
Instructions
instruction: words(commands) of computer’s language
Instruction set: the vocabulary of commands understood by a given architecture
MIPS
microprocessor without interlocked pipeline stages
Instruction set Architecture의 일종
컴파일러가 high level 언어를 MIPS Assembly instruction으로 바꾼다
Arithmetic Operations
add, subtract instruction
한 줄에는 한개의 Instruction만 사용할 수 있다.
하나의 instruction은 3개의 피연산자(operand)를 갖는다.
add a, b, c # sum of b and c is placed in a
YAML
복사
맨 앞이dest, 뒤의 두개가 source. 모든 산술연산은 이 form을 따른다.
세 개의 operand로 사용되는 것은 32개의 register이다.
레지스터는 CPU안에 있는 speical location이다. 프로세서 안에 32개의 레지스터가 있고 각 레지스터 사이즈는 32비트이다. 32비트를 하나로 단위로 만든것이 word이다. 32비트 = 1word
레지스터 표현할때는 $을 쓴다. $s0 , $s1 등은 saved = 전역변수나 variable등을 저장함.
$t0은 temporary = function안에서 잃어버려도 되는 지역변수 등을 저장함.
operand로 사용되는 레지스터는 0번부터 31번까지 넘버링되어있음
레지스터가 너무 많아지면 CPU의 크기가 커져 clock cycle time을 증가시키기 때문에 32개만 사용함.

add $t0 $s1 $s2 # register $t0 contains g + h
add $t1 $s3 $s4 # register $t1 contains i + j
sub $s0 $t0 $t1 # 결과를 f에 저장
YAML
복사
Data transfer Operations
레지스터에 저장하는 데이터는 일시적이며 영구적으로 저장하려면 메모리에 저장하고 필요할때 다시 꺼내야 한다.
메모리와 프로세서간에 데이터 주고받는 과정이 필요하기 때문에 데이터를 transfer하는 명령어가 필요하다.
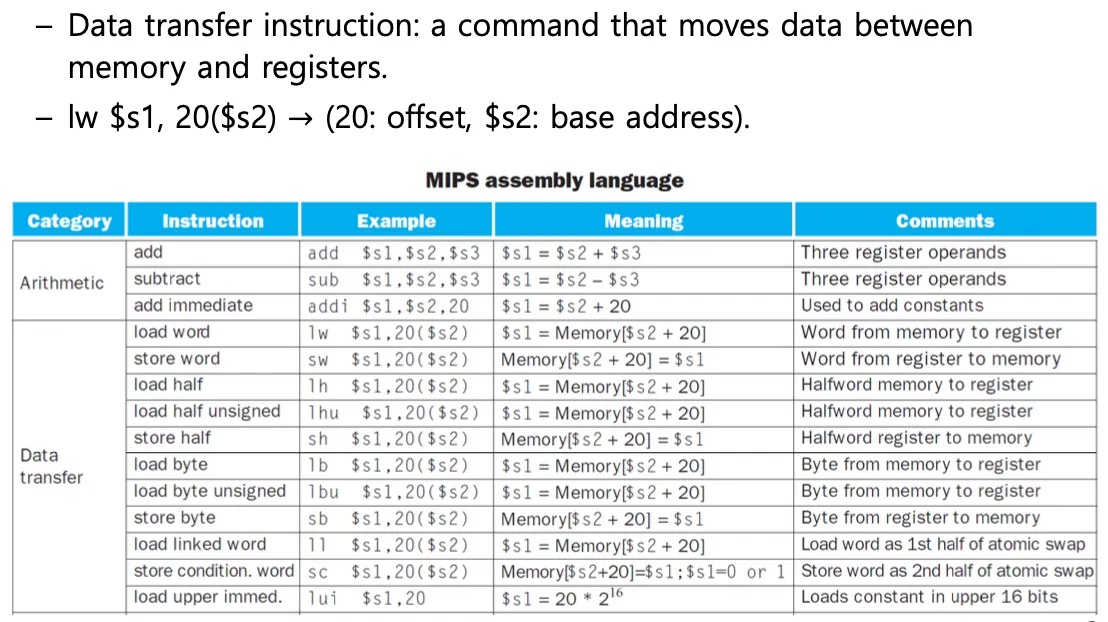
lw $s1, 20($s2)에서 괄호 안이 base address이고 숫자는 Offset이다.
destionation $s1에 해당하는 메모리주소로부터 데이터를 가져와서 저장한다.
프로세서에서 메모리로 보내는게 store word, 메모리에서 프로세서로 가져오는게 load word이다.
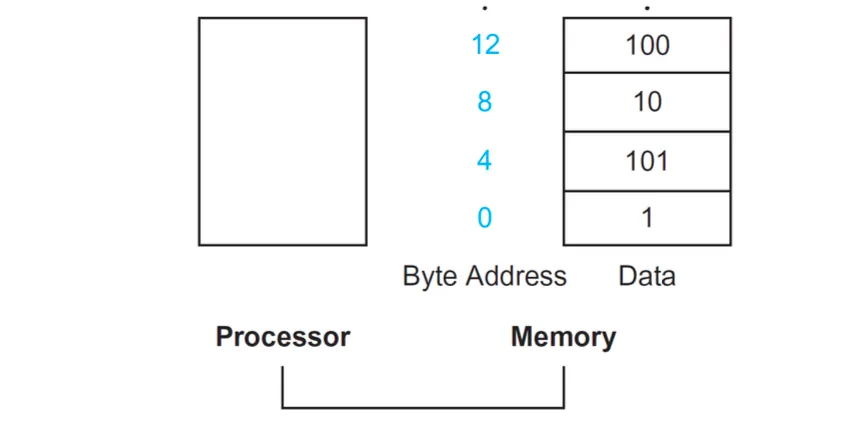
byte address는 4byte단위이다. 1 word가 4byte이기 때문에 레지스터 값을 저장하려면 4바이트 단위여야 함.
lw $s1 0($s2)이면 베이스주소에 있는 데이터를 가져오라는 뜻이고 offset 8이면 두칸 다음 데이터를 가져옴

