Entropy coding
transform이후에 통계적인 처리를 통해서 정보를 압축한다.
부호의 발생확률의 편중을 이용해서 압축할 수 있다.
한정된 sample space에서 부호는 편중된다. 그럼 정보의 편중을 활용해서 가변길이코딩을 하면 된다.
확률이 1이면 정보는 0이다. 확률이 작으면 정보의 양이 많다.
정보의 단위는 2진법 yes/no이고 엔트로피는 모든 심볼의 평균 정보량을 뜻한다
확률*정보량의 합이 entropy다 == 모든 심볼의 평균 정보량
같은 길이의 stream을 보내도 entropy는 다를 수 있다. 정보량은 확률이 균일할수록 더 많아진다.
확률이 편중되는 경우와 똑같은 확률을 갖는 경우에서 편중된 경우가 더 적다.
모든 symbol의 확률이 똑같은 경우 엔트로피는 최대가 된다.
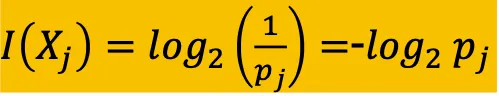

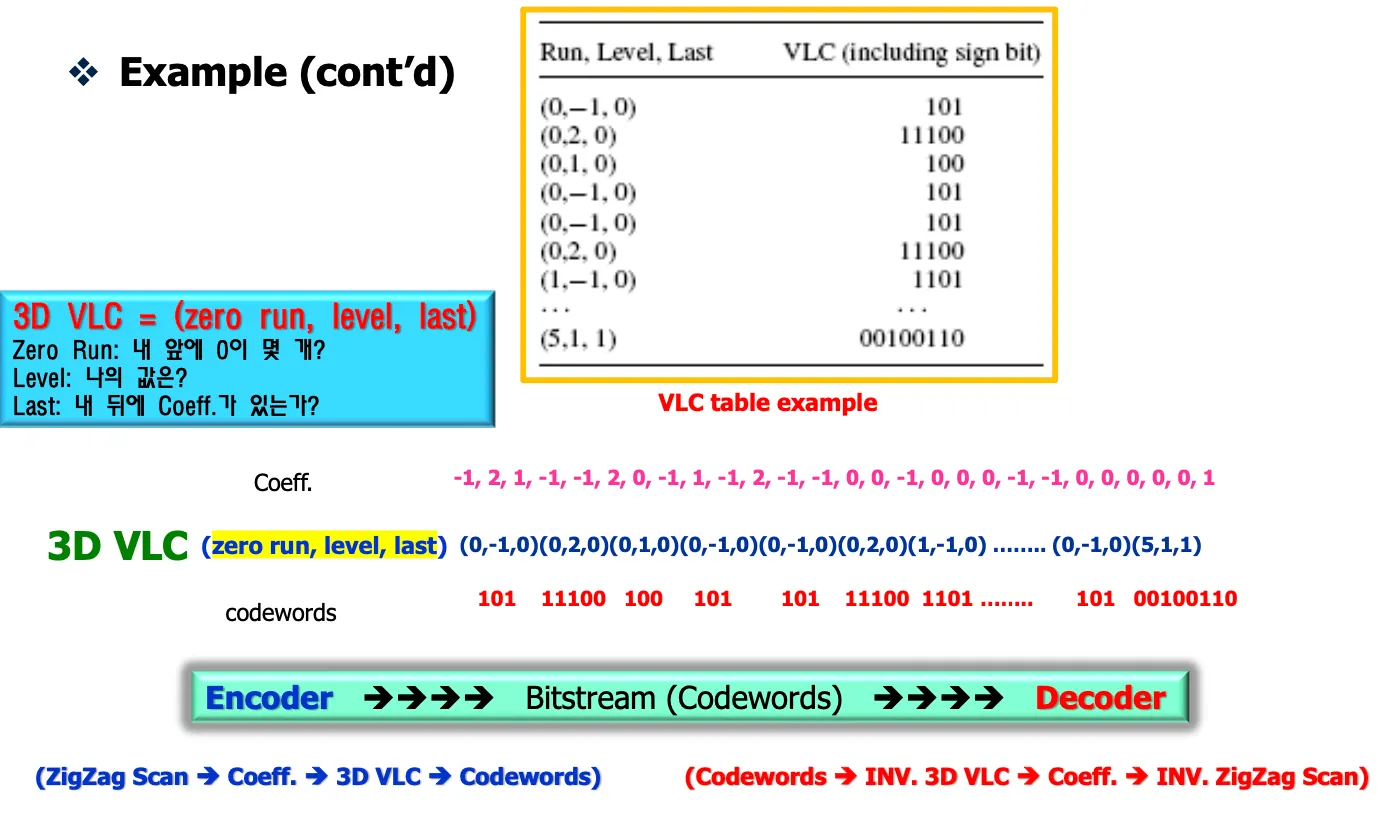
확률이 편중되면 symbol에 이름 붙일때 발생확률이 높으면 짧은 이름을 붙인다 = entropy coding
uniqueness를 만족하지 않으면 앞자리를 늘린다 = prefix code
fixed length coding은 00 01 10 11이 된다.
