
Techniques for video compression
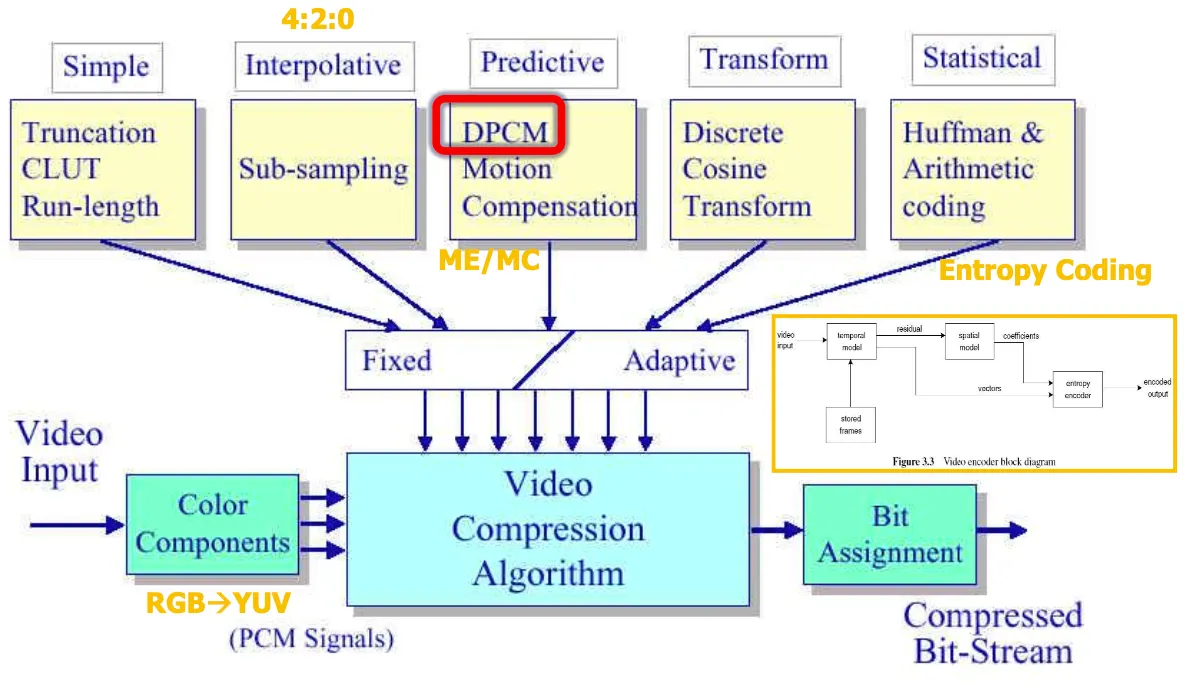
video input의 rgb redundancy가 높아서 yuv로 바꾸고 그과정에서 sub-sampling(다운샘플링)을 수행⇒
데이터를 4:2:0포맷으로 원본 데이터를 줄이고 predictive과정에서 dpcm, motion compensation은
주변 화소간의 중복성이 높기 때문에 중복성을 제거하기 위해서 차를 구해서 처리하는것이 DPCM이고
영상 간의 temporal model을 구하는것이 motion estimation으로 motion이 찾아진 영상과의 차 residual을 spatial모델 통해서 coefficient를 구해서 entropy encoder로 보내고
transform과정에서 discrete cosine transform DCT
그렇게 만들어진 coefficient가 엔트로피 인코더로 가서 통계적인 중복성을 제거하는 과정으로 처리한다.
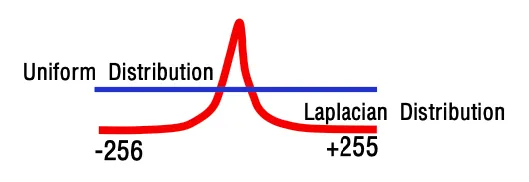
DPCM은 인접화소간 difference를 취하는 것으로 DPCM만으로는 오히려 데이터가 9비트로 늘어나고 오히려 laplacian distribution data의 확률편중을 활용해서 entrophy coding한다.
DPCM ⇒ Pixel-based Predictive Coding
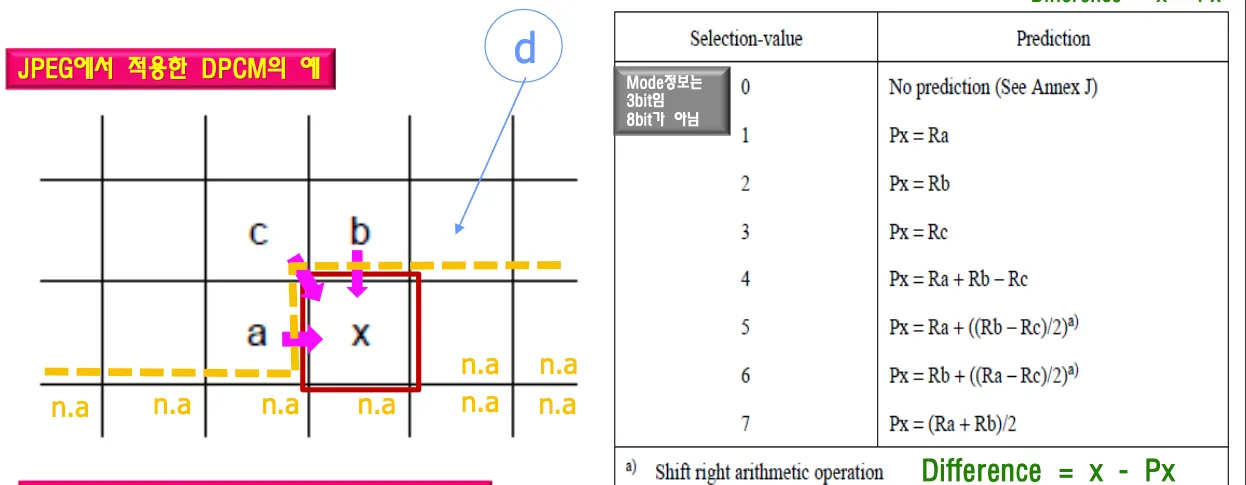
인접한 세 화소를 조합하여 예측치를 생성한다.
