
Mass Storage Structure
종류
1.
HDD: 하드 디스크 드라이브로, 플래터 위에 데이터를 저장하는 방식이다.
2.
SSD: 솔리드 스테이트 드라이브로, 플래시 메모리를 이용해 데이터를 저장하는 방식이다.
3.
RAM Disk: RAM을 이용하여 가상 디스크를 생성하여 사용하는 방식이다.
4.
Magnetic Tape: 자기 테이프를 이용하여 데이터를 저장하는 방식이다.
Disk Attachment
1.
Host Attached: I/O 포트를 이용해서 슬롯에 바로 디스크를 붙이는 방법이다. IDE와 SCSI가 존재한다.
•
IDE: 일반 PC에 사용하는 방식이다.
•
SCSI: 서버와 같은 신뢰성이 중요한 장치에 붙이는 규격이다.
2.
Network Attached: NAS, SAN이 있다.
•
NAS (Network-Attached Storage): 여러 개의 디스크를 넣을 수 있는 하드웨어를 네트워크에 연결시켜서 클라이언트가 네트워크를 통해 접근할 수 있도록 구현한 스토리지이다. NAS는 하나의 파일 시스템과 같이 동작하며 파일 레벨로 엑세스할 수 있다. 실제 컴퓨터에 붙어있는 스토리지처럼 사용하며 NFS, CIFS 등의 파일 시스템을 사용한다.
•
SAN (Storage Area Network): 스토리지를 연결한 네트워크로 NAS보다 큰 단위이다. 네트워크 자체가 하나의 스토리지이며 전용의 interconnection 네트워크를 사용한다. 대량의 데이터를 빠르게 처리해야 하는 데이터 센터 등에서 사용된다. Fiber Channel(광 채널)을 사용하고 블록 레벨로 데이터를 read/write한다. SAN 자체가 하나의 큰 파일 시스템이라고 생각할 수 있다. 예를 들어, 넷플릭스처럼 대량의 영상 데이터를 SAN으로 저장한다.
3.
분류: NON IP이면서 direct로 연결되는 IDE, SCSI가 있고 Fiber Channel로 연결된 SAN이 있다. 블록 단위로 동작해서 더 빠르지만 파일 시스템을 OS에서 서포트해줘야 한다. IP 네트워크에는 NAS가 있다. NAS는 별도의 파일 시스템이 존재해서 파일 단위로 접근 가능하다. 중소규모의 기업에서도 많이 구현해서 사용한다.
HDD
1.
플래터가 여러 장 존재하고 그 위에 데이터를 쓰는 영역인 트랙이 존재한다. 트랙에 데이터를 쓰는 최소 단위는 섹터이다. 실제 데이터를 읽는 부분이 헤더이며, 헤더와 연결된 부분이 암(Arm), 암을 움직이는 암 어셈블리 등으로 구성되어 있다. 플래터는 스핀들이라는 공용의 축을 통해서 돌아간다. HDD는 충격에 약하고 bad block이 잘 발생한다. 피지컬과 로지컬 영역을 나눠서 사용하는데, 디스크의 섹터 등은 low level로 피지컬 영역이고 filename, record 등 higher level로 abstraction해서 사용한다. 실린더, 트랙, 섹터 등의 정보를 가지고 데이터를 찾는 과정을 전부 OS가 처리하는 것은 옛날 방식이고 요즘은 디스크 컨트롤러에서 처리하며 OS의 오버헤드가 줄어들어 성능이 향상된다. HDD I/O에서는 Arm seek time이 성능에 가장 중요하다. Rotation, transfer 속도가 미치는 영향은 아주 적다. seek time을 최대한 줄이기 위한 disk scheduling 알고리즘이 존재한다.
2.
Disk Scheduling
•
FCFS (First-Come, First-Served): 들어온 순서대로 처리한다. 가장 fair하지만 성능이 안 좋다.
