스레드 개념
프로세스 문제점
1.
Heavy-weight: 프로세스는 주소 공간, PCB 등을 저장해야 하기 때문에 커널이 해야 하는 일이 많아지고 메모리를 많이 차지한다. 또한 IPC를 할 때 커널의 개입이 필요해서 성능이 떨어진다. 이러한 문제를 해결하기 위해 선 마이크로소프트의 Lightweight Process (LWP)가 개발되었다. 프로세스를 실행 상태(주소 공간, PC, SP 등)와 분리한다.
POSIX 표준화 과정을 거쳐서 만들어진 것이 스레드이다. 프로세스를 따로 만들지 않고 하나의 프로세스 안에서 여러 개의 path로 동작하게 한다. 스레드라고 불리는 이유는 path를 실처럼 표현하기 때문이다.
멀티스레드
1.
스레드 생성: 싱글 스레드는 함수1 수행 후 함수2를 수행하는 순차적인 형식이다. 멀티스레드는 스레드를 함수 단위로 구현한다. 함수1, 함수2를 pthread_create()와 같은 시스템 콜의 인자로 넘겨줘서 스레드를 생성해서 병렬적으로 동작하는 것처럼 구현한다. 2개의 함수의 스레드를 만들면 메인 스레드를 포함해서 3개의 스레드가 존재하는 것이다. 보통 멀티스레드 환경에서는 스레드로 만들 함수들을 무한 루프로 구현한다. pthread는 POSIX 표준을 따르는 스레드와 관련된 라이브러리이다. pthread_create, pthread_exit, pthread_join 등의 함수가 존재한다. join은 멀티프로세스에서 동기화를 위해 사용한 wait과 동일하다.
2.
차이점: 코드 세그먼트와 데이터 세그먼트, 파일 I/O는 스레드끼리 공유해서 사용하지만, 특정 함수를 스레드로 만드는 것이므로 스레드별로 다른 데이터를 관리하기 위해서 스택을 따로 가지고 있다. 코드 섹션은 공유하지만 수행되어야 하는 instruction의 위치가 다르기 때문에 레지스터 값과 스택 포인터의 값도 스레드별로 다르다. 즉, 스레드마다 레지스터 정보와 스택 영역은 독립적이다.
3.
주소 공간: 코드 세그먼트, 데이터 세그먼트, 힙은 공유하고 스택 위에서부터 스레드가 쌓인다. 스레드 사이에는 가드 영역이 존재하고 운영체제가 그 크기를 지정한다. 각각의 스레드가 수행되다가 멈췄을 때의 context를 스택이나 커널 단에 저장해서 관리한다.
•
예시:
◦
웹서버: 멀티 프로세스에서는 fork로 새 프로세스를 생성해서 request를 처리했으나 단순한 작업을 위해서는 overkill이다. 자식 프로세스에서 하던 작업을 함수로 만들고 request가 올 때마다 스레드를 새로 생성해서 request를 처리하도록 하면 동일하게 동작한다. 멀티 프로세스에서는 부모 프로세스가 소켓 연결을 끊고 다시 request를 기다리는데, 스레드에서는 한 프로세스 내에서 소켓을 유지해야 하므로 처리가 끝났을 때 소켓을 닫는다. 멀티 프로세스를 이용하는 예시로는 리눅스 아파치가 있다. 윈도우는 IIS라는 웹서버가 채택되어 있는데 스레드 개념이 나온 이후의 운영체제이기 때문에 유닉스와 달리 프로세스 간 부모-자식 개념이 없어서 멀티 프로세스로 구현되어 있지 않다.
◦
아두이노: 임베디드 장치는 제약된 하드웨어 리소스를 가진다. 운영체제도 RTOS(Real-Time OS)이며 크기가 작고 멀티 프로세스를 감당하지 못하기 때문에 멀티 스레드를 사용하는 것이 좋고 아두이노 라이브러리에서 스레드 함수를 제공한다. 사용할 수 있다. 예를 들어 LED를 깜빡이면서 버저를 울리게 만들기 위해서는 두 개의 스레드가 필요하다. 아두이노는 main에서 setup 함수를 한 번 수행하고 loop 함수를 반복 수행한다. 멀티태스크 작업할 때는 보통 루프를 비워놓는다. xTaskCreate 함수를 통해서 Task를 인자로 주고 스레드를 생성하면 동시에 동작하는 것처럼 수행된다.

4.