Encoder는 Decoder가 받는 방식대로 데이터를 보내야 하며 둘 간의 mismatch가 발생해서는 안된다.
r은 reconstructed, p는 predictor
인접한 세 화소 수평방향 수직방향 대각선방향과 비슷한지 물어보고
na는 받은적이 없는 미래의 값들을 의미하며 디코더는 알 수 없는 값이다. 디코더는 모르는 값이 있기 때문에 알고있는 값으로 처리해야한다. encoder decoder간에 mismatch가 발생하면 안된다.
a, b, c로 dpcm으로 차를 구해서 셋중 하나랑 같다면 값은 0이 된된다.
디코더는 차를 구한 값이 왔는데 뭐랑 뺀 차값인지 알 수 없기 때문에 mode정보를 보내줘야 한다.
수평방향 수직방향 대각선방향중 어떤것과 차를 구한 값인지 알려주는것이 mode이다.
r은 reconstructed로 재생된 데이터로부터 빼야함을 의미하고 original 값에서 빼는게 아니라 디코더에서 재생된 a값에서 뺐다는 것이다. x값의 predicted value를 의미하는것이 Px이다.
mode 정보를 하나 보내려면 8비트 = 1바이트가 필요하다. mode difference를 인코더에서 같이 에서 보낸다 ex) (2,3) ⇒ 디코더는 2를 보고 모드가 2번인 것을 알 수 있고 Px = Rb이고 차가 3이라는 뜻이므로 Rb에 3을 더해서 값을 구한다.
selection mode와 difference를 전송하며, difference값이 0이 되는 경우 보낼필요가 없어서 데이터가 줄어든다.
이후 엔트로피 인코더에서 예측 오차에 대해 허프만 부호화 또는 산술 부호화를 통해 엔트로피 부호화를 적용한다.
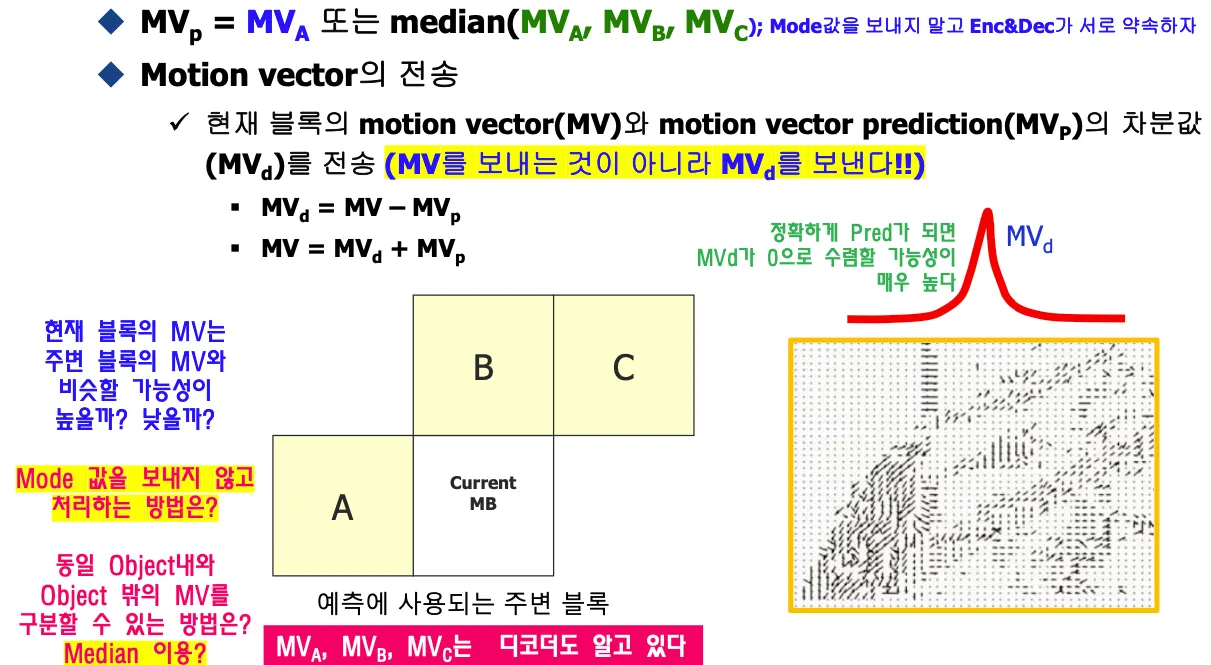
Motion Vector Prediction
주변블록을 사용해서 motion vector를 예측해서 차의 값을 보낸다.
모드정보를 보내지 않고 처리할수있는 방법은 없을까?
현재 블럭의 모션이 주변 블럭의 모션과 비슷한지 물어보고 비슷하지 않으면 적용하면 안된다.
모션들은 군집으로 모여있으며 object의 일부는 같이 움직인다. 다른 오브젝트에 속하는 경우 모션이 다르다.
jpeg은 모드정보를 보내야하는데 모션에서는 같은 오브젝트 안에 있는 모션벡터는 같은 오브젝트 안에 있는걸 따라갈 것이기 때문에 모드정보를 보낼 필요가 없다. 정확하게 prediction되면 모션벡터가 0으로 수렴할 확률이 높다.
모드값을 보내지 않고 동일 오브젝트와 오브젝트 밖의 모션벡터를 구분할 수 있는 방법이 없을까?
median을 이용하면 된다. 주변블록 중에서 중앙값을 구한다.
