y() const { return y; }
C++
복사
클래스의 선언은 헤더파일에, 구현은 cpp소스파일에 구분해서 작성한다. 전처리문을 통해서 헤더파일을 include한다. 헤더파일에서 같은 클래스의 선언이 두 번이상 포함되면 재정의 에러가 발생한다. 그래서 #pragma once 전처리 지시문을 통해서 해당 헤더파일이 한번만 포함되도록 할 수 있다.
Include Guard를 통해서 헤더파일이 중복되는것을 막을 수도 있다. #ifnedf는 매크로가 정의되어있지 않으면 다음 코드를 포함하도록 하고 #define을 통해서 헤더파일을 정의하고 #endif를 통해서 조건문을 종료한다.
__linux__ 와 같은 매크로를 통해서 특정 플랫폼에 따라 조건부 컴파일을 수행할 수 있음.
inline function
런타임에 함수 호출이 여러번 이뤄지면 오버헤드가 존재하므로 짧은 함수는 인라인 함수로 작성하면 컴파일러가 코드를 컴파일할 때 함수 정의의 copy로 replace해준다. 긴 함수를 인라인으로 정의하면 컴파일된 코드의 크기가 커질 수 있다.
inline int min(int x, int y)
{
return x > y ? y : x;
}
C++
복사
현대 컴파일러는 최적화 성능이 뛰어나서 자동으로 함수를 인라인화하기 때문에 대부분의 경우 inline키워드를 사용할 필요는 없다.
nullptr
nullptr은 c++ 11에서 추가되었다. 포인터 값을 초기화하기 위한 상수로 사용되며 가리키는 대상이 없거나 사라졌을 때 사용한다. NULL은 매크로에 의해 정의된 상수로 0으로 replace된다. NULL과 달리 nullptr은 포인터이다.
void func(int n);
void func(char *s);
func( NULL ); // guess which function gets called?
//NULL이 0으로 대채되기 때문에 첫번째 함수가 호출된다.
C++
복사
Dynamic Casting
•
런타임에 객체의 타입을 변경하는 연산자.
•
dynamic_cast는 변환하려는 타입이 실제 객체의 타입과 일치하는지 확인하고 일치하지 않으면 nullptr를 반환한다.
•
반드시 가상함수가 있는(다형성을 가진) 클래스의 포인터나 참조에 대해서만 사용해야 RTTI(런타임 타입 정보)를 사용할 수 있다.
•
dynamic cast는 기본 자료형에 대한 형 변환이 불가능하다.
•
상속구조에서 부모 클래스의 포인터를 자식 클래스의 포인터로 변환할 때 주로 사용한다. (다운캐스팅 - 자식 클래스 객체를 부모 클래스 포인터로 가리키기 위함.)
class Base {
public:
virtual ~Base() {} // 가상 소멸자
};
class Derived : public Base {
};
void example(Base* basePtr) {
Derived* derivedPtr = dynamic_cast<Derived*>(basePtr);
if (derivedPtr) {
// derivedPtr를 안전하게 사용할 수 있음
} else {
// basePtr가 Derived 타입이 아님
}
}
C++
복사
•
자식 클래스의 참조나 포인터를 부모 클래스의 참조나 포인터로 변환하는것을 업캐스팅이라고 한다. 업캐스팅은 안전하고 컴파일러에 의해 자동으로 처리되기 때문에 명시적 타입변환이 필요없다.
•
부모 클래스의 참조나 포인터를 자식클래스의 참조나 포인터로 변환하는것을 다운캐스팅이라고 한다. 다운캐스팅은 여러 개의 자식 클래스가 존재할 수 있어서 안전하지 않을 수 있기 때문에 dynamic_cast를 사용해서 안전성을 확보한다.
copy constructor
복사 생성자는 같은 클래스의 다른 객체를 사용해서 새로운 객체를 초기화하는 특수한 생성자이다.
