JPEG
jpeg은 1986년에 나온 컬러 정지영상의 압축표준이다.
1992년 컬러 정지화상압출을 위한 국제 표준으로 확정되었다.
jpeg보다 좋은 정지영상 코덱이 여러개 있지만 무료라서 앞으로도 계속 사용될 예정이다.
압축률은 20:1이상이고 품질 저하가 발생하는 손실압축 방식을 사용하지만 눈에 띄는 손실 없이 최대 25:1까지 압축 가능하다. 손실을 감수하면 100:1까지도 압축이 가능하다
적은 파일 용량으로 품질이 우수한 이미지를 표현할 수 있기 때문에 사진 압축에 많이 사용된다. 선이나 문자, 세밀한 격자 등이 다수 포함된 이미지는 gif나 png같은 비손실 압축 표준을 사용하는것이 바람직하다. 그래픽 계열은 gif png를 사용하는것이 좋고 jpeg를 사용하면 오히려 데이터 크기가 커진다.
jpeg2000은 wavelet transform사용해서 압축률을 30% 더 높였지만 loyalty를 받기 때문에 사용되지 않음.
jpeg ar은 증강현실 표준이고, jpsearch는 content based still image search기술 표준으로 사진은 파일이름이 없기 때문에 자동으로 사진을 분류하고 찾기 위한 기술이다. search engine등에서 사용된다.
jpeg은 홀로그램 등 지금도 새로운 응용분야 개척을 모색하고 있다.
jpeg은 동영상 압축 표준인 mpeg의 기초가 된다.
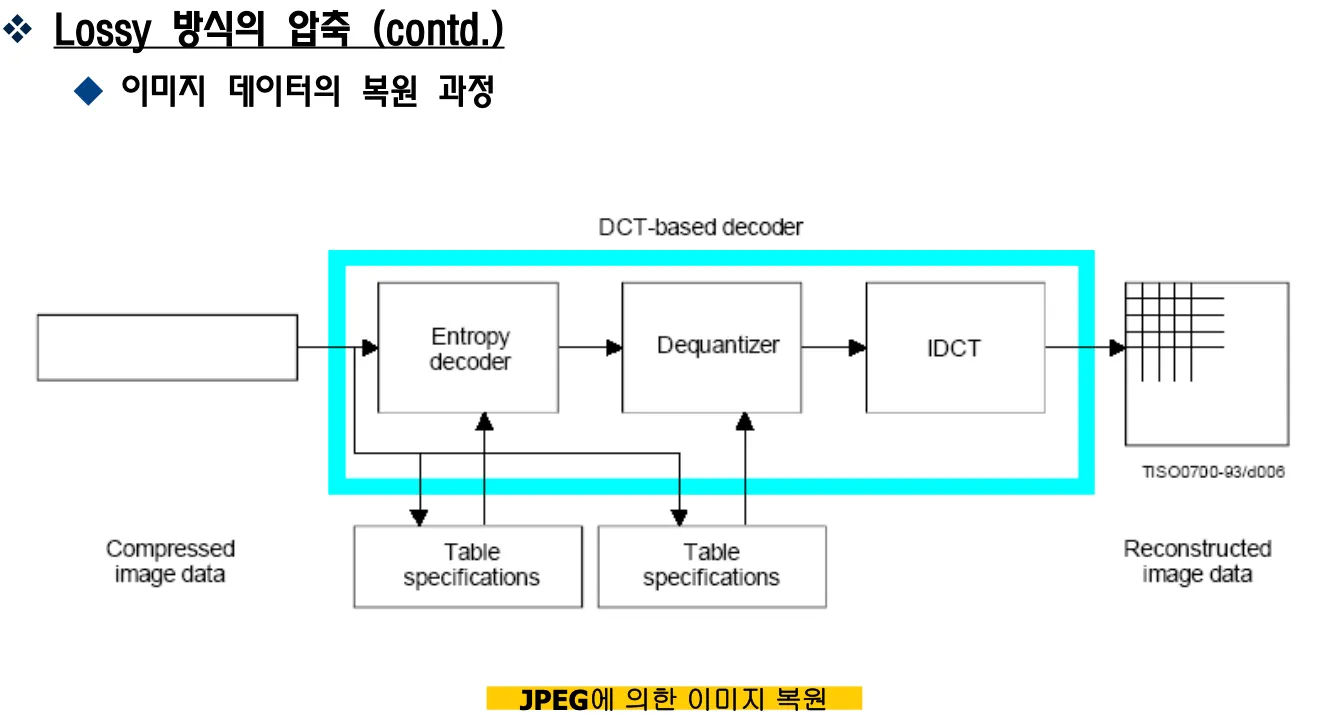
jpeg은 손실방식과 무손실 방식이 있는데 lossless는 x-ray같은 픽셀 하나하나 중요한 경우에 사용하는 방식이고 lossy는 dct+Q+VLC방식으로 인간의 관심이 많이가는 부분은 정밀하게 처리하고 관심이 안가는 부분은 과감하게 삭제처리한다.