오브젝트에서 벡터가 각자 다른 방향으로 간다는건 개체가 찢어지는 것인데 이런 경우는 거의 없고 motion vector prediction을적용하면 안된다.
mode를 보내지 않고 encoder decoder가 약속해서 median값으로 prediction값을 정하자.
mpeg-4에서는 median을 사용하기로 encoder와 decoder간 약속이 되어있다.
motion vector prediction값 구하고 MVd(motion vector difference)는 laplacian분포를 가지므로 entropy coding을 적용할 수 있다.
DCT(Discrete Cosine Transform)
왜 frequency domain으로의 변환이 필요할까?
인간에게 민감한 자료와 민감하지 않은 자료를 줄세워야하는데 민감하지 않은 데이터는 삭제하거나 줄이면 데이터양을 줄일 수 있다. 데이터양이 줄어도 인간이 인지하지 못한다면 압축에 성공한것이다.
Frequency domain만 구한다면 오히려 데이터의 양은 늘어난다. 이후에 Quantization을 적용해야한다.
Frequency Domain = 공간 주파수란 공간상에서 데이터 변화량을 나타내는 척도이다.
공간 주파수가 낮으면 그림이 평활하고 천천히 변화하며 화면내 상관도가 높다.
공간주파수가 높다면 체크무늬처럼 세밀하고 변화가 많으며 극단적으로 화소값이 차이난다.
sharp한 edge만들려면 높은 주파수대의 sine wave의 sum을 통해서 구해야 하며 높은 주파수 대역의 sine wave가 많이 필요하므로 엄청난 data를 전송해야한다.
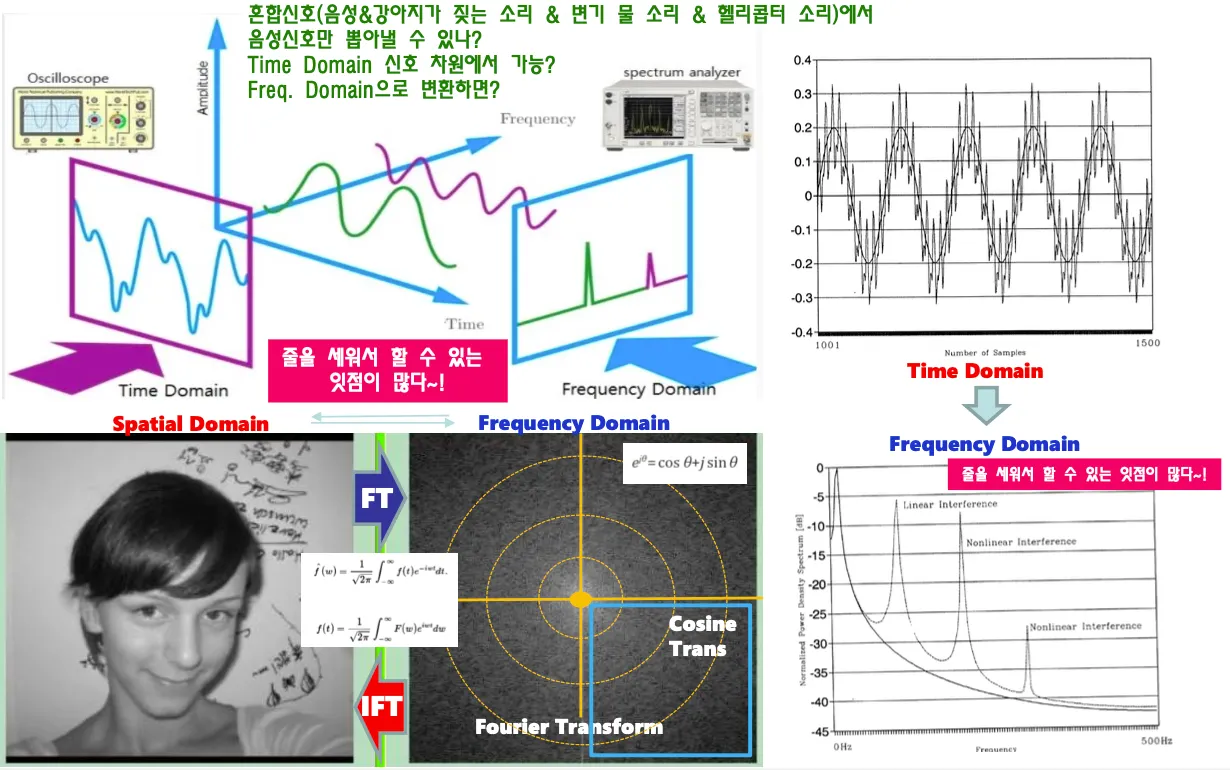
소리 신호를 Time domain으로 옮기면 여러 소리가 섞여있어서 복잡하지만 각각의 신호들은 사실 따로 존재함. 혼합 신호에서 음성신호만 뽑아내는것은 time domain에서는 어렵고 frequency domain으로 옮기면 각각의 신호를 파악하기 쉽다. 이 중에서 필요한 신호만 취하고 나머지는 버리면 특정 음성신호만 뽑아낼 수 있다
spatial domain에서 frequency domain으로 옮기기 위해서는 푸리에 변환을 적용해서
real part imaginary part가 존재하는 복소수 도메인으로 옮긴다.
복소수 도메인에서 real part만 취해서 중에서 cosine변환하는것이 cosine transform이다.