ClassName( const ClassName& other);
ClassName( const ClassName& other) = delete; //복사금지
C++
복사
복사 생성자를 정의하지 않아도 컴파일러가 자동으로 기본 복자 생성자를 생성함. 멤버변수를 단순히 복제하는 방식으로 동작한다.
= delete를 사용하면 복사 생성자를 삭제해서 해당 클래스 객체를 복사할 수 없게 만들 수 있다.
복사생성자를 통해서 깊은 복사와 같은 사용자 정의 복사 로직을 구현할 수 있다.
Unary Operator/Casting overloading
단항 증감 연산자를 오버로딩할때, operator++()는 전위 증가를 구현하고 operator++(int)는 후위 증가를 구현한다.
const Rational& operator++() {
numerator += denominator; // 분자에 분모를 더함
return *this; // 증가된 객체를 반환
}
C++
복사
const Rational &operator++(int) {
const Rational save(*this); // 현재 상태를 복사
numerator += denominator; // 분자에 분모를 더함
return save; // 복사한 상태를 반환
}
C++
복사
캐스팅 연산자는 각 타입별로 구현한다.
operator double() const {
return (double)numerator / denominator;
// 분자/분모를 실수계산으로 바꿔 반환
}
int main() {
Rational r(3, 4); // 3/4
// Rational 객체를 double로 변환
double value = r; // 형 변환 연산자를 사용
std::cout << "Rational as double: " << value << std::endl; // 출력: 0.75
// 증가 연산자 사용
++r; // r을 3/4에서 7/4로 증가
std::cout << "After increment: " << (double)r << std::endl; // 출력: 1.75
return 0;
}
C++
복사
Lvalue, Rvalue

C++에서 모든 변수와 값은 객체로 간주된다.
int, float, char 등 기본 데이터 타입도 객체의 특성을 가진다.
기본타입은 메소드를 가지지 않는다.
연산의 결과는 일반적으로 임시객체로 생성되고, 표현식의 결과값과 타입정보를 메모리에 저장하지만 이름이 없기때문에 다시 참조되지 않고 소멸된 것으로 간주한다.
변수를 선언하면 컴파일러가 메모리 공간을 할당하고 변수 이름과 메모리 주소를 연결한다. 초기화하면 해당 메모리 공간에 값을 저장한다. 변수 이름을 읽거나 메모리 공간에 접근하면 컴파일러가 연결된 주소를 통해 값을 읽거나 수정한다.
•
Lvalue: 이름이 있는 객체. 표현식이 끝난 뒤에도 존재하는 값이다. 변수, 포인터 등.
•
Rvalue: 일시적인 값으로, 표현식이 끝나면 더이상 존재하지 않는 값. 상수 리터럴, 임시객체. Rvalue 참조를 사용하지 않으면 임시객체의 주소를 참조할 수 없고, 객체에 접근할 수 있는 방법이 없다
•
non const reference로는 Lvalue만 참조할 수 있다. 즉, 이름이 있는 객체만 참조할 수 있다. 하지만 const를 사용해서 참조하면 Lvalue와 Rvalue=임시객체를 모두 참조할 수 있다.
•
함수의 인자로도 Rvalue(계산식 등)을 넘길 수 없으나 const를 사용하면 Rvalue를 받을 수 있다.
•
C++ 11에서 도입된 기능으로 &&를 통해 Rvalue를 참조할 수 있다. Rvalue를 참조하면 임시객체를 생성하지 않고 데이터를 효율적으로 관리할 수 있고 이동연산을 수행할 수 있다.
•
const int& r = x + 3; 과 같이 const를 사용해 작성하면 Rvalue를 참조할 수 있지만 x + 3의 결과로 임시객체가 생성되고 임시객체의 값이 r에 복사된다.
