
Software Lifecycle
•
Problem Analysis: 문제를 정의하고 해결해야할 요소 식별
•
Requirements Elicitation: 사용자로부터 소프트웨어 요구사항 수집
•
Software Specification: 요구사항을 바탕으로 명세서를 작성해서 시스템 동작방식을 명확히 함
•
High, Low level design: high level에서는 시스템의 전체구조와 아키텍쳐를 정의하고 저수준에서서는 각 모듈의 세부적인 구현방법 정함.
•
Implementation: Design단계의 내용을 바탕으로 코드를 작성함
•
Testing and Verification: 개발된 소프트웨어가 요구사항을 충족하는지 확인. unit test, integrated test등을 수행하고 에러를 발견하고 수정
•
Delivery: 고객에게 소프트웨어 전달
•
Operation: 소프트웨어를 실제 환경에서 운영
•
Maintenance: 운영중 발견된 버그 수정 및 추가 요구사항 반영
Algorithms
A logical sequence of discrete steps that describes a complete solution to a given problem computable in a finite amount of time.
Abstraction
A model of a complex system that includes only the details essential to the
perspective of the viewer of the system.
복잡한 시스템이지만 사용자는 모든 내용을 알 필요 없고 필요한 내용만 제공하는것이 abstraction
Approaches to build Managable Modules
Fuctional Decomposition: 기능분해. 문제를 여러개의 subtask로 나눠서 해결
Object-oriented Design: 문제를 해결하는데 필요한 데이터와 operation으로 구성된 객체를 식별함
V&V
Program verification is the process of determining the degree to whic a software product fulfills its specification.
specification대로 만들어졌는지 확인하는게 verification
validation은 시스템이 잘 동작하는지 확인하는 작업이다
verification and validation을 V&V라고 한다.
Controlling Errors
Error 종류: Specifiaction Error, Design Error, Coding Error, Input Error
Robustness The ability of a program to recover following an error; the ability of a program to continue to operate within its environment
Preconditions Assumptions that must be trueon entry into an operation or function for the
postconditions to be guaranteed.
Postconditions Statements that describe what results are to be expected at the exit of an operation or function, assuming that thepreconditions are true.
Data Abstraction
separation of a data type’s logical properties from its implementation.
데이터 캡슐화(data encapsulation)는 데이터의 표현을 데이터를 사용하는 애플리케이션과 논리적으로 분리
객체 지향 프로그래밍에서 데이터와 그 데이터를 처리하는 메서드(함수)를 하나의 단위로 묶는 것
정보 은닉(information hiding): 데이터의 내부 표현을 외부에서 직접 접근할 수 없도록 하여, 데이터가 어떻게 저장되고 처리되는지를 숨겨서 데이터의 무결성과 일관성을 유지한다.
모듈성: 데이터와 메서드를 하나의 모듈로 묶음으로써, 코드의 유지 보수성과 재사용성을 높인다. 각 모듈은 독립적으로 작동할 수 있어, 변경이 필요할 때 전체 시스템에 영향을 미치지 않는다.
인터페이스 제공: 데이터에 접근하기 위한 메서드(게터와 세터)를 제공함으로써, 사용자는 데이터의 내부 구조를 몰라도 데이터를 안전하게 사용할 수 있다.
int 등의 타입도 data abstraction이다.
ADT(Abstract Data Types)
추상 데이터 타입은 구현과 독립적으로 속성을 정의한 데이터 타입. 데이터의 구조와 데이터에 대해 수행할 수 있는 연산을 개념적으로 설명하지만 실제로 어떻게 구현되는지는 고려하지 않는다.
ADT는 해당 데이터 타입에서 수행할 수 있는 연산을 명시한다. 예를 들어 스택은 push, pop, isEmpty와 같은 연산을 정의한다. 특정 프로그래밍 언어나 데이터 구조에 의지하지 않고 다양한 방법으로 구현할 수 있는 구현 독립성이 있다. 예를 들어 스택을 배열이나 연결리스트로 구현할 수 있다.
Data Structure
•
A collection of data elements whose organization is characterized by accessing operations that are used to store and retrieve the individual data elements
•
The implementation of the composite data members in an abstract data type
•
They are decomposed into their component elements
•
The arrangement of the elements affects how each element is accessed
•
Both the arrangement of the elements andthe way they are accessed can be encapsulated
Data Level
Application Level: modeling real-life data in a specific context
Logical Level: abstract view of the domain and operations
Implementation Level: speicific representation of the structure to hold the data items and the coding for operations.
4 kinds of ADT Operations
constructor: creates a new instance of an ADT.
transformer: changes the state of the data values of an instanace.
observer: allows to observe the state of the data values without chaning them.