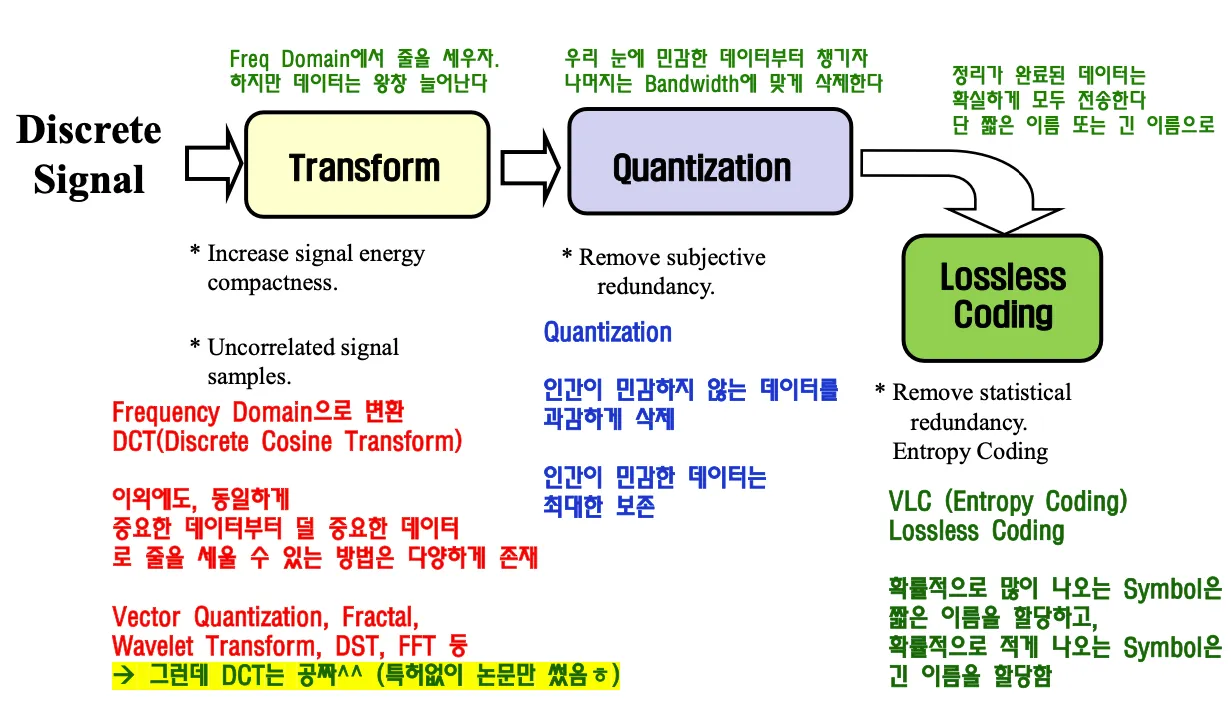
줄을 세운 이후 민감한 데이터부터 챙기고 나머지는 bandwidth에 맞게 삭제한다.
frequency domain으로 변환하는 과정이 DCT이며 그 과정에서 푸리에 변환을 사용하는데 푸리에 변환은 real part와 imaginary part가 있는 cosine + sine 변환이므로 그 중에서 real part인 cosine transform만 취한다. frequency domain으로 변환하는 방법은 여러가지가 있지만 DCT는 특허가 없어서 무료이기 때문에 많이 사용된다.
DCT로 frequency domain으로 줄을 세우고 quantization으로 인간에게 민감하지 않은 데이터를 삭제하면서 lossy하게 데이터를 줄이고 vlc로 loss없이 데이터를 엔트로피 코딩한다.
동영상 코덱은 여기에서 motion estimation 과정까지 들어가고 정지영상은 들어가지 않는다.
인간이 민감하게 반응하는 데이터는 low frequency에 모인다.
푸리에 변환 대신 cosine transform사용하는 이유는 복잡한 계산을 피하기 위해서도 있다.
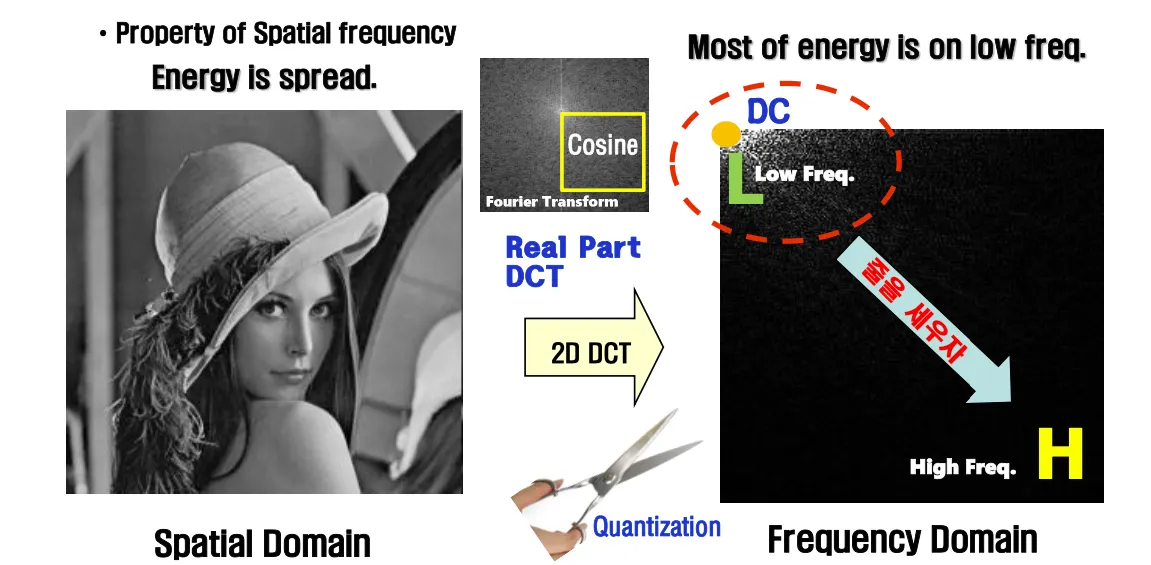
DCT는 영상으로부터 Frequency Domain으로 바꾸는 과정이며
Inverse DCT는 Frequency domain에서 영상으로 바꾸는 과정이다.