•
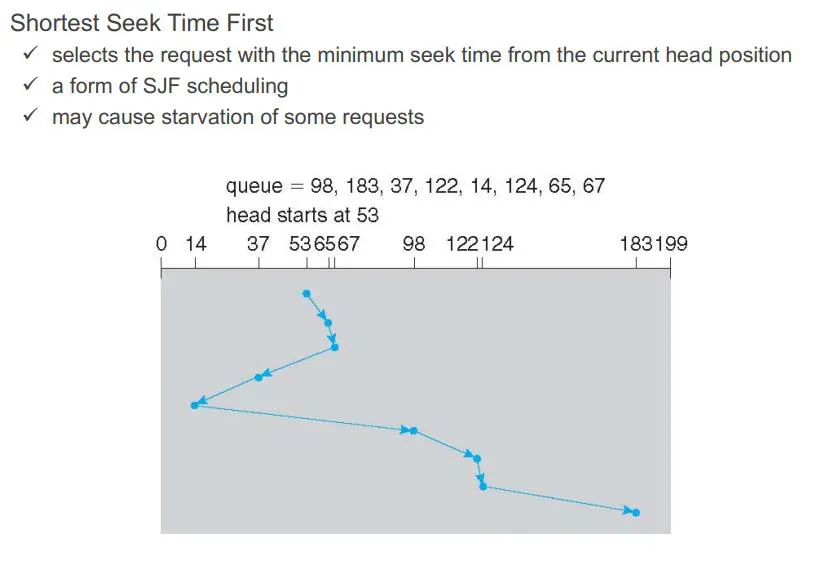
SSTF (Shortest Seek-Time First): SJF와 비슷하지만 그와 달리 예측이 가능하다. 제일 가까운 데이터 블록으로 arm을 움직인다. 큐가 고정되어 있으면 starvation이 발생하지 않지만 새로 계속 들어온다면 starvation이 발생한다. 실제로는 개량된 버전의 SSTF를 디스크에서 가장 많이 사용한다.
•
SCAN: 엘리베이터 알고리즘이라고도 하며, 한쪽 방향의 끝까지 갔다가 반대편의 끝까지 가는 방법이다. 이 방식은 waiting time이 길어질 수 있다.
•
C-SCAN: SCAN과 달리 waiting time이 균일하다. 한쪽 방향으로 끝까지 진행하고 암을 반대쪽 끝으로 초기화하는 방법이다.
•
C-LOOK: 끝까지 가는 것이 아니라 읽을 데이터가 존재하는 마지막 위치까지 이동하는 방법이다. C-SCAN을 개량한 방법이다.
Disk Controller 기능
1.
Read Ahead: spatial locality를 고려해서 회전하는 방향의 앞 부분도 미리 읽어서 메모리에 올려준다.
2.
Caching: 최근에 사용된 데이터를 캐시하여 성능을 향상시킨다.
3.
Request Reordering: 운영체제 요청 miss가 난 경우 요청을 최적화하여 처리한다.
4.
Bad Block Identification: 불량 블록을 식별하고 관리한다.
5.
Remapping: 불량 블록을 대체할 수 있는 블록으로 재매핑한다.
Swap-Space Management
1.
Virtual memory를 사용할 때 디스크 공간을 메모리의 extension으로 사용한다. 윈도우에서는 파일로 관리하며, C 드라이브의 남은 저장공간에서 메인 메모리의 2배 정도의 공간을 Swap-space로 사용한다. 그래서 디스크 용량이 90%를 넘어가는 경우 컴퓨터 동작이 느려지기도 한다. 컴퓨터가 느려지면 하드디스크에 있는 것을 지우라는 이유이다.
2.
Linux에서는 별도의 Disk partition을 나눠놓고 swap-space로 사용한다.
RAID
정의
1.
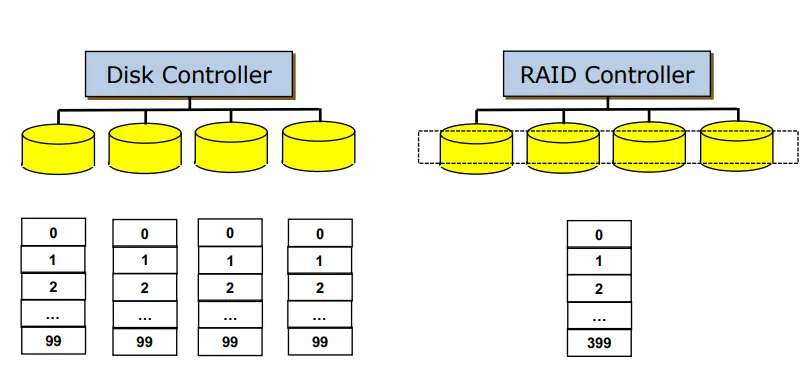
RAID: Redundant Array of Inexpensive Disks. 여러 개의 디스크를 사용해서 성능과 신뢰성을 높이는 방법이다. 가격이 싼 스토리지를 여러 개 묶어서 배열로 만든다. RAID로 묶으면 여러 개의 디스크가 아니라 하나의 큰 디스크로 인식하게 된다.
신뢰성
1.
Mirroring: 데이터의 완전한 복사본을 만들어 놓는다. 하나가 망가져도 복구할 수 있고 필요한 데이터에 접근할 수 있다.
2.
Parity: 패리티 비트나 error-correcting code 기법은 깨진 데이터를 복구하기 위한 코드를 저장해 둔다. 패리티 비트는 ECC보다 길이가 짧아서 용량이 작지만 복구 범위가 더 적다. 둘 다 복구하기 위해서는 연산이 필요해서 미러링보다는 연산 오버헤드가 크다. 미러링과 패리티 비트/ECC를 함께 사용해도 된다.