하지만 int&& r = x + 3;을 사용해서 메모리 주소를 저장하면 임시객체를 직접 참조할 수 있어 불필요한 객체 생성을 피할 수 있다. 임시객체를 생성하지 않으면 메모리 할당과 해제시간이 줄어들고 메모리 사용량도 줄어든다.
x + 2 = y; // Illegal!
int x = 5;
int& r = x + 3; // Illegal!
int&& r = x + 3; // Legal, 임시객체의 메모리 주소 저장
int x = 5;
const int& cr = x + 3; // Legal
int g(int& n) {
return 10 * n;
}
std::cout << g(x + 2) << '\n'; // Illegal!
int h(const int& n) {
return 10 * n;
}
std::cout << h(x + 2) << '\n'; // Legal
C++
복사
이동연산, 복사연산
이동연산이란 기존 객체의 자원을 새로운 객체로 이동시키는것이다.
이동연산을 통해 한 객체가 가지고 있는 자원을 다른 객체에 이전한다.
예를 들어 동적 메모리 할당받은 배열을 가진 객체가 다른 객체로 소유권을 이전할 수 있다.
객체를 할당할 때 이동연산이 일어나지 않는 경우 복사연산이 수행된다.
복사 생성자와 복사할당연산자를 통해 새로운 메모리 공간이 할당되고 기존 객체의 데이터를 복사한다. 따라서 두 객체는 서로 다른 메모리 공간에 각자의 데이터가 존재하게 된다. 큰 데이터 구조나 동적 메모리를 사용할 때 복사가 수행되면 비용이 증가한다.
std::move
std::move는 주어진 Lvalue를 Rvalue로 변환해서 해당 객체의 자원을 다른 객체로 이동할 수 있도록 한다.
int&& r = std::move(x)
C++
복사
std::move를 사용하면 데이터 복사가 아닌 자원의 소유권을 이전할 수 있으므로 성능이 향상된다. Lvalue는 이름이 있는 객체로 메모리에 지속적으로 존재하므로 자원의 소유권을 이전할 수 없다.
Move Constructor, Move Assignment Operator
class A {
A(A&& other);
a& operator=(A&& other);
};
C++
복사
Move constructor는 rvalue참조를 매개변수로 받아 다른 객체의 자원을 이동한다. default로 생성된다.
Move Assignment Operator는 rvalue참조를 사용해서 객체의 자원을 다른 객체로 이동한다.
className(className &&) = delete;
className &operator=(className &&) = delete;
C++
복사
이동 생성자와 이동 할당 연산자를 사용할 수 없게 제한 할 수 있다.
Smart Pointers
메모리 관리를 자동으로 해주는 객체. 메모리 누수를 방지하고 포인터 사용의 안전성을 높일 수 있다. shared_ptr, unique_ptr, weak_ptr가 있다. 스마트 포인터는 연산자가 오버로딩 된 포인터의 wrapper class이다.
reset()을 통해 스마트 포인터가 현재 소유하고 있는 객체를 해제하고 다른 객체를 소유하도록 설정할 수 있다. 인수를 제공하지 않으면 nullptr가 된다.
•
shared_ptr
여러개의 shared_ptr가 같은 객체를 공유할 수 있다. 객체의 참조 카운트가 관리되며 reset()으로 객체를 가리키는 마지막 shared_ptr가 소멸될 때 객체가 메모리에서 해제된다.
use_count를 통해 shared_ptr가 현재 공유하고 있는 객체의 참조 카운트를 반환한다.
#include <iostream>
#include <memory>
struct Widget {
int data;
Widget(int n) : data(n) {}
~Widget() { std::cout << "Destroying: " << data << std::endl; }
};
int main() {
std::shared_ptr<Widget> p11(new Widget(11));
std::shared_ptr<Widget> p12 = std::make_shared<Widget>(12);
auto p13 = std::make_shared<Widget>(13);
std::shared_ptr<Widget> p14 = p12;
std::cout << p11.use_count() << std::endl; // 1
std::cout << p12.use_count() << std::endl; // 2
p11.reset(); // p11 = nullptr; // Destroying: 11
p12.reset();
p14.reset(); // Destroying: 12
//지역변수 설정. 스코프 벗어나면 소멸됨.