parsing process
prefix code를 어떻게 디코딩할까? 받는쪽은 어떤 데이터가 오는지 모름 고정장이면 4개의 심볼이 있을때 두 비트씩 잘라서 파싱하면 되는데 VLC인 경우 디코더는 알수가 없다.
이를 해결하기 위해서 디코더가 vlc테이블을 가지고 있어야한다.
예를 들어 1이면 10 111 등 구분 안된다. 10으로 unique한 심볼로 완결되면 parsing마치고 그 다음 심볼로 인식
⇒ 1이면 진행하고 0이면 parsing마친다.

Run-Length Encoding (RLE)
팩스를 예로 들면 흑백이면 1 하얀색은 0이라고 할때 라인스캐너가 한줄한줄 지나가면서 0,1을 하나의 라인을 스캔한다. 백지니까 0이 굉장히 많음 흑백팩스 많아봐야 까만건 몇%밖에 차지하지 않는다.
0을 전부 보내야할까?
0의 숫자를 세서 20개의 0이라는 형태로 보내는게 run length encoding.
동일 symbol의 run length를 인코딩하자 ex)AAAABBBBBCCCCC= 4A5B5C
correlation이 높은 데이터들은 run의 길이를 코딩해서 보내면 데이터를 확 줄일수있다!
랜덤 distribution이나 uniform distribution을 가진 경우 correlation이 낮아서 오히려 더 늘어난다.
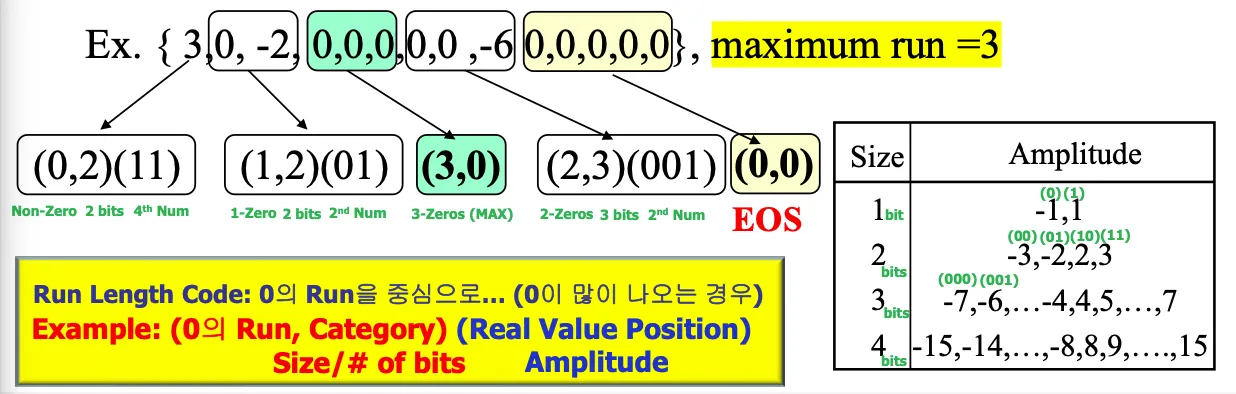
jpeg에서 사용한 RLE는 symbol1과 symbol2로 구성됨
Symbol-1
run length와 Size가 들어감. 0의 개수를 세는데 숫자가 나왔을때, 앞에 0이 몇개가 있는지 카운트하는 것이 run lnegth(consecutive zeros preceding non-zero value)
사이즈는 0이 아닌 값의 개수를 표현하기 위해서 몇비트가 필요한지
(데이터를 보낼때 연속적인0의개수, 0이 아닌값의 개수를 표현하려면 몇비트가 필요한지)
symbol-2
0이아닌 값의 실제크기 = Amplitude
Symbol-1에서 (0,0)은 EOS = end of sequence, (MaxRunLength, 0)은 Runlength extension symbol
EOS termination 11100000으로 끝날때 111로 끝낸다.