성능
1.
Data Striping: 성능을 향상시키기 위해 데이터를 나눠서 저장하고 불러올 때 병렬적으로 데이터를 메모리로 올리는 방법이다. 비트 레벨과 블록 레벨로 나뉜다.
•
비트 레벨: 하나의 디스크 블록을 비트 단위로 나눠서 저장하고 일부씩 읽어온다. 양쪽에 독립적으로 명령을 내려서 동시에 읽어올 수 있다.
•
블록 레벨: 특정 파일을 블록 단위로 나눠서 저장한다. 예를 들어, 넷플릭스에서 1개의 영상 데이터를 3개의 디스크에 3개의 블록으로 striping해놓고 일부분씩 가져온다면 병목이 발생하지 않고 로드도 분산시킬 수 있다. spatial locality 특성을 살리기 위해서는 블록 레벨이 좋다. 비트 레벨은 거의 사용되지 않는다.
RAID Levels
1.
RAID 0: 신뢰성은 고려하지 않고 블록 레벨의 data striping만 적용해서 성능을 향상시킨다.
2.
RAID 1: 미러링만 제공해서 신뢰성을 높인다. 디스크가 2배로 필요하다.
3.
RAID 2: 성능과 신뢰성을 모두 높인다. 미러링 대신 error correcting 코드를 사용한다. parallelism을 제공하기 위해서 비트 레벨로 data striping한다. ECC로 복구도 가능하고 성능도 향상되지만 비트 레벨 striping을 사용해서 잘 사용하지 않는다.
4.
RAID 3: ECC는 미러링과 용량에 큰 차이가 없어서 parity code만 적용한 버전이다. 여전히 비트 레벨 striping을 사용하지만 스토리지 오버헤드가 줄어들었다.
5.
RAID 4: 비트 레벨 striping을 블록 레벨로 바꿨고 패리티 비트를 사용한다.
6.
RAID 5: 패리티 정보를 striping한다. RAID 4는 한 디스크에 패리티 코드를 몰아놓아서 패리티를 만든 어떤 디스크에 write해도 패리티 비트를 다시 수정해야 하므로 write 작업이 몰린다. 성능에 bottleneck을 없애기 위해서 parity 비트를 분산해서 저장한다. 블록 레벨 striping과 패리티 striping을 적용했다.
7.
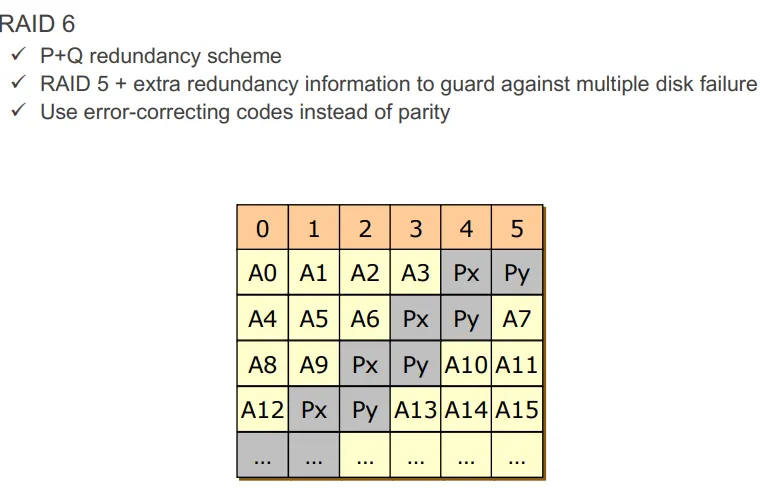
RAID 6: ECC를 사용하여 신뢰성을 더 높인다. 패리티 비트보다 디스크 용량이 2배 더 사용되어서 디스크 오버헤드가 크다. 하지만 어차피 디스크는 저렴하기 때문에 실제로 가장 많이 사용하는 방식이다. NAS에서 많이 사용한다.
7.
RAID 0+1: RAID0을 먼저 수행해서 블록레벨 데이터 striping을 적용하고 mirroring한다.
8.
RAID 1+0: RAID 1으로 미러링 한 이후에 블록레벨 data striping을 적용한다. 순서만 바뀌었지만 성능이 더 좋다. data striping이후 미러링 한 경우에는 디스크 중 하나가 망가졌을때 전체가 망가졌다고 인식해서 망가지지 않은 디스크도 접근할 수 없다. 하지만 미러링 후 data striping을 적용하면 별개의 레이드로 묶여있기 때문에 묶인 디스크 두개가 동시에 망가지지 않는 한 접근이 가능하다. 데이터센터 등에서 많이 사용한다.