DCT는 영상의 픽셀을 coefficient로 바꾼다.
c(u)는 상수값이며 m은 x축, n은 y축을 뜻한다.
m을 u로, n을 v로 치환하는 과정이다.
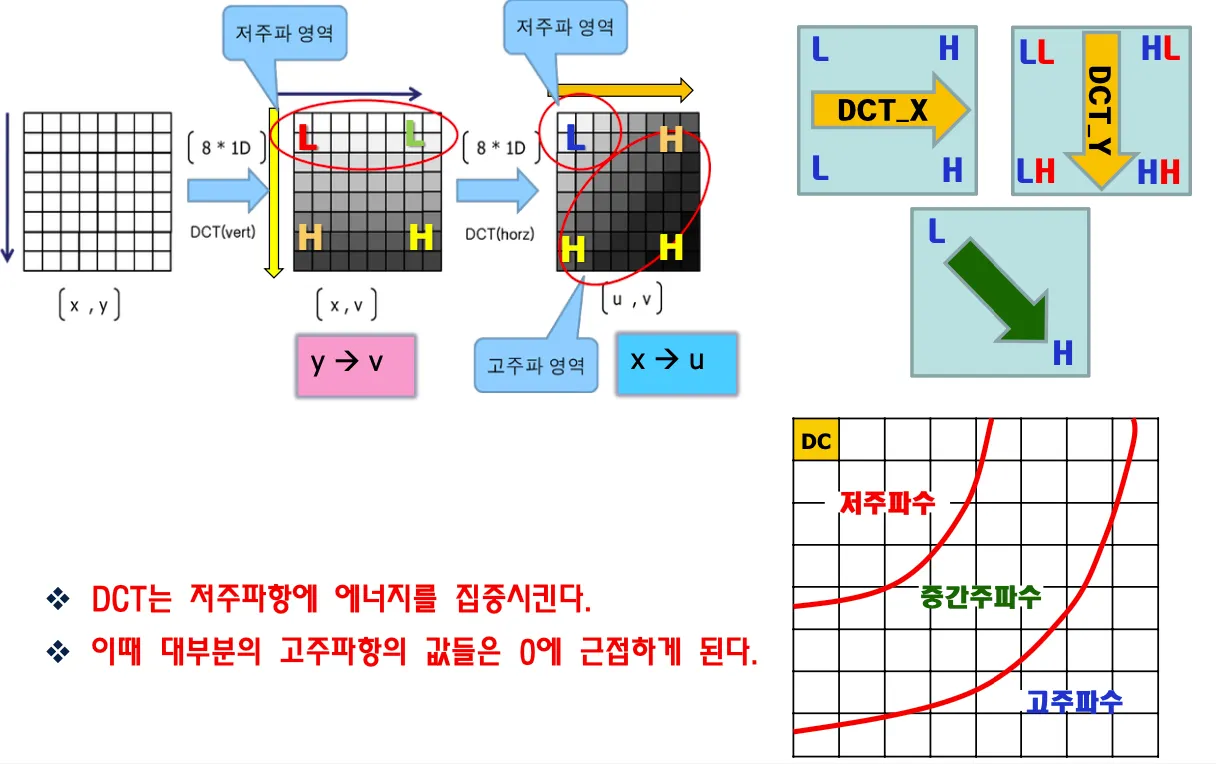
위에서 아래로, 왼쪽에서 오른쪽으로 줄을 세우는 과정을 거치며
y축으로 cosine transform을 먼저 취하면 y가 v로 바뀌고 위에서 아래로 줄을 세운것과 같다.
그 데이터를 다시 x축으로 cosine transform하면 x가 u로 치환되고 왼쪽에서 오른쪽으로 줄을 세운것과 같다.
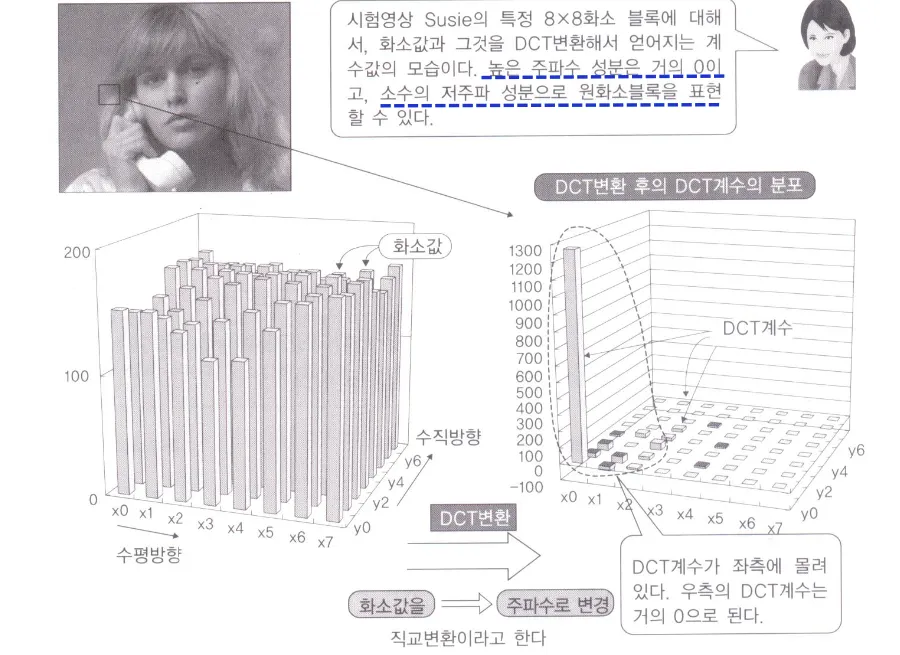
DCT는 저주파항에 에너지를 집중시키고 대부분의 고주파항들의 값은 0에 근접한다
경계파트 step function머리카락 등도 대부분은 경계 안의 면적에 존재하고
edge파트가 고주파항이고 많은 고주파항들의 조합이므로 데이터를 많이 쓴다.