{ std::shared_ptr<Widget> p15 = std::make_shared<Widget>(15); }
std::cout << (bool)p11 << std::endl; // 0 (nullptr이기 때문)
std::cout << (bool)p12 << std::endl; // 0
std::cout << (bool)p13 << std::endl; // 1
std::cout << (bool)p14 << std::endl; // 0
}
C++
복사
•
unique_ptr
객체의 소유권을 독점한다. 다른 unique_ptr로 복사할 수 없고, 소유권을 이전하기 위해서는 std::move를 사용해야한다. 하나만 존재하기 때문에 reset() 메서드를 호출하면 소유하던 객체가 소멸되고 포인터는 nullptr로 설정된다.
release를 통해서 소유하던 객체의 포인터를 반환하고 nullptr로 변경되도록 한다.
std::move를 통해서 소유권을 이전한 이후에도 nullptr가 된다.
int main() {
std::unique_ptr<Widget> p21(new Widget(21));
std::unique_ptr<Widget> p22(new Widget(22));
std::unique_ptr<Widget> p23 = std::make_unique<Widget>(23);
p21.reset(); // Widget(21) 소멸
Widget *p02 = p22.release();
std::cout << (bool)p21 << std::endl; //false
std::cout << (bool)p22 << std::endl; //false
std::cout << (bool)p23 << std::endl; //true
delete p02; // 22 소멸
std::unique_ptr<Widget> p24 = std::move(p23);
std::cout << (bool)p23 << std::endl; // 0
std::cout << (bool)p24 << std::endl; // 1
std::cout << "Pointers" << std::endl;
Widget *p = new Widget(0); // unique_ptr를 사용하지 않으므로 메모리 누수 발생 가능
} // Destroyed Widget(23)
C++
복사
•
weak_ptr
shared_ptr의 보조 포인터로 객체의 소유권을 갖지 않고, 객체가 소멸될때 weak_ptr는 nullptr로 변경되지 않는다.
순환 참조(circular reference)문제를 해결하기 위해서 사용된다. 순환참조 문제란 두 개 이상의 객체가 서로를 shared_ptr로 참조하면 서로의 참조 카운트가 0이 되지 않아 메모리 누수가 발생하는 문제이다.
std::shared_ptr<MyClass> ptr1 = std::make_shared<MyClass>();
std::weak_ptr<MyClass> wptr = ptr1; // ptr1을 공유하지 않음
C++
복사
순환 참조 문제
#include <iostream>
#include <memory>
class A;
class B {
public:
std::shared_ptr<A> aPtr; // A 객체에 대한 shared_ptr
~B() { std::cout << "B 소멸됨\n"; }
};
class A {
public:
std::shared_ptr<B> bPtr; // B 객체에 대한 shared_ptr
~A() { std::cout << "A 소멸됨\n"; }
};
int main() {
{
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
a->bPtr = b; // A가 B를 참조
b->aPtr = a; // B가 A를 참조
} // 여기서 a와 b는 범위를 벗어나지만, 서로를 참조하므로 두 객체의 참조 카운트는 0이 되지 않고
// 따라서 메모리 해제가 이루어지지 않음
// "A 소멸됨" 또는 "B 소멸됨"이 출력되지 않음
return 0;
}
// ------------fix--------------
{
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
a->bPtr = b; // A가 B를 참조
b->aPtr = a; // B가 A를 weak_ptr로 참조
// A는 B를 소유하고, B는 A를 약한 참조로 가리킴
} // 이제 A와 B가 모두 소멸됨
C++
복사
Template
•
C++ 템플릿은 제너릭 프로그래밍을 지원하는 기능이다.
