
Bandwidth
대역폭은 단위 시간당 데이터의 전송량을 의미하며 초당 프레임 개수, 프레임 해상도, 픽셀당 비트 개수를 곱하여 얻는다. 움직임이 자연스러운 영상을 표현하기 위해서는 최소 초당 15프레임 이상이어야 한다.
대역폭이 클수록 양질의 동영상을 재생할 수 있다.
프레임 데이터 크기 = 해상도 X 픽셀당 비트수
대역폭 = 프레임 데이터 크기 X 초당 프레임 개수
비디오 데이터 크기 = 대역폭 X 재생시간
4K UHD (약 4000 X 2000, 60fps, 30비트 컬러(10bitX3)) 영화 2시간 상영을 위해서 필요한 비디오 데이터의 크기는?
4000 X 2000 pixels X 30 bit/8 = 30,000,000 Byte = 30,000 KB = 30 MB
30 MB X 60fps = 1800 MB = 1.8 GB
1.8 GB X 60 sec = 108 GB
108 GB X 60 Min = 6,480 GB = 6.48 TB
6.48 TB X 2 시간 = 12.96 TB
압축하지 않으면 데이터가 너무 크기 때문에 비디오는 압축을 적용하는게 필수.
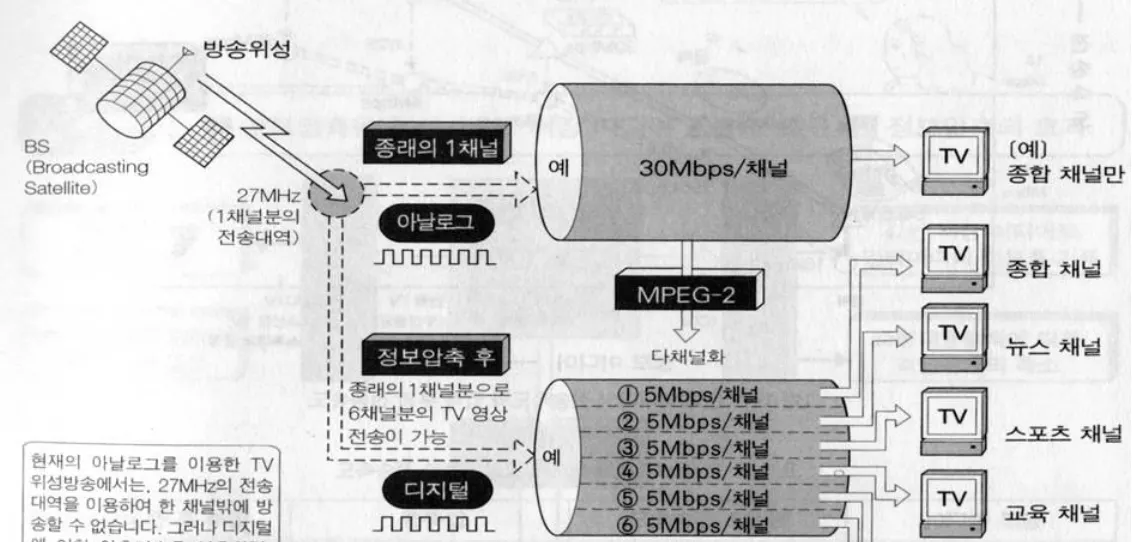
압축을 사용하면 동일한 네트워크 bandwidth에서 훨씬 많은 사용자들에게 서비스를 제공할 수 있고 비용을 저렴하게 만들 수 있다.
Codec
비디오 인코딩 = 압축하여 데이터를 줄이는 과정
비디오 디코딩 = 비디오를 재생하기 위해서 압축 이전의 상태로 되돌리는것
Codec = encoder + decoder
비디오 코덱의 종류: MPEG, AVC, HEVC, VVC 등.
이미지 표현
이미지는 pixel로 구성됨. 픽셀 하나는 rgb서브픽셀로 구성됨
bitmap = 전체영상의 pixel의 2차원 배열
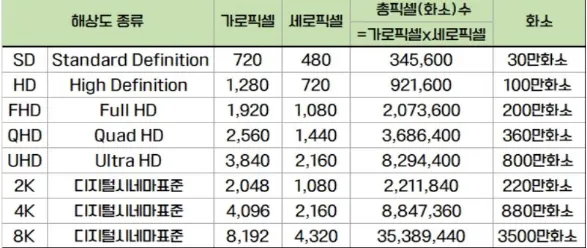
image resolution = 디지털 영상에서의 pixel개수, 해상도. 높은 해상도는 항상 좋은 화질을 가짐
종횡비(aspect ratio) : 4:3, 16:9 21:9(ultra wide)가 일반적이다.
frame buffer = 대용량 영상을 고속으로 보여주기 위한 그래픽 카드
1bit binary image
각 픽셀은 0 or 1로 표현하는 color를 포함하지 않는 monochrome 이미지. 단순한 이미지나 텍스트에 사용함.