DC는 pixel들의 mean값으로 나머지는 차들로 표현함

높은 주파수 성분은 거의 0이고 소수의 저주파 성분으로 원래 화소블록을 표현할 수 있다.
즉 화소값을 주파수로 변경하는것이 DCT변환이다.
오른쪽아래 잘라버리고 만들어도 사람 눈에는 비슷하게 보인다.
Quantization
Quantization은 스칼라 양자화라고도 한다.
DCT의 결과는 char 데이터를 double로 늘린 것이다.
quantization을 통해 lossy하게 데이터를 압축해야한다.
truncation하는 방법으로 특정수로 나누고 나머지는 버릴수도 있고 반올림할수도 있다
53/3 = 17.67 17과 3을 보내서 복원할때는 17*3 = 51 ⇒ 데이터 손실 발생
중요한 정보는 작은수로 나누고 덜 중요한 정보는 큰수로 나누어서 몫 값만 전송
원본 데이터와 다르다고 해도 인간이 다른점을 인지하지 못하면 성공이다.
인간이 이미지를 인지하는데 저주파항의 데이터가 고주파항보다 더 중요하다.
고주파항을 대부분 0으로 만들어 데이터 양을 줄일 수 있다.
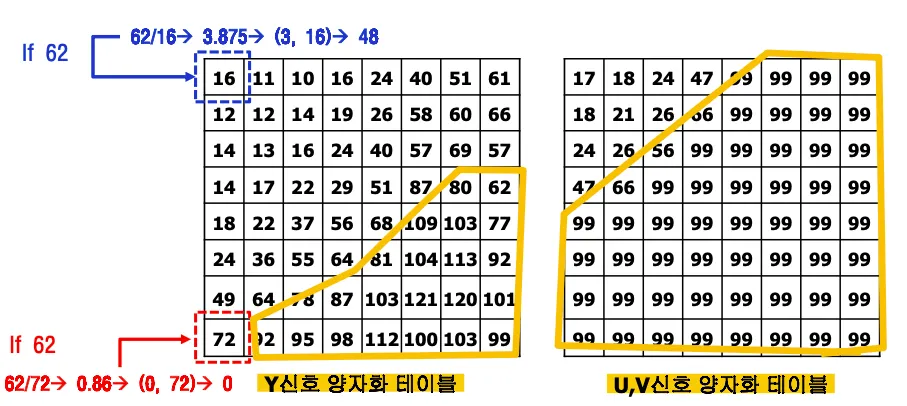
중요한 데이터인 저주파 항은 작은 수로 나누고 고주파 항은 큰수로 나누어서 대부분 0으로 만든다.
인간의 눈이 인식하지 못하는 높은 주파수의 DCT계수들은 거의 0이 된다.
양자화 값은 표준으로 정해지지 않아서 자체적으로 정의한 값을 사용하면 된다.
Y신호는 민감하게 반응하므로 luminance파트는 작은 수로 나누고 민감하지 않은 색차(chrominance)파트는 큰 수로 나눈다.
양자화한 이후 zigzag스캔을 통해서 1차원 coefficient를 구한 후 entropy encoder로 보낸다.
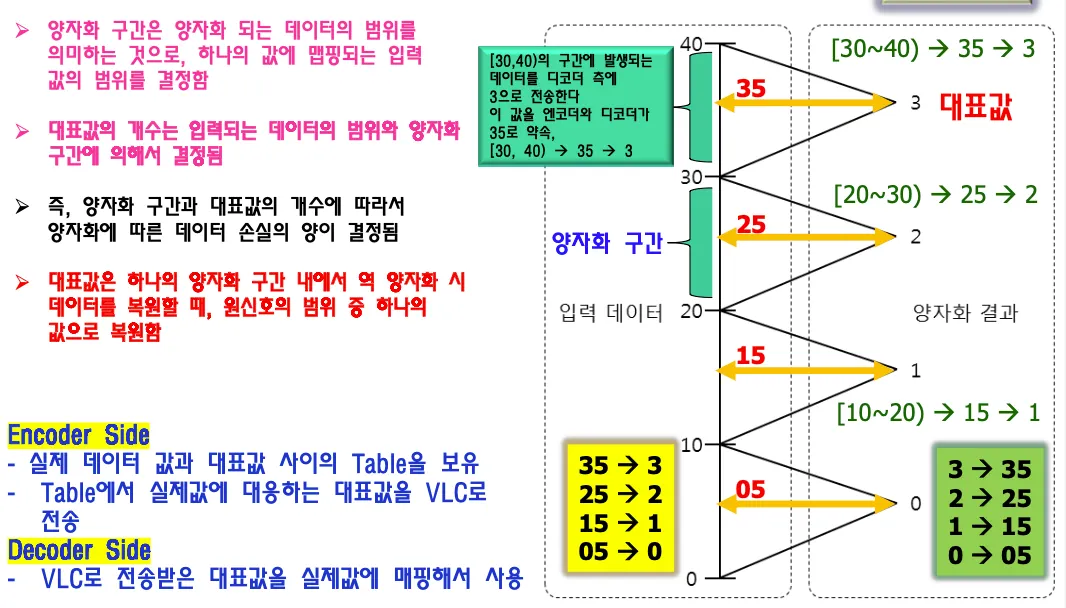
구간양자화
구간별로 대표값 데이터를 정해서 보내는 방법이다.
laplacian분포를 보고 많이 편중된 값을 대표값으로 정할수도 있다.
인코더와 디코더간의 약속이 있어야 하며 디코더는 vlc로 전송받은 대표값을 실제값에 매핑해서 사용한다.