JPEG 알고리즘
JPEG압축방식에는 가역방식(lossless)이 있고 비가역방식(lossy)이 있다.
lossy방식은 baseline방식과 extended방식으로 나뉜다.

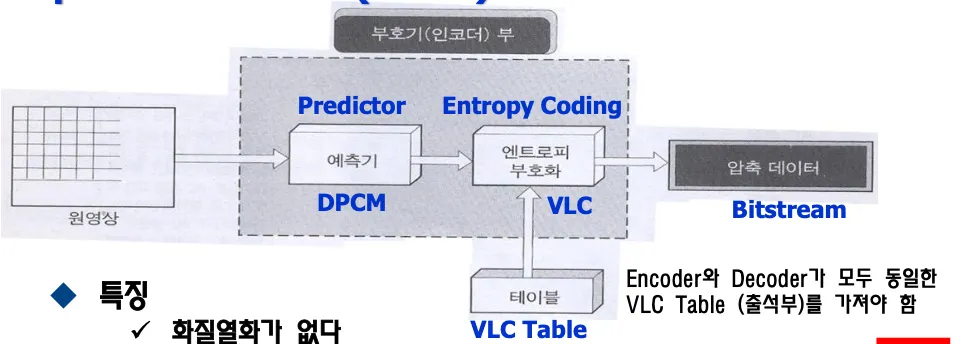
가역방식은 DPCM+VLC를 사용하는 방식으로 DPCM은 차를 구해서 laplacian분포를 만든 이후에 확률 편중을 이용해서 VLC로 많이 나오는 symbol에 짧은 이름을 붙이는 방식이다. spatial model에서 공간적 중복성을 제거하는 방법이다.
original 영상이 predictor에서 DPCM을 통해서 데이터가 늘어난 상태에서 VLC를 거쳐서 bitstream이로 변환된다. 엔트로피 코딩을 수행하기 위해서는 인코더와 디코더가 동일한 VLC테이블을 가지고 있어야 한다.
모든 symbol을 VLC로 처리하면 테이블의 크기가 커지고 메모리에서 테이블을 참조해야하는데 그렇게 되면 parsing 속도가 느려진다. 따라서 캐시를 사용해서 많이 사용되는 symbol을 저장하고 테이블의 크기도 가능한 줄이는것이 좋다.
따라서 확률이 높은 symbol은 vlc로 처리하고 확률이 적은 것은 FLC(Fixed Length Coding)로 처리한다. DPCM을 거치면서 8비트에서 9비트로 늘려놨던 걸 그대로 사용해서 9비트로 처리한다.
인코더는 VLC인지 FLC인지 알지만 디코더는 구분할 수 없기 때문에 디코더에게 escape을 보내면 FLC로 처리하라는 뜻으로 약속한다.
escape는 반드시 VLC테이블에 포함되어야한다.