Huffman Coding
각각의 symbol1,2의 이름을 만들어서 확률적으로 엔트로피 코딩할수 있지 않을까?
symbol당 이름을 assign하는것이 허프만 코딩이다.
높은 확률에 짧은 이름을 주고 낮은 확률 symbol에 긴 이름을 주며 prefix code를 사용한다.
prefix coding알고리즘을 체계적으로 만든게 허프만 코딩
1.
확률이 높은 순으로 위에서 아래로 정렬한다
2.
가장 확률이 낮은 두 symbol들을 선택하고 각각 0,1을 assign한다
3.
두개의 symbol을 묶고 확률을 더해서 하나의 symbol로 만든다음 1,2되풀이
4.
마지막에 되짚어오면서 codeword를 정함
0,1순으로 할당할지 1,0순으로 할당할지? 같은 확률일 경우 아래에 배치할지 위에 배치할지? 정하기 나름이지만 일관성이 있어야 한다.
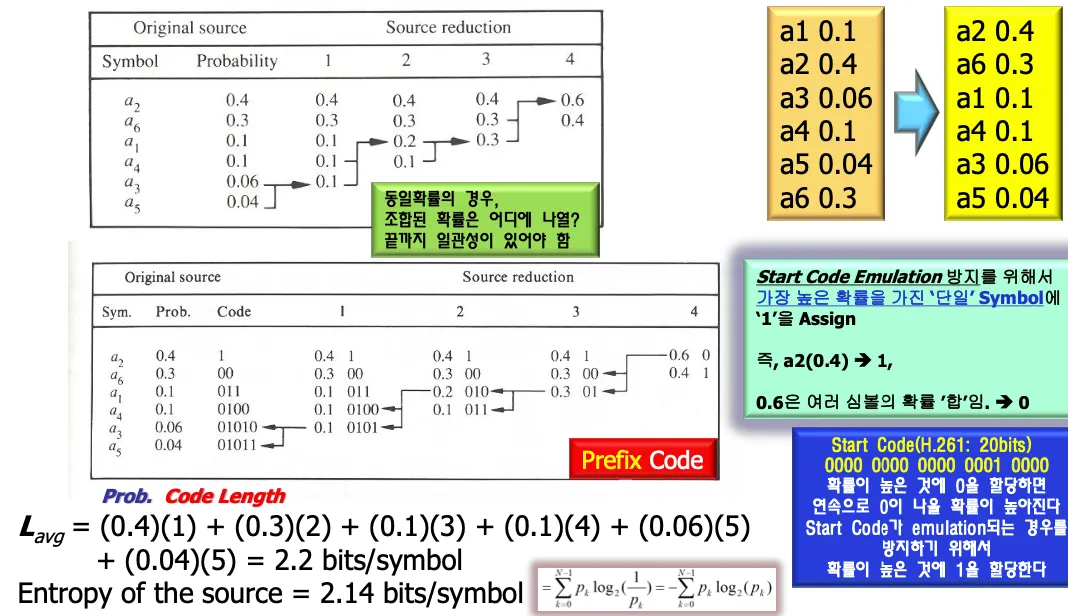
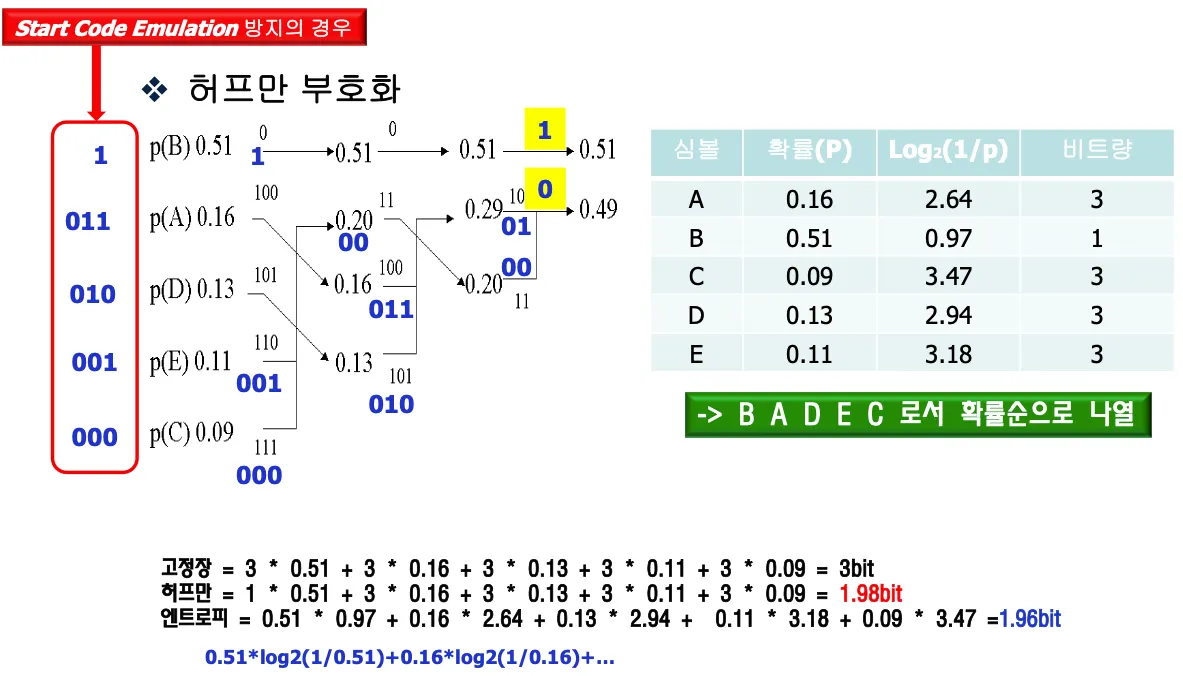
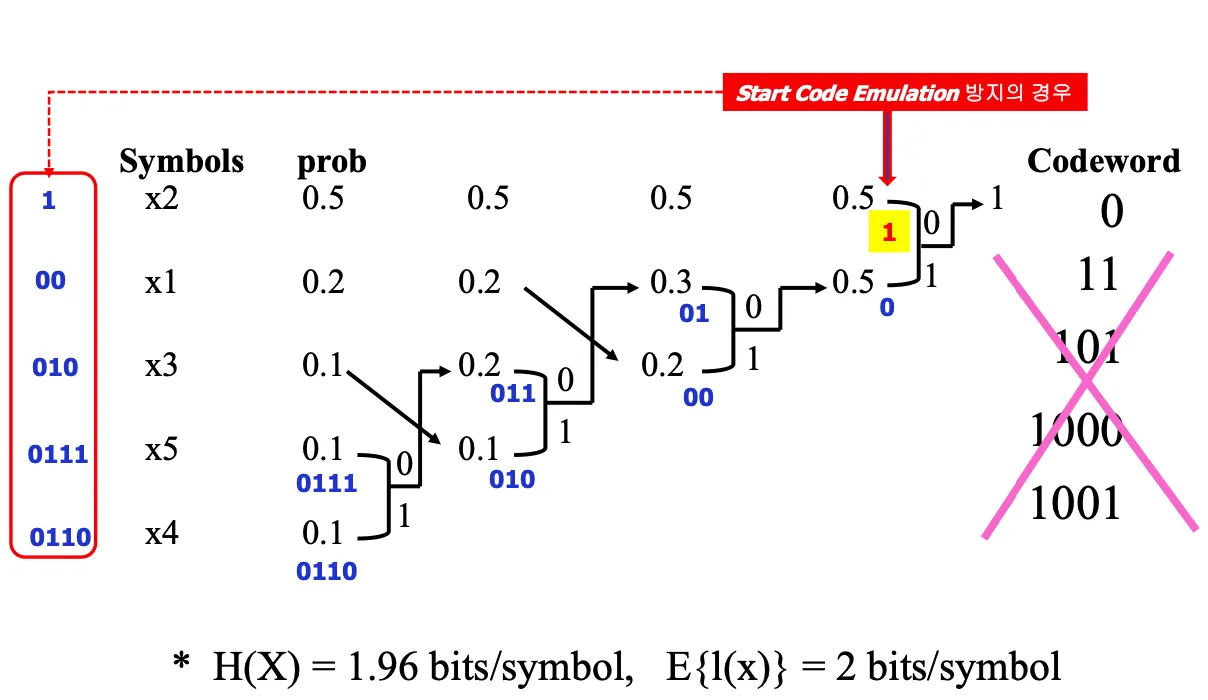
start code emulation방지를 위해서 가장 높은 확률을 가진 단일 symbol에 1을 assign한다.