양자화 구간과 대표값의 개수에 따라서 데이터 손실량이 결정된다
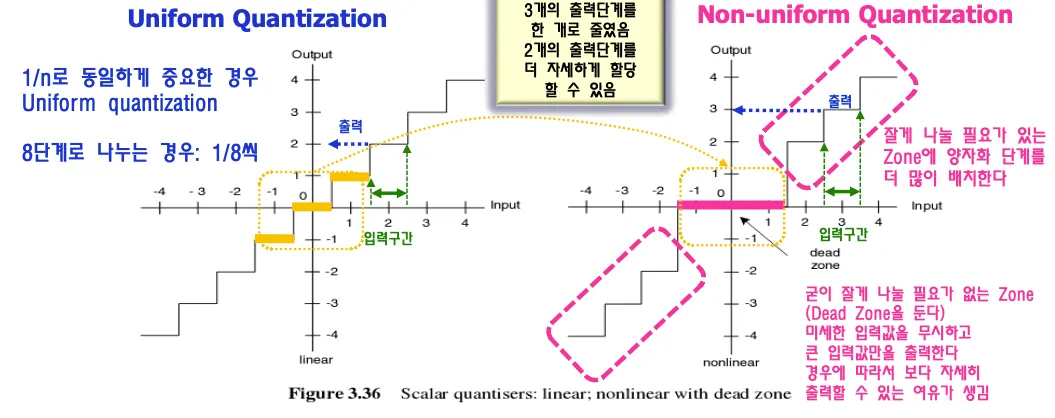
uniform quantization과 non uniform quantization이 있다.
모든 구간이 다 중요하면 모든 구간에 대해서 동일하게 대표값을 정해야 하지만 uniform하게 나누면 중요한 데이터 부분에서 구간을 많이 나누고싶어도 나눌 수 없다. 그래서 중요한 부분을 세밀하게 나누고 중요하지 않은 부분은 나누지 않는 방법이 non uniform 방식이며 더 정확하게 데이터를 보낼 수 있다.
dead zone 양자화: 0으로 처리하는 구간을 넓히고 다른 구간은 조밀하게 구분한다.
DCT+Quantization
DCT(Discrete Cosine Transform)에서 이미지를 8x8 픽셀 크기의 작은 블록으로 나누어 각 블록에 대해 변환을 수행한다.
예를 들어, 만약 이미지의 크기가 256x256 픽셀이라면, 이 이미지는 총 256/8 x 256/8 = 32 x 32 = 1024개의 8x8 블록으로 나누어진다. 각 블록에 대해 DCT를 적용하여 주파수 도메인으로 변환하고, 이를 통해 압축이나 특성을 추출할 수 있다. 양자화 이후에는 zigzag스캔을 활용해서 데이터를 스캔한다.
raster스캔은 왼쪽에서 오른쪽으로 순차적으로 스캐닝하는 방법인데 이 방법을 사용하지 않고 zigzag스캔을 사용하는 이유는 0의 개수를 줄일 수 있기 때문이다. EOB End of block이다.
고주파항이 많으면 zigzag스캔에서 생략할 수 있는 값이 적어진다.
encoder는 DCT + Quantization과정을 수행하고 디코더는 reverse quantization + inverse DCT를 수행함
lossy encoding이기 때문에 reconstructed된 영상은 원본과 다르다. 하지만 보기에는 비슷하다.
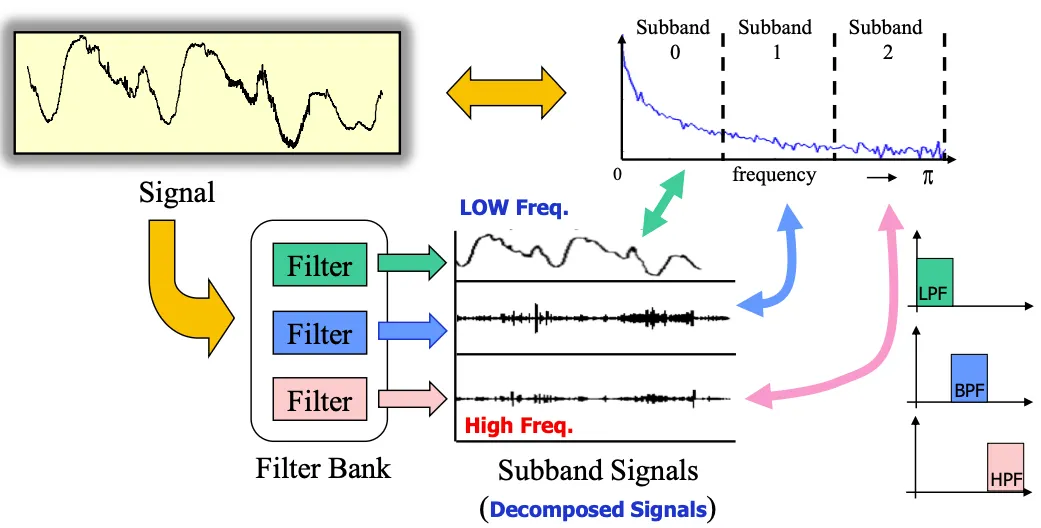
Subband Transformation
DCT외에 다른 방법으로는 subband transformation이 있는데 bandwidth를 세 개의 subband로 나눠서 시그널을 필터를 통해서 decompose한 다음 더하는 방식이다.
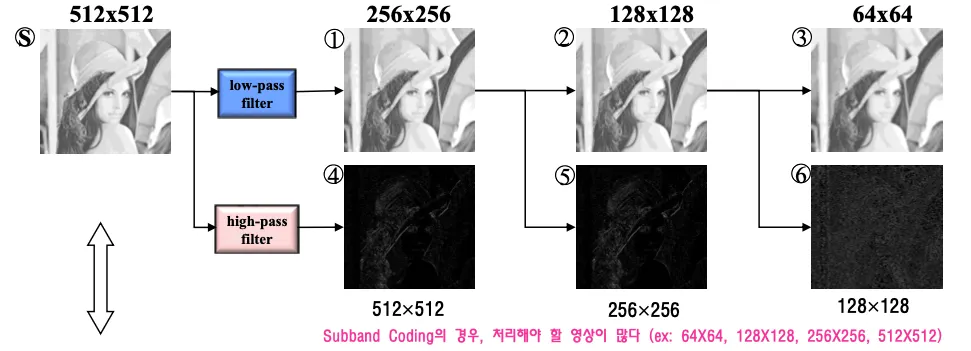
512x512의 영상이 있을 때 low pass filter와 high pass filter를 통해서 고주파항들만 걸러낸 차영상을 만들고
64x64 영상을 시드로 해서 bandwidth 허용치에 따라서 차영상들을 하나씩 더해가면서 점점 선명하게 만든다.