8-bit gray-level image
각 픽셀을 한개의 바이트로 256가지의 gray value를 가짐. 각 픽셀은 하나의 바이트로 표현된다. 8bit영상은 1-bit bitplane의 집합으로 생각할 수 있다. 각 단계에서는 1비트로 표현한다는 뜻이다.

MSB에 가까워질수록 더 중요한 정보를 나타내고 LSB는 디테일한 부분을 나타냄.
24-bit color image
color는 각 rgb당 3바이트가 필요함. 각 구성요소의 표현범위는 0255이므로 1670만가지 색상을 표현할 수 있음
저장공간의 penalty가 존재함
4k image는 각 color당 10bit의 depth를 가짐
UHD의 경우도 rgb각 색상을 10비트로 표현해서 30비트를 사용하기도 한다. 따라서 10억개의 색상을 표현가능.
하지만 인간은 색상을 50만개밖에 구분할 수 없기 때문에 압축하는 기술을 사용할 수 있다.

full frame body = 풀 프레임 센서 = 35mm아날로그 필름
crop센서 쓰면 crop body = 센서 크기가 작음
full frame은 이미지 센서의 크기가 커서 화각이 넓고 빛을 많이 받아서 심도가 우수하다. 노이즈를 적게타고 아웃포커스에 유리함(뒷배경 뭉개기)
crop 센서는 full frame에 비해 화각이 좁아서 작은 size영상을 입력받기에 최종 영상을 보는 입장에서는 동일한 영상이라도 zoom한 효과가 발생한다.
spatial/ temporal sampling
직사각형 형태로 sampling하며 직사각형 형태의 눈금의 교차지점에서 sampling을 수행한다.
sampling지점의 개수가 늘어나면 이미지 해상도가 올라간다.
spatial sampling은 정지영상을 샘플링하는 경우이고 temporal sampling은 동영상을 샘플링하는 경우이다.
동영상은 spatial, temporal sampling을 둘 다 수행한다.
4k영상 샘플링 = 4000*2800(픽셀개수)*1024**3(10비트 quantization)*60(초당hz)으로
동영상은 spatial temporal다해야한다
샘플링 많이 하면 해상도 올라가지만 complexity는 올라간다
얼마나 많이 샘플링하는지를 결정하는 것이 resolution이다.
QCIF SIF CIF VGA WVGA HD FHD QHD 4K-UHD 8K NK
Color Model
단파장 380nm부터 장파장 780nm까지가 인간이 볼 수 있는 빛의 영역이다. 따라서 보이지 않는 자외선이나 적외선 영역은 데이터화 할 필요가 없다.
하나의 컬러 모델로 모든성질 설명 불가능하기 때문에 3가지 종류의 컬러 모델을 사용한다. rgb cmy hsv
rgb는 빛의 삼원색, cmy는 물감의 삼원색이고 HSV는 인간의 시각 시스템과 유사한 컬러모델이다.
빛의 진폭은 밝기를 결정하고 파장은 빛의 색상을 결정한다.
진폭이 클수록 밝은 빛이고 파장이 짧으면 보라색 길면 빨간색에 가까워진다.
rgb삼원색 체제를 인간이 구분 가능한 이유는 인간의 눈에 6~7백만 원추세포가 있기 때문이다. 원추세포의 비율은 빨간색이 65%, 초록 33%, 파랑 2%이다.
rgb색을 섞을수록 밝아지는 혼합을 가산혼합이라고 하며 픽셀 하나에 3개의 색상이 모두 들어있다
한 픽셀에 1바이트*3이므로 24비트가 들어있는것을 true color라고 함.