Iterator: allows to process all the components in the structure sequentially.
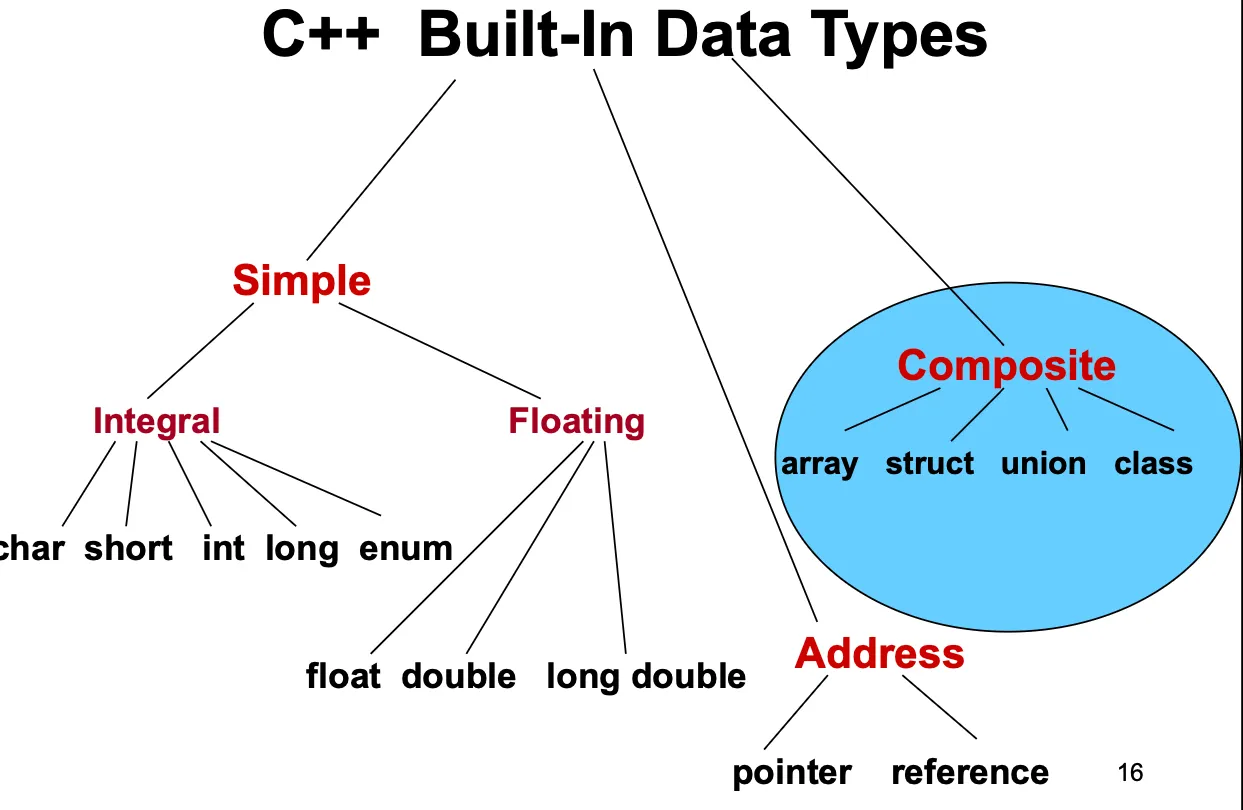
Built-In Types
int, float등 simple data type들은 implementation이 machine level에서 결정되어있다.
Built-in composite data types = array, class등. simple type을 묶어서 새로운 타입을 만듦.
Composite Data types
unstructed : components are not organized. ⇒ class and struct
structed: the organization determines method used to access individual components. ⇒ array
array는 모든 멤버가 같은 타입이라는 제약이 있다.
struct는 모든 멤버가 public인 class
class는 객체 생성의 description이고 컴파일해도 아무것도 생성되지 않는다.
객체를 생성하면 메모리에 공간이 할당된다 = instance
Record
레코드는 복합 데이터 타입으로 클래스에서는 멤버라고 불리고 데이터베이스에서는 필드라고 불리는 유한한 요소의 집합이다. 반드시 같은 타입의 집합이 아니어도 된다.
member selection operator = .
implementation을 위해서는 메모리에 공간이 할당되어야하고 base adress가 존재하고 offset테이블을 관리해야한다.
컴파일러는 컴파일할 때 테이블을 만든다.