줄을 세워서 덜 필요한 정보를 잘라내는것과 비슷한 개념이다. 단점으로는 처리해야 할 영상이 너무 많다.
Wavelet transformation
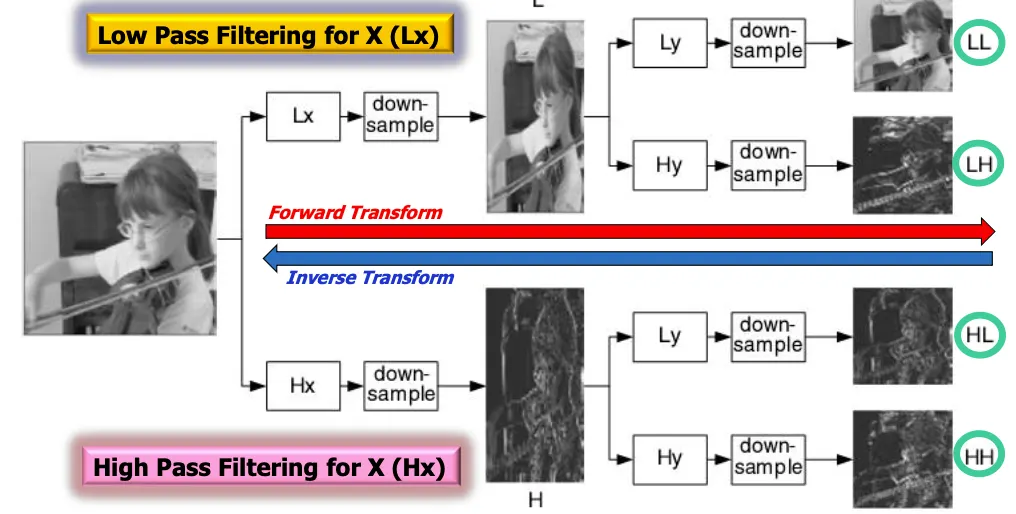
동일한 작업을 동일크기의 영상정보에서 처리하기 위한 방법.
영상을 각각 low pass filtering, high pass filtering한 다음
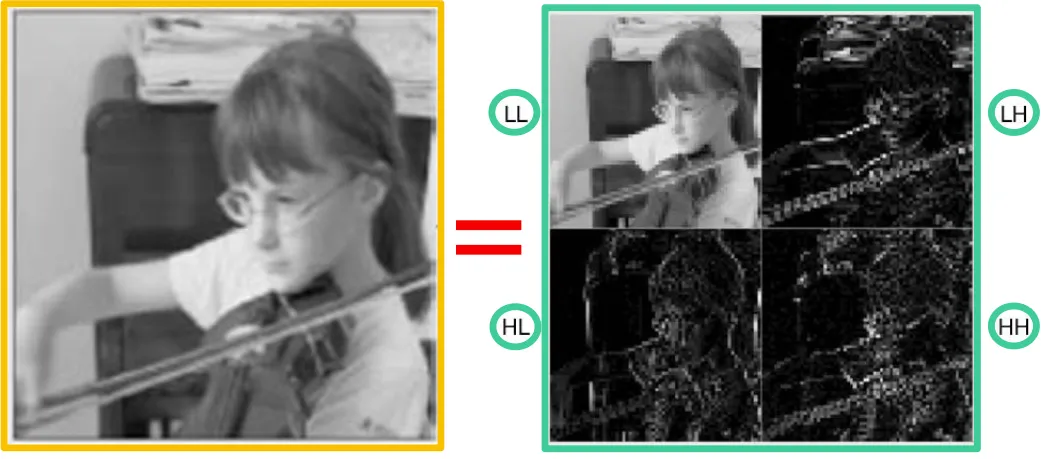
x축, y축으로 다운샘플링하면 1/4크기의 영상이 생성된다. 512x512영상이었다면 256x256영상이 4개 생성된다. LL이 가장 중요한 영상이고 HH가 가장 덜 중요한 영상이다.
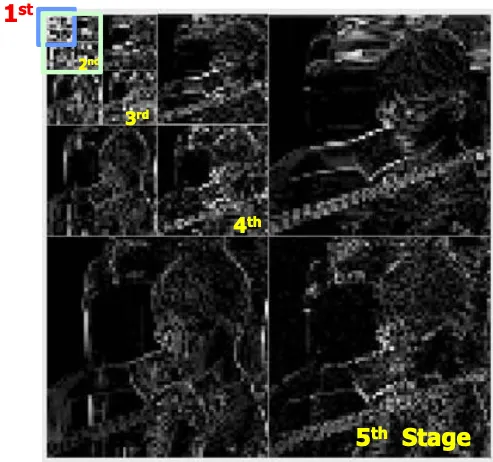
보다 정밀하게 하려면 스테이지 수를 늘려서 이 과정을 여러번 수행한다.
low pass에서 가장 많은 시그널을 가지고 있고 고주파항들은 0을 중심으로 laplacian형태의 데이터를 갖는다.
정지영상일 경우 성능이 굉장히 좋아서 jpeg에서 사용하는 방식이다. 하지만 video에서는 ghost effect가 발생해서 사용하지 않는다.