구분하지 못할정도로 굉장히 비슷함. rgb비슷하지만 중복성이 굉장히 높다
cmy
cmy는 청록 심홍 노랑으로 이루어지고 하나의 색에서 다른색을 제거함으로써 다른 색상을 생성하는 감산 모델. 색을 섞으면 어두워진다. white source = 1, 1-r = c
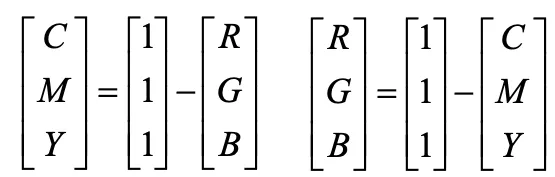
cmyk는 kappa(검은색)을 더한 모델. 검은색을 만들려면 기본 색의 낭비가 심하기 때문에 4개의 카트리지 사용.
hsv = hsi = hsb
hue, saturation, brightness
hsv는 인간 시각시스템 연구한 결과 명암에 굉장히 민감한데 색차에는 매우 둔감하다는 것을 고려해서 색상 채도 명도의 세가지를 가지고 인간의 시각시스템을 정의한 모델. 명암은 많은 정보를 주고 색상, 채도는 많은 정보 제거해도 인지하지 못하므로 압축해도 된다.
yuv
yCbCr모델
인간의 시각 시스템은 명암에 가장 민감하고 색차신호(UV,Chrominance)에는 둔감함
Y = 휘도신호(Luminance), U,V = 색차신호
U = Blue - Luminance = Cb
V = Red - Luminance = Cr
Cg = Green - Luminance인데 YCbCr만 전송하면 계산해낼 수 있다.
흑백방송 정보는 그대로 두고 컬러방송 신호를 보내서 섞으면 컬러방송이 되도록 할 수 있다. 흑백TV에서 수신하는 UV신호는 잡음이다. 방송구겡서는 한개의 신호로 컬러와 흑백TV를 모두 시청하게 할 수 있다.
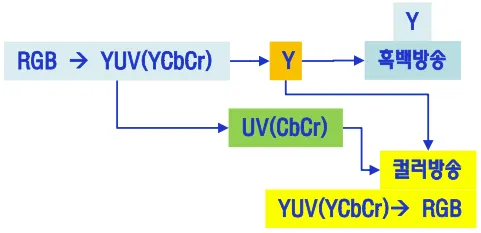
rgb생상은 모든 컬러 성분이 동일 해상도로 저장되지만 YCbCr은 Y가 훨씬 민감함
rgb를 yuv로 만들 수 있고 역도 가능함. 정해진 Linear matrix를 따라서 변환하면 된다.
RGB정보를 YUV로 바꿔서 전송하고 다시 RGB로 복원하는 형식으로 사용
YUV down-sampling
인간은 색차정보에 둔감하므로 정확하게 재현할 필요가 없고 색차정보의 정보량을 줄이기 위한 기법
u,v데이터 줄이려면 다운샘플링으로 4개를 하나로 만들고 rgb로 만들때 다시 업샘플링하면 된다
색차신호의 정보량을 줄여도 인간에게 동일하게 보이기 때문.
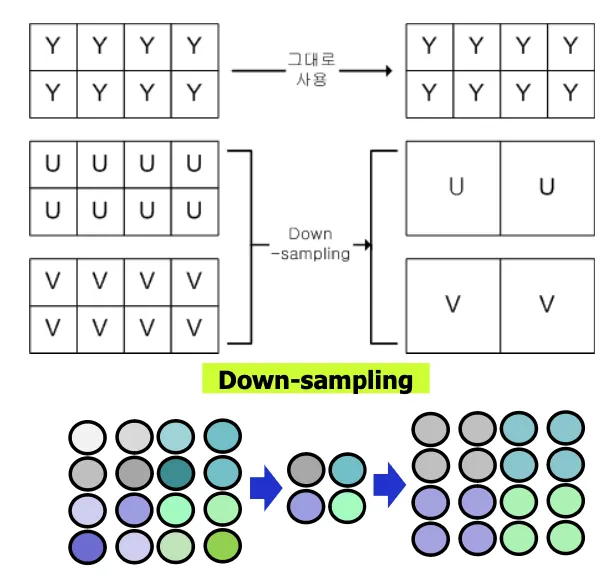

4:2:0포맷은 4개의 spot당 한개의 chrominance를 부여하는 방법으로 일반적으로 많이 쓰인다.