DPCM을 적용하면 인접한 세 화소를 조합해서 예측치를 생성한다. Px = Ra는 x의 예측치를 생성하는데 a의 값을 reconstruct해서 사용한다는 뜻이다.
DCT를 이용하는 경우 dct quantization vlc를 거친다. quantization도 quantization table이 필요하다.
vlc테이블은 동일한 테이블을 인코더와 디코더가 가지고 있거나 테이블을 전송해줘야한다.

y신호와 uv신호 양자화 테이블이 있고 이미지 복호화 과정에도 테이블 두개가 쓰인다.
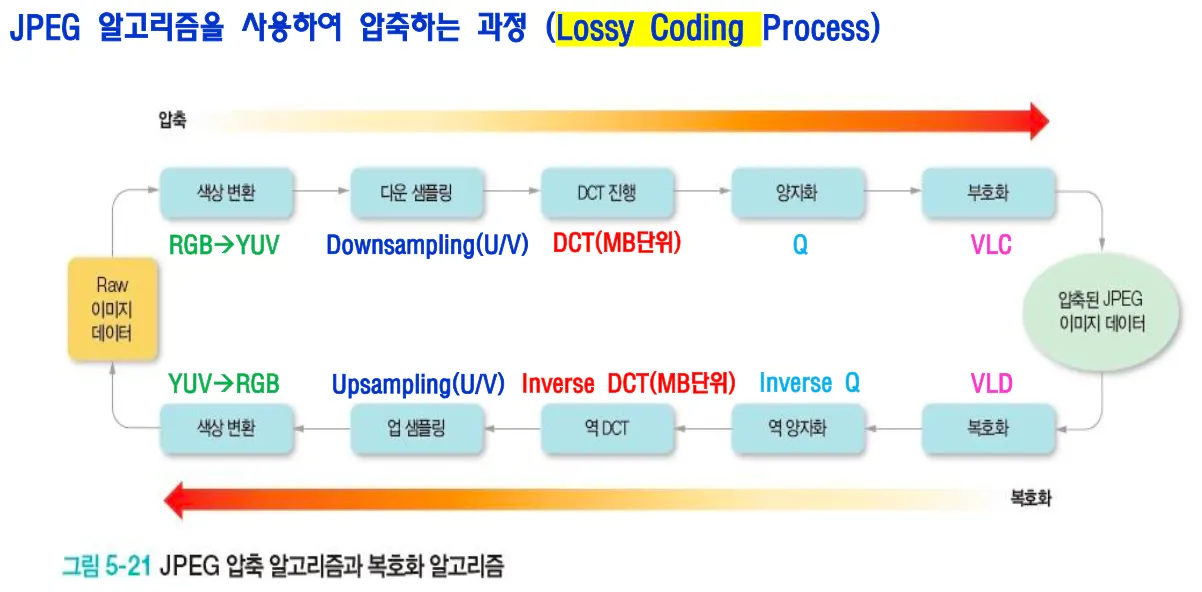
jpeg알고리즘을 사용해서 lossy하게 코딩하는 과정을 정리하면 rgb데이터를 yuv데이터로 바꾸고⇒ 다운샘플링을 하고⇒ 매크로블록 단위로 dct를 진행하고 ⇒ 양자화하고 ⇒ VLC부호화해서 ⇒ 비트스트림으로 보낸다.
rgb를 yuv로 down sampling 할때 4:2:0 foramat으로 u,v는 민감하지 않으니까 4개를 하나로 다운샘플링하는 것이다.