start code란?
에러 발생했을때 에러처리하려면 에러 detection이 가능해야 한다. 그래서 detection code로 start code란걸 넣는다. H.261의 경우 20비트의 0과1의 조합이다.
같은 길이의 코드가 존재하지 않도록 해야 하는데 높은 확률인 0들이 많이 존재하면 어쩌다가 겹칠 확률이 있으므로 확률이 높은symbol에 0을 assign하면 안된다.
Aritmetic coding
허프만코딩은 심볼당 비트=이름을 assign한거였는데 arithmetic coding은 sequence당 이름을 assign하는 것이다.
AB순서로 나오는걸 이름붙이고 ABC를 이름붙이고..
하나의 codeword가 source symbol의 sequence를 대신하므로 데이터를 확 줄일수있다.
conditional probability로 계산하는데 길어질수록 확률이 작아진다.
낮아지는걸 정확히 산술계산해야하므로 계산량이 많아지는 단점이 있다. 하지만 최근의 하드웨어는 감당 가능하다
end of message 심볼이 필요하다. AB에 대한건지 ABCD에 대한건지 끊어주는 역할을 해줘야 한다.
많이 발생되는 심벌을 코딩할때는 넓은구간 배정하고 비트가 적게 필요하지만 적게발생하는 심벌은 좁은구간을 배정하고 표현에 더 많은비트가 필요하다.
코딩효율은 높으나 구간을 계산하기 때문에 연산복잡도가 높다. huffman은 단지 테이블 매칭만 하면 된다.
최근에 나오는 알고리즘은 거의 대부분 arithmetic coding을 사용한다.
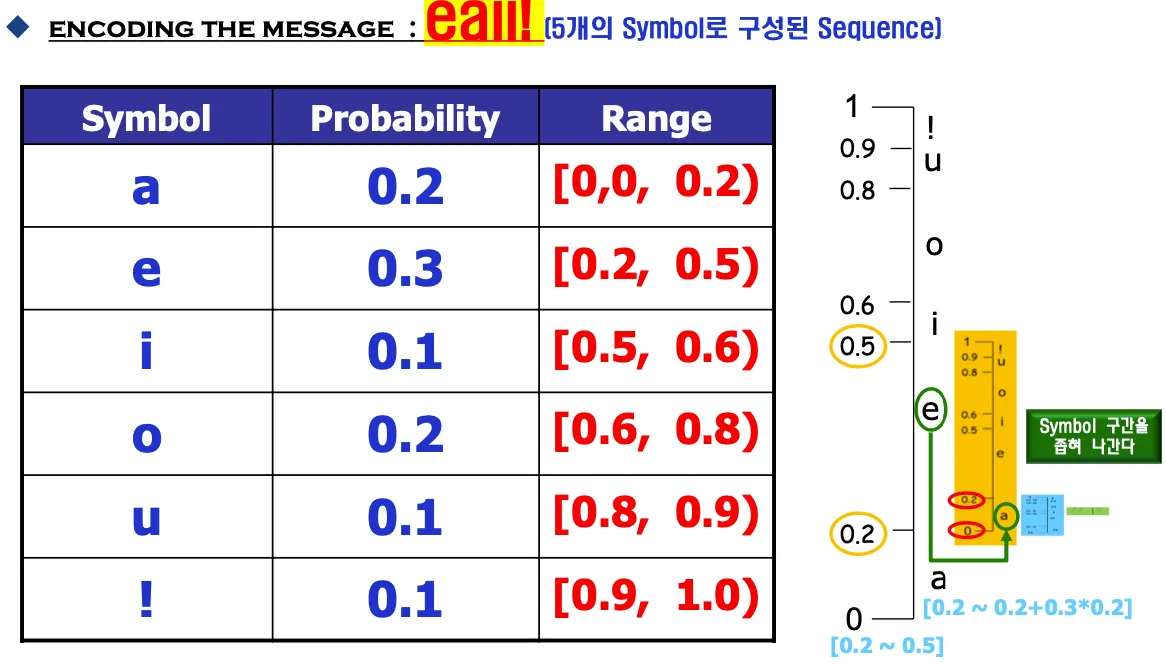

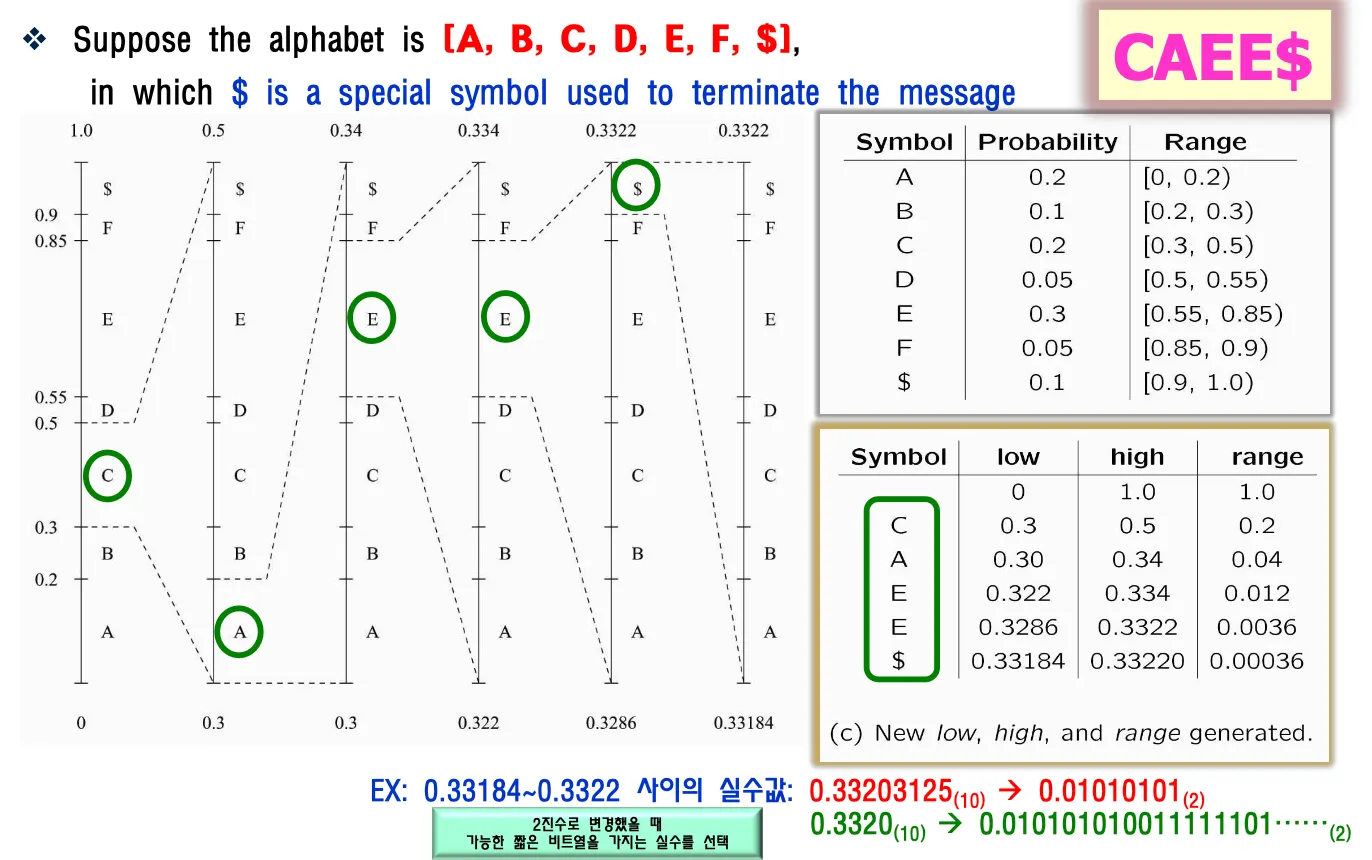
0~1까지 probability에 따라서 symbol이 담당하는 구간을 나눈다.