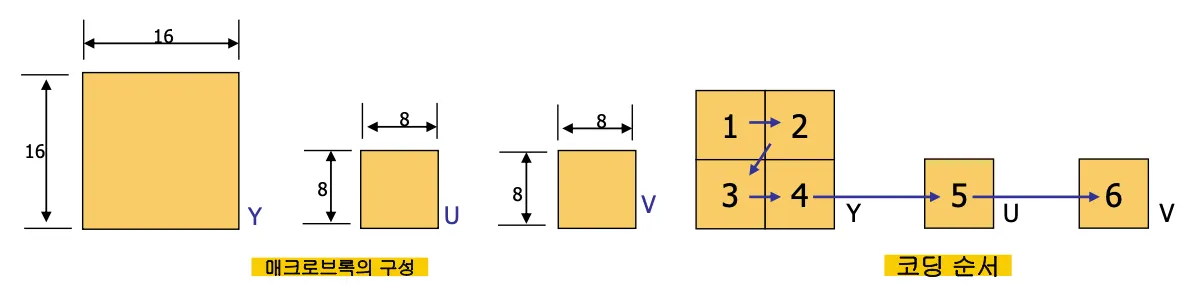
옛날에는 하드웨어 문제로 영상을 처리할 수 있는 최대 단위가 8x8이었다.
y는 4개의 8x8로 처리하고 u,v도 8x8을 기본단위 처리한다.
y는 4개의 8x8블록으로 이루어지며 이를 매크로블록이라고 부름.
이미지 압축방법
한 화소당 데이터를 줄이는 방법과 이미지를 구성하는 화소수를 줄이는 방법, 데이터를 압축하는 방법이 있음
한 화소당 데이터를 줄이는 방법은 msb부터 lsb까지 1-bit비트플레인을 만들고 msb를 우선으로 보내고 더 필요한 경우 다음 비트플레인을 보내는 방식
이미지의 화소수를 줄이는 방법은 4개 픽셀을 하나로 다운샘플링하는 방법. 계단형태로 보이는 엘리어싱이 발생할 수 있음.
데이터 압축을 위해서 인간의 시각적인 특성을 이용해서 시각적인 영향이 적은 부분의 정보량을 줄인다. 이웃한 화소들의 유사성(중복성)을 이용한다. 대표적으로 GIF, JPEG등이 있다. (정지영상 압축)
비디오 데이터 압축

비디오 소스를 인코딩해서 비트스트림으로 만들어서 전송하고 디코딩해서 다시 영상으로 만든다.
CODEC = encoder+decoder
데이터를 전송할 때 적은 수의 비트로 압축하는 과정이 있어야 효율적으로 저장하고 전송할 수 있다.
무손실 압축은 3-4배의 압축효과가 있다
손실 압축은 더 높은 압축률을 가지고 퀄리티는 감소하지만 크게 인식못할 정도로 중복 요소를 제거한다
Video Sequence
Frame rate가 높을수록 temporal correlation이 높음 (시간적 유사성)
spatial corrleation은 이웃하는 샘플과 유사성이 높음.
비디오 압축 원리는 spatial, temporal redundancy를 제거하는 것.
확률적 편중을 이용해서 많이 나오는 케이스에는 데이터를 줄여서 보낸다. 부호의 발생확률이 높은 심볼들의 이름을 짧게해서 보내고 발생확률 낮은 심볼은 긴 이름 붙여도 큰 차이가 없다 = VLC(variable length coding)
정보압축 기본원리
1.
화면내 공간적 상관관계에 따른 압축
인접한 픽셀간의 값은 거의 비슷함. DCT, Wavelet등의 변환 부호화와 양자화, DPCM적용 등.
2.
화면간 시간적 상관관계에 따른 압축
일반적으로 인접한 두 개의 영상은 유사한다. Motion Estimation 및 Motion Compensation사용
3.
부호의 발생확률 편중에 따른 압축
Entropy Coding을 사용 ⇒ Run Length Encoding, VLC, Arithmetic Coding
Spatial Redundancy of Image Signal
주변 pixel간의 correlation이 매우 높다 = stongly correlated.
image signal들의 energy는 저주파항에 집중되어있다.
주변픽셀값과의 차이가 거의 없다 = 중복성이 높다.
correlation이 낮은 영상은 잡음으로 보인다.
가장 기본적은 compression 방법은 DPCM이다(differential pulse code modulation).
DPCM
공간적인 중복성을 제거하는 방법으로 기준픽셀을 주변의 각 픽셀값에서 빼면 laplacian분포를 보인다(가우시안 아님). 공간적 중복성이 높고 주변픽셀값이 유사할수록 0 가까이에 모이므로 확률의 편중에 따른 방법을 적용할 수 있다.
DPCM은 인접화소 간 difference를 취하는 것이다. redundant한 데이터를 줄이고 0 주변에 데이터가 모여있다. Lossless한 인코딩 과정이다. 즉, loss없이 원본으로 복구할 수 있다.
DCPM만 처리하면 데이터가 오히려 늘어나며 Entropy coding을 적용해야 압축된다.
DPCM결과는 평균이 0이며 -256에서 255의 Laplacian Distribution을 가진다.