최소 부호화단위가 8by8인데 영상 전체를 한번에 DCT를 적용해서 처리하기에는 연산이 너무 크다.그래서 8by8단위로 진행한다. 그 당시의 하드웨어로 처리할 수 있는 최대한이 64개 인풋이 들어가서 64개 아웃풋이 나오는것이었다. y를 8by8로 한다면 u,v는 4by4가 되는데, 그럼 복잡하기 때문에 하나의 dct로 처리하기 위해서 8by8을 최소단위블록으로 하고 y는 16by16으로 8by8 4개로 처리한다.
16by16블록을 매크로 블록이라고 한다. 최근에는 소프트웨어로 처리해서 64by64으로도 처리한다.
엔트로피 코딩을 수행하면 에러가 propagation되는 문제가 발생한다. 그래서 중간에 끊어서 error localization을 수행해줘야한다. 매크로블록단위로 격벽을 치면 에러가 발생해도 local 범위에서 끊긴다. jpeg에서는 error localization을 수행하지 않지만 mpeg에서는 반드시 수행한다. 그 다음 영상까지 에러가 propagation되기 때문이다.
DCT에서 DC는 pixel level의 평균값이다. DCT과정은 주파수 도메인으로 변경해서 줄을 세우는 것으로 사람의 시각에 민감한 부분과 민감하지 않은 부분을 구분한다. 고주파수는 인간의 눈에 민감하지 않다. DCT를 수행하고 양자화 과정에서 몫만 취하고 나머지는 버리도록 truncation하면 양자화 작업으로 loss가 발생한다. 양자화 값은 표준으로 정해지지 않고 자체적으로 정의한 값을 사용한다.
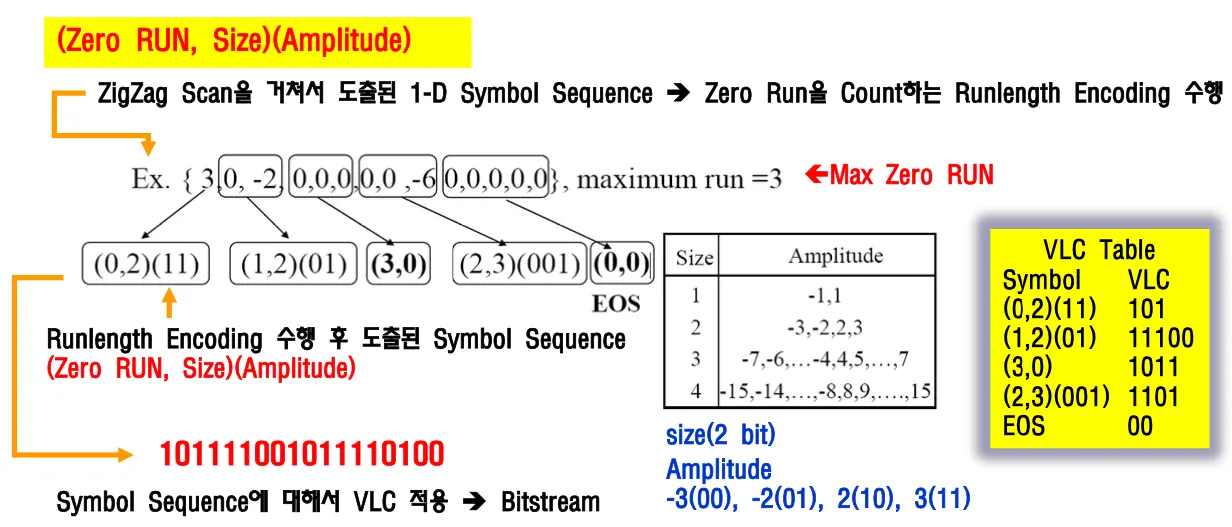
양자화된 DCT계수를 zigzag패턴으로 스캐닝하여 1차원 배열로 전환한다.
1차원 배열 시퀀스에서 RLE(runlength encoding)을 적용해서 각 symbol에 대한 VLC테이블을 생성하고 허프만 코딩을 적용해서 entropy coding해서 bitstream으로 만든다.