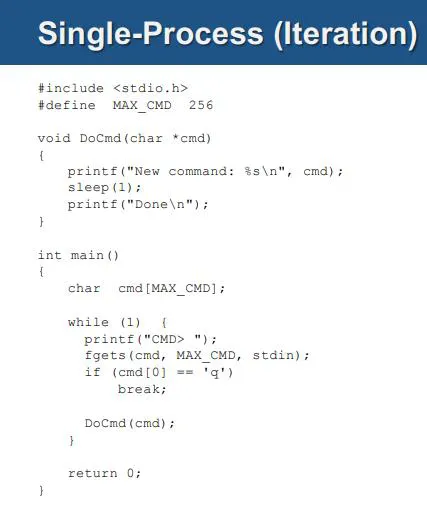
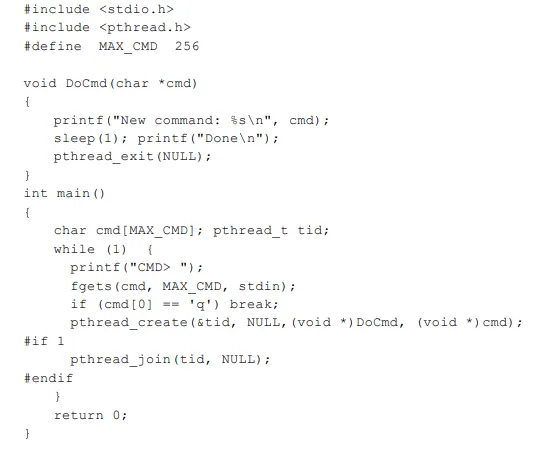
싱글 프로세스/멀티 프로세스/멀티 스레드 비교: DoCmd 함수를 수행하는 형태를 비교한다.
•
싱글 프로세스에서는 DoCmd 함수를 수행하면 함수 수행이 끝날 때까지 다음 작업을 수행할 수 없다.
•
멀티 프로세스 버전에서는 fork하면 새로운 프로세스가 생성되고 부모는 wait을 통해서 기다리다가 자식이 exit을 수행하면 시그널을 받아서 wait 상태에서 빠져나오고 다시 while 루프가 수행된다.
•
스레드 버전에서는 POSIX 표준 스레드 라이브러리인 pthread를 이용한다. pthread_t는 프로세스에서 PCB와 같은 역할을 수행하는 스레드 정보를 저장할 수 있는 구조체이다. 구조체를 pthread_create의 첫 번째 인자로 전달하고 두 번째 인자는 스레드의 Attribute를 설정하는 것인데 null로 하면 디폴트 상태로 생성된다. 세 번째 인자로 스레드 형태로 수행할 함수를 void 포인터 형태로 넣어주고, 네 번째는 함수를 수행하기 위한 파라미터이다. 파라미터는 포인터 변수여야 하고 하나만 전달 가능하기 때문에 구조체를 많이 사용한다.
•
조건부 컴파일: #if 조건이 0이면 #endif까지의 코드를 수행하지 않고 1이면 수행하도록 conditional compilation 한다. 디버깅할 때 많이 쓰는 기능으로 주석을 추가했다가 삭제할 필요 없이 디버그 모드는 1, 릴리즈 모드는 0으로 처리한다.

Multicore Programming
1.
개념: 여러 개의 코어에서 병렬적으로 연산을 처리한다. 싱글 코어일 때는 테스크가 여러 개일 때 타임쉐어링으로 동작해도 순차적으로 동작하는 것과 같다. 멀티코어의 경우에는 하드웨어 상의존성이 없는 테스크를 병렬적으로 수행해서 효율을 올린다. Parallelism에는 두 가지 종류가 있다.
•
Task Parallelism: 전체 데이터는 공유하고 테스크만 나눠서 동작한다. pthread 라이브러리가 해당한다.
•
Data Parallelism: 딥러닝과 같은 각각의 독립적인 요소에 대한 데이터 연산이 필요할 때, 의존성은 없고 데이터만 다르면 될 경우 데이터별로 나눠서 병렬적으로 수행한다. 이미지 필터링의 경우 데이터를 조각으로 나눠서 병렬적으로 연산을 수행하고 나중에 합쳐서 결과를 만들어낸다. NUMA 시스템 같은 기상청 슈퍼컴퓨터에 많이 사용된다. GPGPU, CUDA, OpenCL 등의 라이브러리가 있다.
스레드의 형태
구현 방식
1.
유저 스레드: 한 프로세스에서 여러 개의 path가 존재하도록 하려면 커널을 수정하는 방식과 어플리케이션 단에서 동작하도록 하는 방식이 있다. 유저 스레드는 라이브러리 형태로 스레드가 어플리케이션 단에서 동작하도록 구현한 것이다. 프로세스 안에 런타임 시스템을 만들고 스레드를 관리한다. 프로세스에서 어떤 스레드가 동작하고 있는지 테이블을 통해서 관리하고 런타임 시스템이 스케줄링한다. 커널은 스레드에 대한 정보가 없다. 커널의 오버헤드가 줄어드는 장점이 있다. 하지만 유저 스레드 방식은 큰 문제가 있다. 여러 개의 스레드가 동작하고 있는데 첫 번째로 런타임에 의해 선정된 스레드가 blocking I/O 요청을 한다면 다른 스레드는 수행되지 못하고 CPU에서 내려와야 한다. OS에게 스레드에 대한 정보가 없기 때문에 발생하는 문제이다.
2.
커널 스레드: 커널에서 프로세스와 스레드 테이블을 만들어서 관리하는 형식이다. 커널 스레드 형식이 현재 많이 사용되는 형식이다. 스레드 스케줄링 등을 훨씬 최적화해서 운영할 수 있다. 오버헤드가 많지만 하드웨어가 발전하면서 많이 사용하게 되었다.