DPCM을 적용하면 전송선로 상에서 발생하는 에러에 취약해진다. Error propagation이 발생하기 때문에 전파를 방지하는 방법이 필요하다.
주변 화소간 중복성이 높은 경우 DPCM의 결과가 0을 중심으로 매우 좁은 분산을 가진 Laplaician형태로 나타나지만 화소간 중복성이 없는 Random Data의 경우 DPCM결과는 Uniform Distribution이 되고 데이터를 압축할 수 없다.

Entropy Coding
부호의 발생확률 편중을 이용한 압축방법으로 발생확률이 높은 값에 길이가 짧은 부호를 할당하고 출현확률이 낮은 값에 긴 부호를 할당한다.
DPCM만을 수행하는것은 의미가 없다. VLC를 거쳐야 데이터를 줄일 수 있다.
모든 데이터에 unique한 이름이 있어야 한다. DPCM으로 차를 계산하면 음수도 나오므로 픽셀 한개당 9비트로 오히려 데이터 양이 늘어난다.
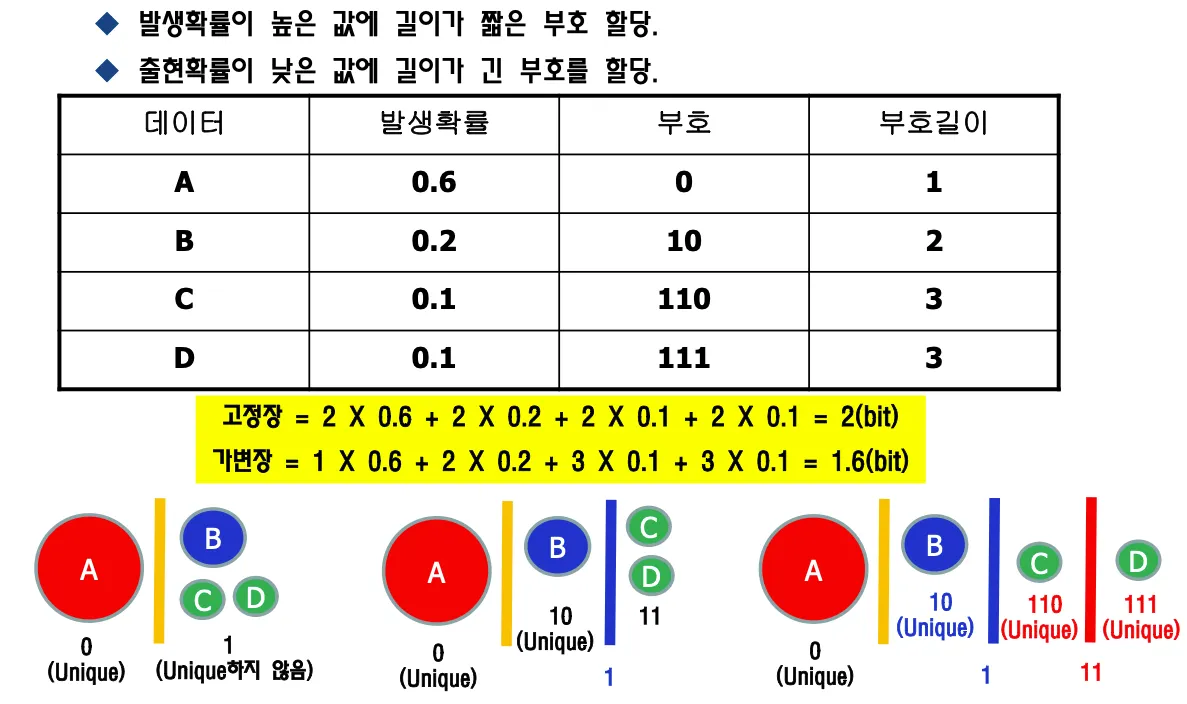
prefix coding은 맨 앞자리로 symbol을 구분하는 방법이다. 가변길이 코딩으로 20프로 줄어들었다.
Frequency Domain으로의 변환
인간의 시각적 특성을 이용해서 원본이라고 생각할정도로 감쪽같이 속이고 데이터양을 줄이는 것이 목표이다.
인간에게 민감한 데이터는 정확하게 보내고 민감하지 않은 데이터는 삭제하거나 줄이면 된다.
관심있는 데이터를 순서대로 줄을 세우고 관심없는 데이터는 뭉개버려도 원본과 유사하게 보이므로 줄을 세워서 관심없는것부터 잘라내면 된다. 인간은 저주파항의 데이터에 민감하다.
줄을 세우기 위해서는 frequency domain으로 변환하는 과정이 필요하다.