Array
array는 컴파일 타임에 정해진 크기의 동일한 데이터타입 element의 collection
declaration과 index를 통해서 operation 수행함
Address(Index) = BaseAddress + Index * SizeOfElement
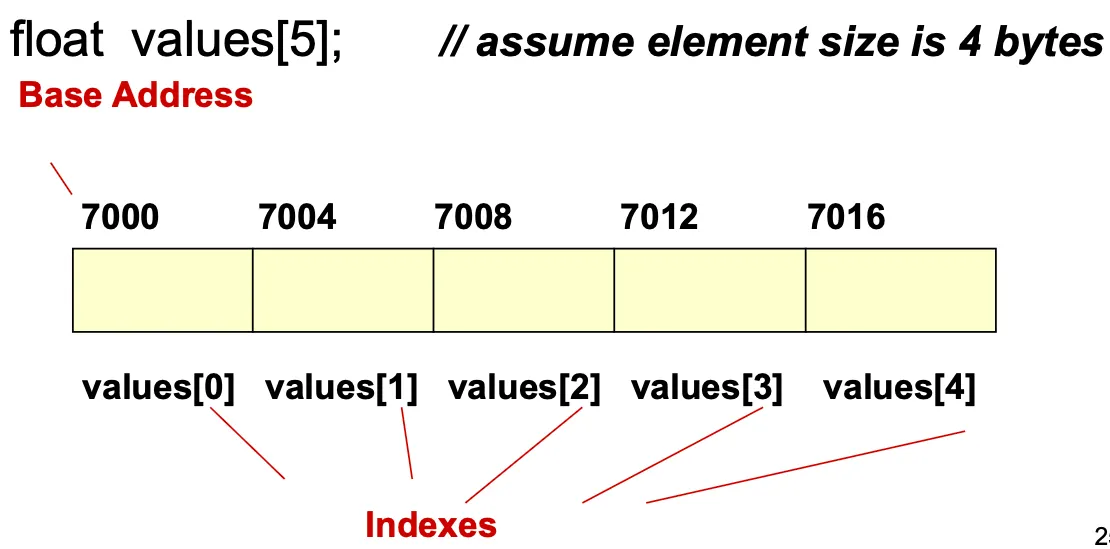
C++에서 함수의 return type이 될 수 없으며 다른 array에 할당할 수 없다.
ms-dos는 싱글 태스크로 운영체제 빼고는 메모리가 다 빈공간이었다. 그때는 컴파일러가 주소를 결정할 수 있었는데 지금은 멀티태스크라서 메모리상에 여러개의 프로그램이 올라가있고 로더는 프로그램을 넣을 공간을 찾아서 올려줘야한다. 그래서 컴파일할때는 몇번에 적재될지를 알수가 없다. 그럼 컴파일할때는 어떻게 할까? relocatable code ⇒ 시작주소를 0번이라 가정하고 컴파일한다음 로딩된 이후에 시작주소만큼 더해준다.
절대주소를 사용하는게 아니라 offset으로 계산한다. 모든 변수는 address가 있어야 하고 values[i]에서 i는 런타임에 값을 알 수 있기 때문에 주소계산을 런타임에 수행한다.
자바,파이썬은 런타임에 배열길이정보를 가지고 있어서 넘어가면 exception이 발생하지만
배열길이를 매번 확인하는것도 런타임에 드는 비용이다. C에서는 처음에 메모리 할당할때만 크기를 고려하고 정보를 보관하지 않기때문에 범위를 넘어가도 에러를 발생시키지 않는다. 크기정보가 사라지고 주소만 남기 때문에 배열을 인자로 줄 때 주소값을 주는것이다.
C에서 문자열을 array에 보관할때는 array의 길이관리를 하지 않으므로 array마지막에는 \0으로 표시하면 문자열의 끝으로 인식한다.
하지만 std::string클래스를 사용할 경우에는 \0처리를 해줄필요는 없다.
f(int a[10])으로 인자를 전달해도 크기정보는 전달되지 않고 주소값만 전달된다.
java, python 등은 array를 객체로 관리하며 관리하기 위한 정보들을 value로 가지고 있기 때문에 객체로 넘기면 크기정보가 따라 넘어가기 때문에 포인터도 필요없는 것이다.
java, python등은 메모리관리를 직접 하지 않으니 destructor도 없다. 시스템이 garbage collector로 메모리 관리를 하며 모든 변수를 garbage로 간주한 이후 사용되고 있는 것은 garbage가 아니라고 표시하는 방법을 사용해서 메모리를 해제한다.
Two-dimensional Array
row와 column으로 구성된 table형의 데이터를 저장하기 위한 data structure
메모리에 저장될때는 row순서대로 저장된다.