•
제너릭 프로그래밍은 특정 데이터타입에 제한되지 않고 다양한 타입을 처리할 수 있도록 알고리즘을 설계하는 패러다임이다. 코드의 재사용성과 유연성을 높일 수 있다.
•
탬플릿은 함수 탬플릿과 클래스 탬플릿으로 나뉜다.
Function Template
#include <iostream>
#include <string>
// 파라미터 타입에 따라 함수 별도 구현?
// bool equal(int a, int b) {
// return a == b;
// }
// bool equal(std::string a, std::string b) {
// return a == b;
// }
template <class T>
bool equal(T a, T b) {
return a == b;
}
int main() {
std::cout << equal(2, 3) << '\n';
std::cout << equal(2.2, 2.7) << '\n';
std::cout << equal("abc", "abcd") << '\n';
}
C++
복사
T는 제너릭 타입으로 함수가 호출될 때 실제 타입으로 대체된다.
Class Template
template <class T>
T *new_var(int size) {
return new T[size];
}
int main() {
int *p1 = new_var<int>(10);
double *p2 = new_var<double>(10);
}
C++
복사
template <typename T>
class Point {
public:
T x;
T y;
Point(T x, T y) : x(x), y(y) {}
void Print();
};
template <typename T>
void Point<T>::Print() {
std::cout << x << "," << y << std::endl;
}
int main() {
Point<int> p1(10, 10);
Point<double> p2(10.5, 20.2);
p1.Print();
p2.Print();
}
C++
복사
Template Parameters
템플릿의 인자로 타입과 상수값을 전달할 수 있다.
#include <iostream>
template <int N>
int scale(int value) {
return value * N;
}
template <typename T, int N>
T scale(const T& value) {
return value * N;
}
int main() {
std::cout << scale<3>(5) << '\n';
std::cout << scale<4>(10) << '\n';
std::cout << scale<double, 3>(5.3) << '\n';
std::cout << scale<int, 4>(10) << '\n';
}
C++
복사
Template Specialization
<>로 특정 타입에 대해 다르게 동작하도록 템플릿을 특수화할 수 있다.
template <class T>
T* new_var(int size) {
return new T[size];
}
template <>
int* new_var<int>(int size) {
std::cout << "Specialized for int type" << std::endl;
return new int[size]; // int 타입에 대한 특별한 처리
}
int main() {
int* p1 = new_var<int>(10); // 특수화된 버전 호출
double* p2 = new_var<double>(10); // 기본 템플릿 호출
delete[] p1; // 메모리 해제
delete[] p2; // 메모리 해제
}
C++
복사
예시) template을 사용한 클래스 Vector를 만들고 std::ostream의 << operator를 오버로딩해서 Vector<T>타입을 인자로 받는 경우의 출력 결과를 구현한 예.
#include <iostream>
template <typename T> class Vector {
public:
T x, y;
Vector(T x = 0, T y = 0) : x(x), y(y) {}
};
template <typename T>
std::ostream &operator<<(std::ostream &os, const Vector<T> &v) {
os << v.x << ", " << v.y;
return os;
}
std::ostream &operator<<(std::ostream &os, const Vector<char> &v) {
os << static_cast<int>(v.x) << ", " << static_cast<int>(v.y);
return os;
}
int main() {
Vector<int> v1(1234, 32644);
Vector<char> v2(121, 22);
Vector<double> v3(1.32, 2.234);
std::cout << v1 << std::endl;
std::cout << v2 << std::endl;
std::cout << v3 << std::endl;
}
C++
복사
STL (Standard Template Library)
C++ 표준 라이브러리의 일부로, std namespace안에 포함되어있으며 다양한 데이터 구조와 알고리즘을 제공한다.
컨테이너(Container)
•
정의: 여러 데이터를 저장할 수 있는 클래스, 자료구조, ADT(Abstract Data Type).
•
종류
◦
순차 컨테이너(Sequence Container): 데이터에 순차적으로 접근 가능.