데이터를 sine wave로 변환할 수 있고 sine wave들을 더해서 값이 급격하게 변하는 edge를 만들 수 있다.
Temporal Redundancy
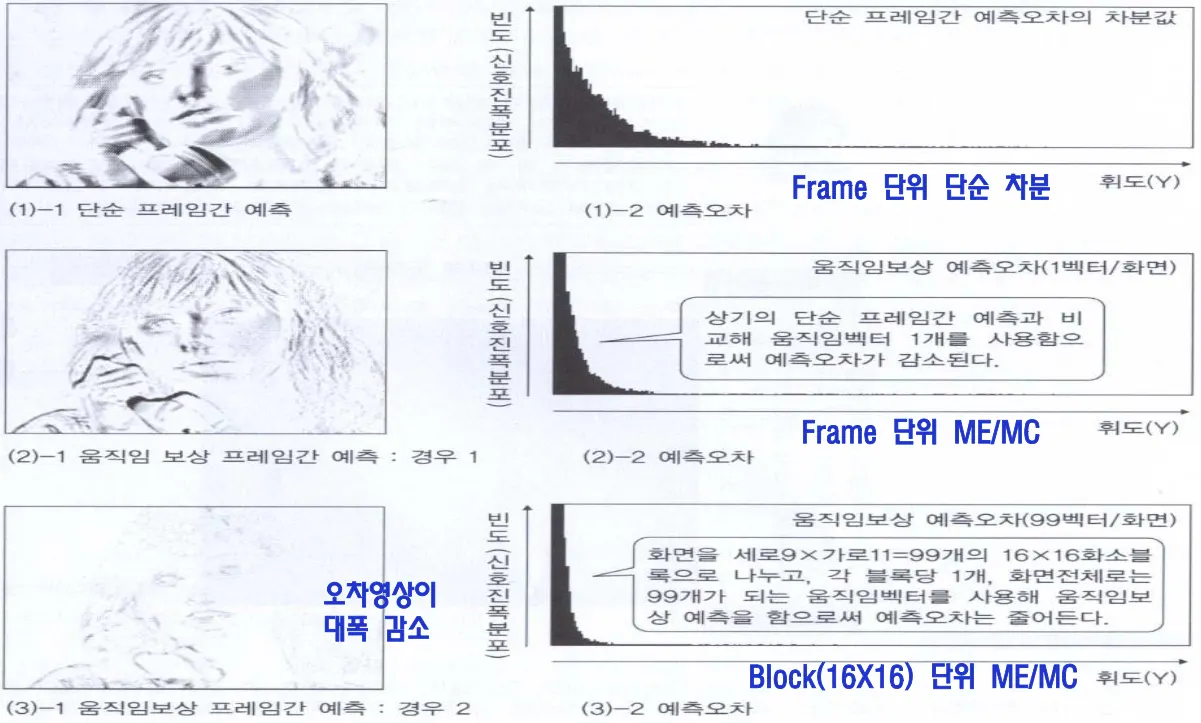
영상 프레임 간의 유사성 = redundancy가 높다. 다음 프레임과 비교하는 경우 많은 화소값이 동일함.
전 화면의 정보를 이용하면 직접 화소를 보내지 않고 벡터와 관련된 정보만으로 같은 영상을 표현할 수 있다.
영상에서 이전 프레임 f0과 다음 프레임 f1사이의 차 f1-f0을 차영상 residual이라고 한다
f0과 f1-f0를 보내면 다음 사진을 만들 수 있다.

하지만 움직임이 있는 객체의 경우 많은 잔여신호가 남아있고 급격하게 값이 변하는 edge는 가급적 만들지 않아야 데이터의 양을 줄일 수 있다. 이를 위해서 motion compensation을 사용한다.
motion estimation = 어떤 요소가 움직였는지 판단.
motion compensation(움직임보상) = 블록을 잘라서 부분적인 움직임의 motion vector를 구함.
f1-f0이 0이면 완전히 동일한 영상이고 아니면 residual이 생기는데 움직임 벡터와 residual을 받아서 f1을 만들 수 있다.
예를 들어 모양은 똑같은 야구공이 위치만 변하면 야구공의 움직임벡터와 두개의 영상의 차(residual)을 보내줘서 구현한다.
f1-f0의 절댓값을 취하면 다른부분만 나타난다. f0+ difference를 보내서 집을 보내지 않아도 되고 이전 야구공을 다음 야구공 구현에 쓸수 있다면 모션 정보만 보내고 야구공 데이터를 안보내도 되는것이다.