멀티스레딩 모델
1.
Many-to-One: 하나의 커널 스레드에 여러 개의 유저 스레드.커널의 오버헤드를 줄이기 위해서 커널 스레드를 줄인 형식이다. 위의 유저 스레드 형식이 구현된 것이다.
•
One-to-One: 각 유저 스레드가 하나의 커널 스레드와 매핑되는 방식이다. 이 방식은 스레드마다 독립적인 커널 스레드가 존재하여 스케줄링과 관리를 최적화할 수 있다. 그러나 이 경우 스레드 개수가 많아지면 커널의 오버헤드가 증가할 수 있다.
•
Many-to-Many: 여러 개의 유저 스레드가 여러 개의 커널 스레드와 매핑되는 방식이다. 이 모델은 유연성과 효율성을 제공하며, 시스템 자원의 활용도를 높일 수 있다. 여러 개의 유저 스레드가 여러 개의 커널 스레드에서 병렬로 실행될 수 있다.
•
Two-level: Many-to-One과 One-to-One을 둘 다 사용하는 방식이다. 이 모델은 유저 스레드와 커널 스레드 간의 매핑을 조절하여 최적의 성능을 도모할 수 있다.
스레딩 이슈
•
두 가지 버전의 fork 문제: 멀티 프로세스와 멀티 스레드를 혼용할 때, 하나의 프로세스에서 5개의 스레드가 동작하고 있는데 5번 스레드에서 fork를 수행하는 경우, 두 가지 경우의 수가 존재한다. 하나는 스레드를 하나 더 만드는 방식이고, 하나는 프로세스를 그대로 복제하여 만드는 방식이다. 상황에 따라 어떤 방식이 좋은지가 다르다. 불문율로써 fork가 필요하면 fork를 먼저 하고 스레드를 만들기로 정해졌다.
•
스레드 데이터 접근: 스레드들 각각 따로 가지는 데이터를 다른 스레드에서 접근 가능하게 할 것인가? 그렇게 했을 때의 보안상 이슈는 무엇인가? 여러 스레드가 공유하는 데이터에 대해 동기화가 필요하다.
•
시그널 처리: 시그널을 프로세스 레벨에서 처리할 것인가, 스레드 레벨에서 처리할 것인가 등. 스레드가 여러 개일 때, 시그널을 어느 스레드가 처리할지에 대한 결정이 필요하다.
Pthreads (POSIX Threads)
•
스레드 생성/종료: pthread_create, pthread_exit, pthread_join 등의 함수를 사용하여 스레드를 생성하고 종료한다. pthread_join은 특정 스레드가 종료될 때까지 대기하는 데 사용된다.
•
Mutex 함수: 멀티 스레드가 동작할 때 프로세스 안에서 공유하는 자원들에 접근할 때 생기는 데이터 왜곡 및 동기화 문제를 해결하는 방법이다. Mutex는 상호 배제를 통해 여러 스레드가 동시에 자원에 접근하지 못하게 하여 데이터의 일관성을 유지한다. 이 부분은 6장에서 자세히 기술할 예정이다.
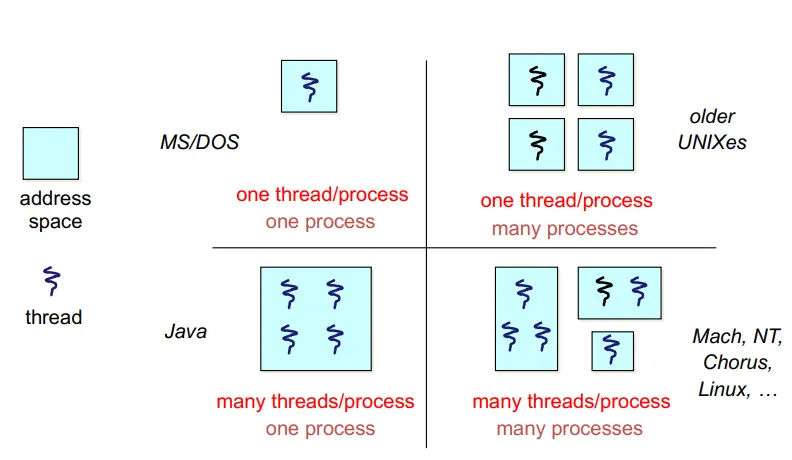
Thread Design Space
•
MS/DOS: Batch 시스템이므로 하나의 프로세스와 하나의 스레드를 가진다.
•
초기 유닉스: 하나의 프로세스 당 하나의 스레드가 존재했다. 프로세스는 여러 개 존재했다.
•
Java: 덩치가 큰 프로세스가 하나 올라가고 가상 머신이 실행시키는 프로그램이 스레드 형태로 동작한다. 하나의 프로세스에 여러 개의 스레드가 존재하는 형태이다.
•
현재의 Linux, Mach 등: 대부분의 OS는 여러 개의 프로세스에 여러 개의 스레드가 존재하는 형태이다.