허프만 코딩은 각각의 symbol당 codeword를 할당하고 prefix word로 구분하며 확률적으로 많이 발생되는 symbol에 짧은 codeword를 할당하는 방식이다.
jpeg에서는 허프만과 arithmetic을 둘 다 사용한다.
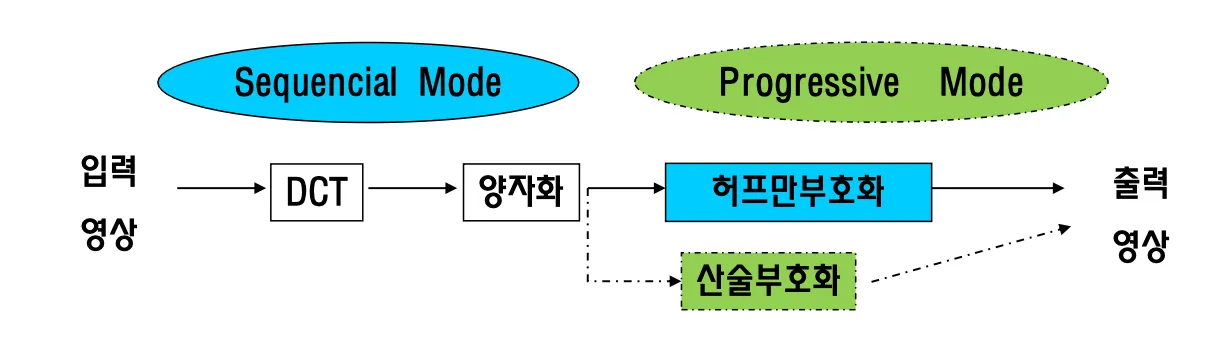
Sequential 과 Progressive방식
sequential 방식은 허프만부호화를 사용하고
progressive mode는 산술 부호화를 사용해서 성능이 더 좋지만 redundant한 작업들을 많이 해야한다.
디폴트 방식(비인터리브 방식)은 모든 비트스트림을 다 보내서 디코딩이 완료되면 영상을 출력하는 방식이다.
sequential 방식은 인터리브 방식, baseline방식이라고 부르며 좌측 상단부터 순차적으로 라인별로 출력한다.
progressive방식은 저주파 성분부터 먼저 순차적으로 출력하는 spectral selection방식과 한 단계씩 올라가면서 낮은 레벨의 해상도와 차분 부호화하는 연속근사(successive approximation)방식이 있다.
sequential방식이든 progressive방식이든 둘다 데이터를 기다리는 사람을 위한것이지 코딩효율을 위한것은 아니다.

계층형/비계층형 Format
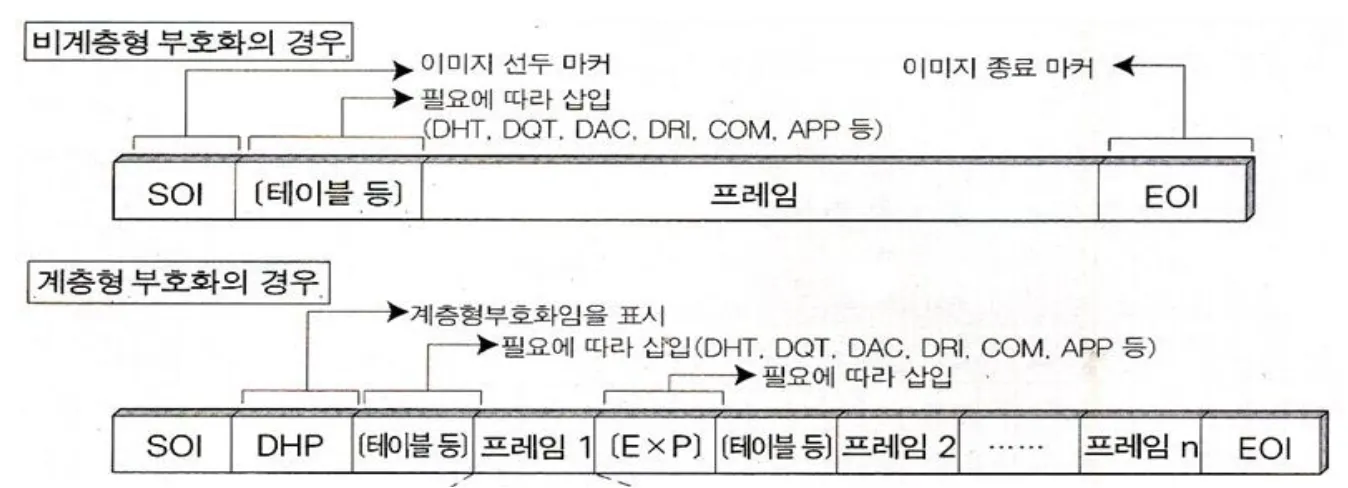
부호화 Format은 SOI로 시작되어 EOI로 끝난다.