▪
예: std::vector, std::array, std::list, std::deque
◦
연관 컨테이너(Associative Container): 키-값 쌍으로 데이터를 저장.
▪
예: std::set, std::map, std::multiset, std::multimap
◦
정렬되지 않은 연관 컨테이너(Unordered Associative Container): 해시 테이블 기반으로 데이터 저장.
▪
예: std::unordered_set, std::unordered_map
컨테이너 어댑터(Container Adapter)
•
정의: 다른 순차 데이터들을 처리하기 위한 인터페이스를 제공.
•
종류:
◦
큐(Queue): FIFO 방식.
◦
스택(Stack): LIFO 방식.
◦
우선순위 큐(Priority Queue): 요소의 우선순위에 따라 정렬.
이터레이터(Iterator)
컨테이너의 요소를 순회하기 위한 객체로, 포인터와 유사한 역할을 한다.
다른 타입의 컨테이너들은 각각 고유한 이터레이터를 제공한다.
ex)vec.begin() 메소드는 벡터의 첫번째 요소를 가리키는 iterator를 반환하고, vec.end() 메소드는 벡터의 마지막 요소 다음 위치를 가리키는 iterator를 반환한다.
이터레이터는 증감연산자 오버로딩이 되어 있어 ++, —로 요소를 순회할 수 있다.
//vector타입의 iterator it선언
for (std::vector<int>::iterator it = vec.begin(); it != vec.end(); ++it) {
std::cout << *it << " ";
}
std::vector<int>::reverse_iterator iter = v.rbegin();
C++
복사
iterator를 dereferencing(*)해서 요소에 접근할 수 있다.
reverse iterator를 통해서 ++,—가 반대로 동작하는 iterator를 사용할 수 있다.
std::remove함수는 컨테이너에서 특정 값을 제거하는 역할을 하는데, 실제로
제거하는것이 아니라 remove에 해당하지 않는 요소들을 앞으로 모아주는 기능을 수행한다.
erase함수는 첫번째 인자로 받은 위치부터 두번째 인자로 받은 위치까지의 원소를 제거한다.
v1.erase(v1.begin(), v1.end());
std::remove(v2.begin(), v2.end(), 0);
C++
복사
remove는 v2에서 값이 0인 원소들을 컨테이너의 끝으로 이동시키고,그 첫번째 위치를 반환한다.
#include <algorithm>
#include <iostream>
#include <list>
#include <vector>
template <class container> void Print(container c) {
for (auto iter = c.begin(); iter != c.end(); iter++)
std::cout << *iter << ", ";
std::cout << std::endl;
}
int main() {
std::vector<int> v1{10, 20, 30, 40, 50};
Print(v1);
v1.erase(v1.begin() + 3);
Print(v1);
v1.erase(v1.begin() + 2, v1.end());
Print(v1);
std::cout << std::endl;
std::vector<int> v2{10, 0, 30, 0, 50};
Print(v2);
auto remove_start = std::remove(v2.begin(), v2.end(), 0);
Print(v2);
v2.erase(remove_start, v2.end());
Print(v2);
std::cout << std::endl;
std::vector<int> v3{10, 0, 30, 0, 50};
Print(v3);
v3.erase(std::remove(v3.begin(), v3.end(), 0), v3.end());
Print(v3);
std::cout << std::endl;
std::vector<int> l{10, 0, 30, 0, 50};
Print(l);
l.erase(std::remove(l.begin(), l.end(), 0), l.end());
Print(l);
}
C++
복사
이터레이터를 사용하는 다양한 STL의 함수가 존재함.
ex) std::copy, std::count, std::find
//하나의 이터레이터 범위에서 다른 범위로 데이터를 복사
std::copy(source_begin, source_end, destination_begin);
//주어진 범위에서 특정 요소를 찾아서 그 이터레이터를 반환
//찾지 못하면 범위의 끝을 반환.
auto it = std::find(container.begin(), container.end(), value);
//주어진 범위에서 특정 요소의 개수를 세서 반환
auto count = std::count(container.begin(), container.end(), value);
C++
복사
Namespace
이름 충돌을 방지하기 위해서 만들어진 개념.
namespace의 멤버에 접근하기 위해서 :: (scope resolution operator)를 사용함.