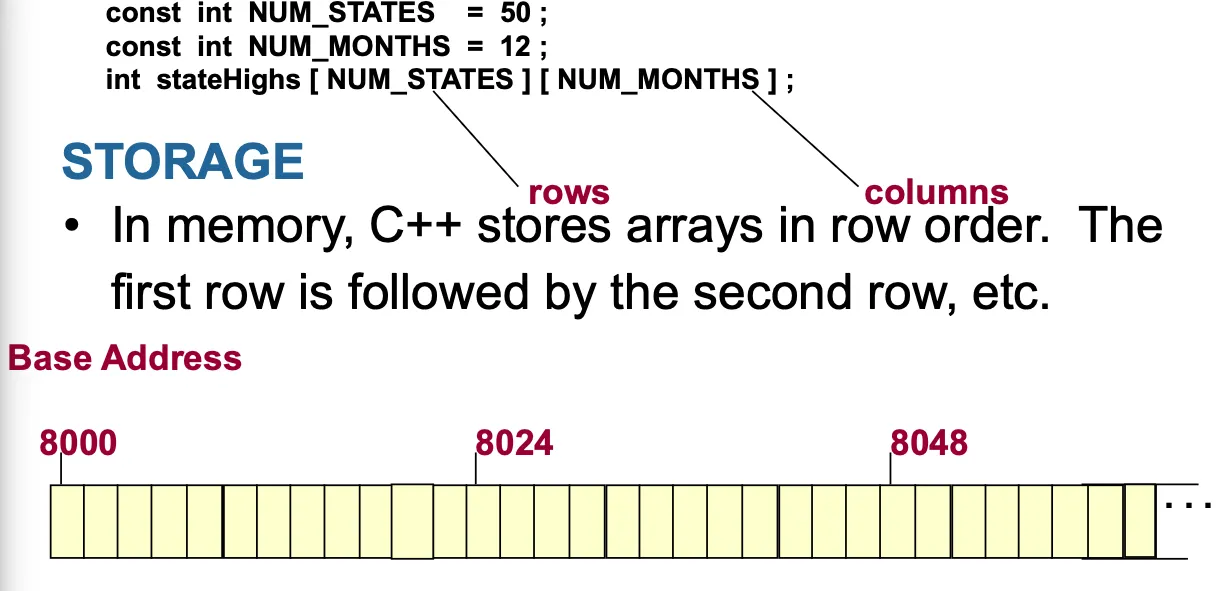
row major로 데이터 저장하는 언어와 column major로 저장하는 언어가 있다
column major는 이론적으로 안되는건 아닌데 사용하는 언어가 거의 없는 방식이다(julia 정도).
이차원배열도 런타임에 주소를 계산한다
void f(int **x);
void f(int *x[]);
//void f(x[][]); = 에러남
//row 사이즈를 알려줘야 컴파일러가 주소를 계산할 수 있다
void f(int x[][5]);
C++
복사
Class
A class is an unstructured type that encapsulates a fixed number of data members with tehe functions that manipulate them.
Variables of a class type are called objects.
object를 선언하고 사용하는 software를 client라고 함
client code uses public member functions to handle its class objects
Sending a message means calling a public member function
class description은 헤더파일에 있고 implementation은 cpp파일에 독립해서 사용한다. 라이브러리를 가져다 사용하는 사람은 소스코드를 가질 필요가 없으므로 헤더파일의 specification을 보고 사용한다.
템플릿은 클래스와 구현이 같은 파일에 포함되어있어야 한다.
내가 만든 헤더파일도 컴파일러 설정 변경을 통해서 시스템 헤더로 만들 수 있다.
객체는 pass by value형식으로 복사해서 전달하는데 객체가 크면 복사하는데 시간이 많이 걸려서 복사하지 않도록 레퍼런스를 넘긴다. 그리고 레퍼런스로 객체를 변경할 수 없도록 const 사용
array는 첫번째 주소만 넘긴다. return도 값을 복사해서 전달하도록 구현되어있다.
클래스 멤버는 실행하면서 바꿀수없다.
static 변수는 객체별로 메모리를 여러개 할당하는 것이 아니라 하나의 공간을 share하는 변수이다.
객체에서 멤버변수에 접근할때는 a.year처럼 사용하고 포인터로 멤버변수에 접근할때는 a→year형식이다.
Inheritance
Allows to create a new class that is a specialization of an existing class
The new class is called a derived class; the existing class is the base class
Polymorphism
the ability of a language to have duplicate method names in an inheritance hierarchy and to apply to the method that is appropriate for the object to which the method is applied
Inheritance + polymorphism allow to build hierarchies of classes that can be reused in differnt applications