계층형 Format은 여러개의 프레임을 갖고 있고 데이터를 조금씩 나눠서 보내는 방식으로 저해상도부터 차례로 높은 해상도의 정보가 들어있으며 Format차원에서 progressive방식을 지원한다. 여러 다른 해상도 계층에서 영상을 부호화하고 한단계씩 올라가면서 낮은 레벨의 해상도와의 차분을 부호화해서 점진적으로 화질을 개선하는 방식이다.
비계층형 Format은 하나의 프레임만을 가지고 있고 모든 데이터를 하나로 보낸다.
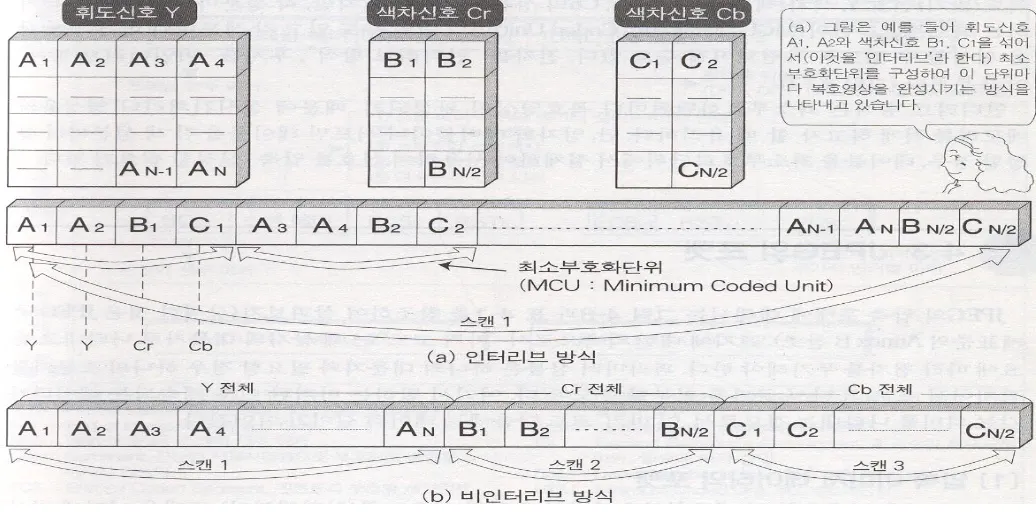
인터리브/비인터리브 방식
휘도신호 Y의 일부와 색차신호CbCr의 일부를 섞은 최소 부호화 단위를 인터리브라고 하며 최소 부호화 단위마다 복호영상을 완성시키는 방식이 인터리브 방식이다. sequential, progressive방식이 인터리브 방식이다.
비인터리브 방식은 각 성분들이 독립되어 있어서 모든 데이터가 도착해야 영상을 복원할 수 있는 디폴트 방식에 해당한다.