네임스페이스를 사용하면 이름 충돌을 방지하고 관련된 코드를 그룹화해서 가독성을 높일 수 있다.
namespace는 중첩되어 사용될 수 있다.
namespace Outer {
int value = 42;
namespace Inner {
void function() {
std::cout << "Inner function" << std::endl;
}
}
}
//Outer::value
//Outer::inner::function()
C++
복사
scope resolution operator를 사용하지 않고 using을 사용해서 namespace의 멤버를 간편하게 사용할 수 있지만 이름 충돌이 발생할 가능성이 커진다.
Lambda Function
일회성으로 사용할 수 있는 익명 함수
//형태
[caputerlist](parameters) -> returnType {}
//capturelist = 외부 변수를 람다 함수 내에서 사용할 수 있도록 함.
//return Type은 생략하면 컴파일러가 자동으로 추론함.
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
std::for_each(numbers.begin(), numbers.end(), [](int n) {
std::cout << n << " ";
});
// 특정 조건을 만족하는 요소의 개수 세기
int count = std::count_if(numbers.begin(), numbers.end(), [](int n) {
return n > 3;
});
std::cout << "\nCount of numbers greater than 3: " << count << std::endl;
return 0;
}
JavaScript
복사
FileSystem
std::filesystem네임스페이스 안에 포함되어있으며 파일시스템을 다루는 기능을 제공하는 표준 라이브러리의 일부이다. C++17이상을 지원하는 컴파일러를 사용해야한다.
파일 및 디렉토리 작업
•
파일 및 디렉토리 생성, 삭제, 이름 변경 등의 작업을 수행할 수 있음.
std::filesystem::create_directory, std::filesystem::remove,
std::filesystem::rename
파일 및 디렉토리 탐색
•
디렉토리 내의 파일 목록을 가져오거나, 재귀적으로 서브디렉토리 탐색이 가능함.
std::filesystem::directory_iterator,
파일 경로 처리
•
파일 경로를 쉽게 다룰 수 있도록 std::filesystem::path 클래스를 제공함.
path::filename, path::parent_path
파일 속성 조회
•
파일의 크기, 권한 등의 정보를 조회할 수 있음.
std::filesystem::file_size, std::filesystem::status
#include <iostream>
#include <filesystem>
namespace fs = std::filesystem;
int main() {
// 현재 경로 출력
fs::path current_path = fs::current_path();
std::cout << "현재 경로: " << current_path << std::endl;
// 새로운 디렉토리 생성
fs::path new_dir = current_path / "새로운_디렉토리";
if (fs::create_directory(new_dir)) {
std::cout << "디렉토리 생성됨: " << new_dir << std::endl;
} else {
std::cout << "디렉토리 생성 실패 또는 이미 존재함." << std::endl;
}
// 디렉토리 내 파일 목록 출력
for (const auto& entry : fs::directory_iterator(current_path)) {
std::cout << entry.path() << std::endl;
}
return 0;
}
C++
복사
std::exception
예외 처리를 위한 베이스 클래스. 모든 exception은 std::exception은 상속받아 구현된다.
ex)std::length_error
std::exception은 virtual function what()을 가지고 있으므로 상속받는 예외 클래스에서 what()을 재정의하여 구현한다.
#include <iostream>
#include <exception>
class MyException : public std::exception {
public:
const char* what() const noexcept override {
return "Something went wrong!";
}
};
void mayThrowException() {
throw MyException();
}
int main() {
try {
mayThrowException();
} catch (const std::exception& e) {
std::cout << "caught an exception: " << e.what()
<< std::endl;
}
return 0;
}
JavaScript
복사