점점 작은 구간이 생기고 그 구간을 대표하는 숫자를 보내면 완성.
몇개의 심볼을 대표한다는 것을 표시해줘야한다.
구간 내에서 이진수로 변경했을때 가장 짧은 비트수를 가지는 실수를 선택한다.
(0.233597, 5)라는 정보를 보내면 디코더는 구간을 펴보면서 속하는 symbol을 확인한다. 계속해서 들어가는걸 막기 위해서 몇개인지 보내주는데 $ terminate symbol을 사용해서 개수 정보가 아니라 $심볼이 나오면 끝내도록 할 수 있다.
Entropy coding
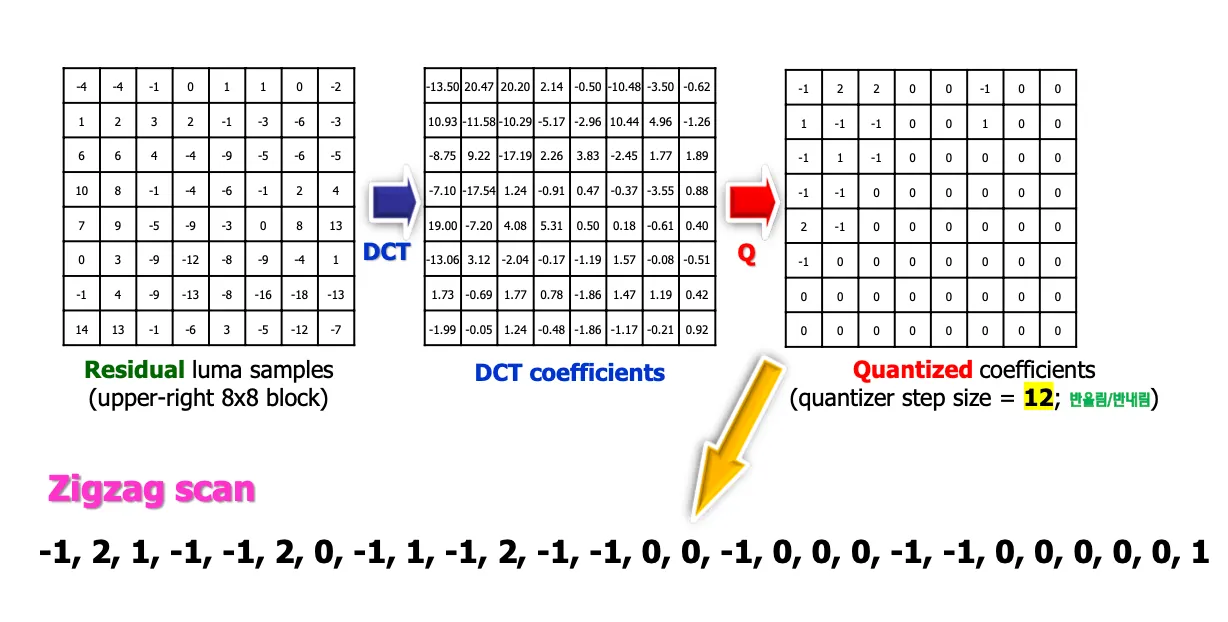
f0영상이 들어오면 처음에는 temporal model을 적용하지 않고 spatial model을 적용해서 DCT를 통해서 coefficient를 만들고 Quantization해서 나온 coefficient를 보내면 entropy encoder에서 VLC인코딩해서 비트스트림으로 전송한다.
f1영상이 들어오면 인코딩했던 f0영상을 reconstruction해서 저장해놓고 temporal model을 적용해서 f1영상의 motion vector를 구해서 vector를 entropy encoder로 보내고 f1-f0 영상에서 motion compensation으로 residual을 구해서 spatial model로 보내고 spatial model에서는 DCT+Quantization한다. Quantization하면 많은 데이터들이 0이 되고 zigzag스캔을 수행한 후에 coefficient를 보내면 entropy encoder에서 VLC인코딩해서 비트스트림으로 보낸다.