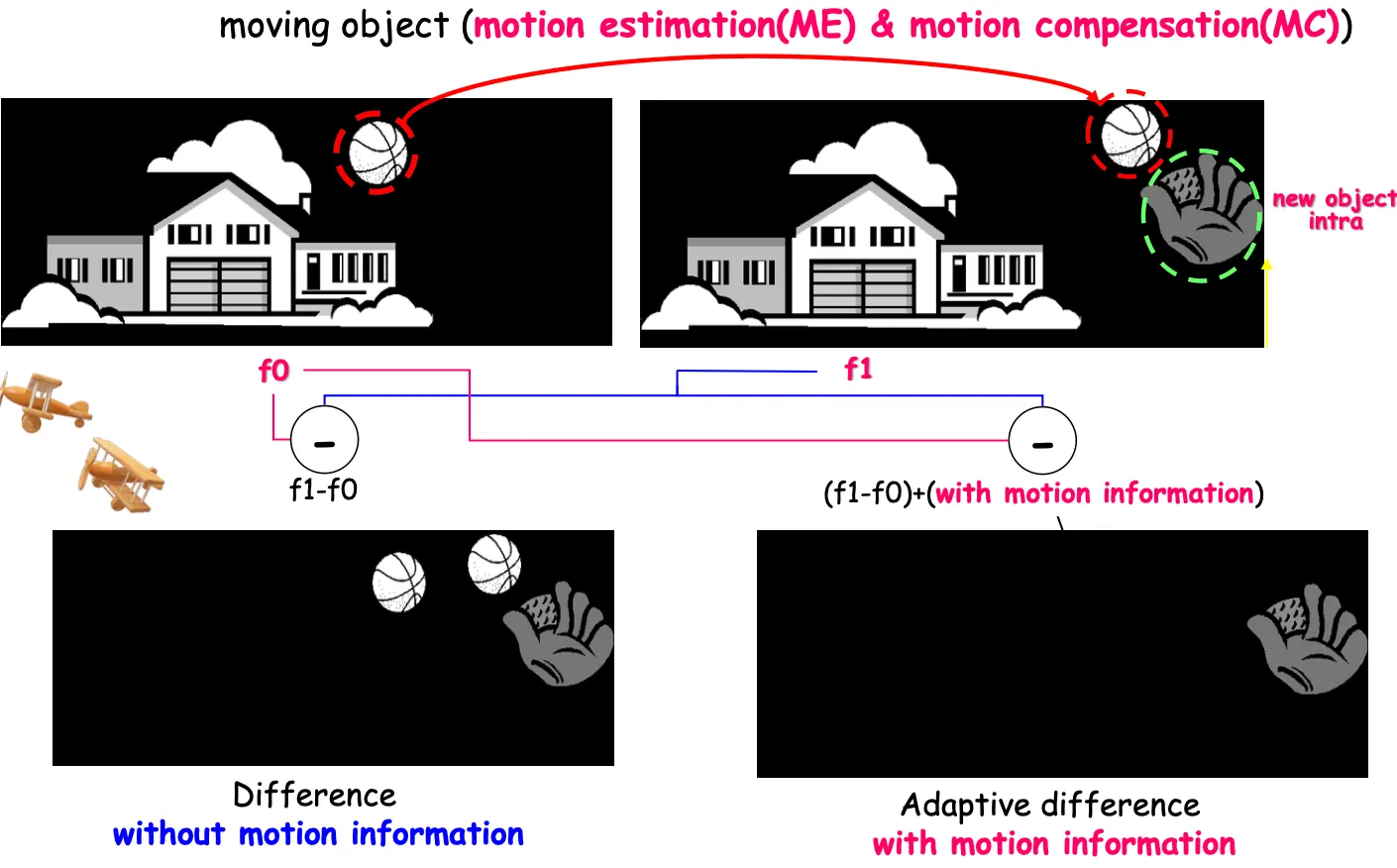
motion vector란 x축, y축으로 얼마나 움직였는지를 계산한 벡터로 difference만을 보내는것보다 모션벡터를 같이 보내면 오차를 감소시킬 수 있다.
영역의 칸을 나눠서 영역별로 모션벡터를 보내면, 예를 들어 화면을 99개 블럭으로 나누고 99개의 벡터를 보낸다고 하면 예측오차를 더 줄일 수 있다.
예측오차가 impulse function으로 나오는게 가장 이상적이지만 불가능하며 laplacian 분포의 폭을 줄여나가는게 중요하다.
Video Codec의 기본구성
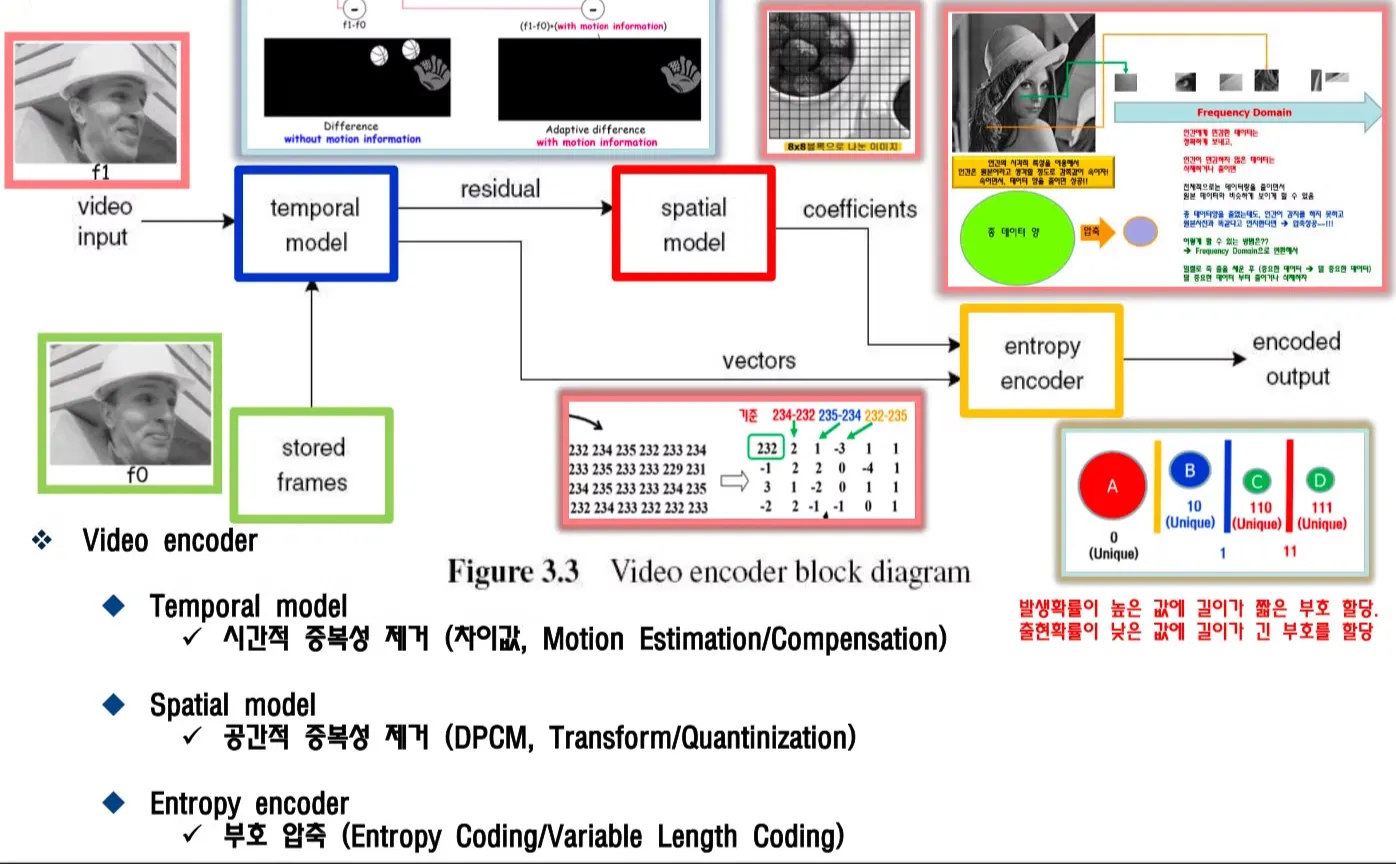
video input으로 f1 영상이 들어오면 temporal model에서 저장되어있던 이전 프레임인 f0을 활용해서 motion estimation과 motion compenstation을 이용해서 시간적 중복성을 제거하고 residual(차영상)을 spatial model로 보내주고, motion vector는 entropy encoder에 보내준다.
stored frame은 원본영상이 아니라 비트스트림으로 전송했던 이전 프레임이 reconstructed된 영상이다.
spatial model이 DPCM을 통해서 차영상 = residual의 공간적 중복성을 제거하고 coefficient를 entropy encoder에 보내준다.
entropy encoder는 motion vector와 coefficient를 variable length coding을 통해서 부호를 압축해서 비트스트림으로 데이터를 전송한다.