lw $t0, 32($s3)
add $s1 $s2 $t0
YAML
복사
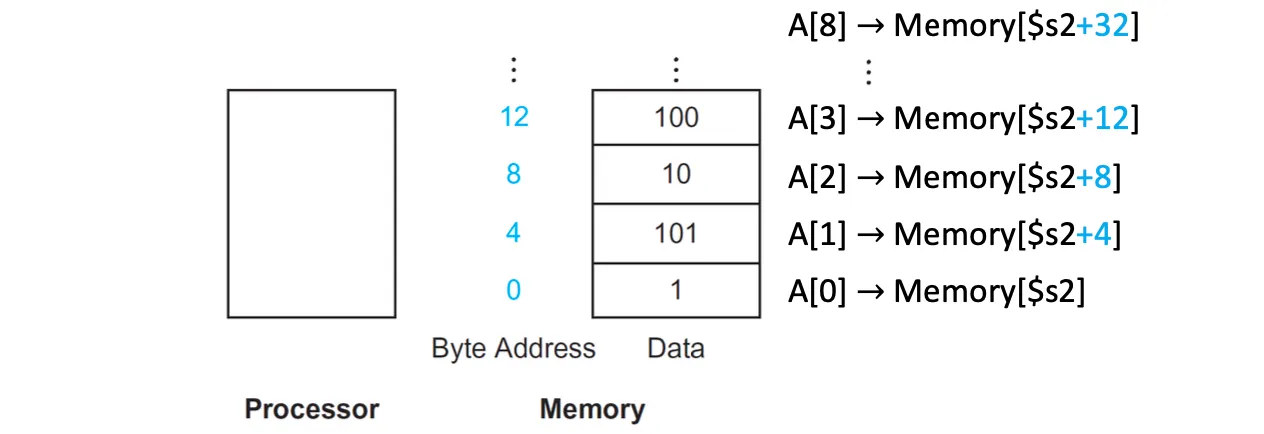
A[8]은 4바이트 단위로 8칸 다음의 데이터를 가져오라는 뜻이므로 base address인 $s3로부터 32바이트 떨어져 있다. word address를 byte address로 변환할 때 4를 곱하는것을 Alignment Restriction이라고 한다.
Constants or Immediate Operands
프로그램에서 상수를 사용할 때마다 lw명령을 통해서 해당하는 상수의 주소에서 값을 가져와서 레지스터에 넣어서 사용하는것은 비효율적이다.모든 계산은 프로세서 안에서 이루어지는데 프로세서 외부로 나가는 순간 딜레이가 발생한다. 따라서 메모리 접근을 가급적으로 피해야한다. 상수는 메모리 엑세스가 빈번히 일어나게 한다.
그걸 막기 위해서 만든 상수를 다룰수있는 명령어가 addi = add immediate
메모리에 접근하지 않아서 외부로 가지않아도 되어서 빠르다.
-1을 더하면 빼는거랑 동일하기 때문에 subtract immediate은 없다.
MIPS에는 접미사로 쓰이는 것이 2개가 있다. -i = immediate, -u = unsigned
addi $s3, $s3, 4 # s3 = s3 + 4
YAML
복사
$zero = 32비트가 전부 0인 레지스터이며 값을 바꿀 수 없다.
PseudoInstruction
pseudoinstruction은 사용자의 편의를 위해서 구현된 instruction으로 실제로 존재하는 instruction은 아니지만 어셈블러가 바이너리로 변환하는 과정에서 실제 instruction으로 전환한다. move operation등이 있다.
move operation은 하나의 operand가 0이어야 하기 때문에 $zero를 사용한다.
add $s1 $s2 $zero
move $s1 $s2 # 둘은 똑같은 명령어
YAML
복사
Instruction은 항상 operand가 3개인데 move는 2개이므로 pseudoinstruction이다
Signed and Unsigned Numbers
MSB = Most significant bit 32비트 기준 31번
LSB = Least Significant bit 0번 비트
MBS가 Sign bit로 사용됨. 0이면 양수이고 1이면 음수이다.

모든 비트를 반전하고 1을 더하면 해당하는 숫자의 음수를 취한 것과 같다.
singed extension은 늘어난 비트를 1로 채우고 unsigned extension은 늘어난 비트를 0으로 채운다.
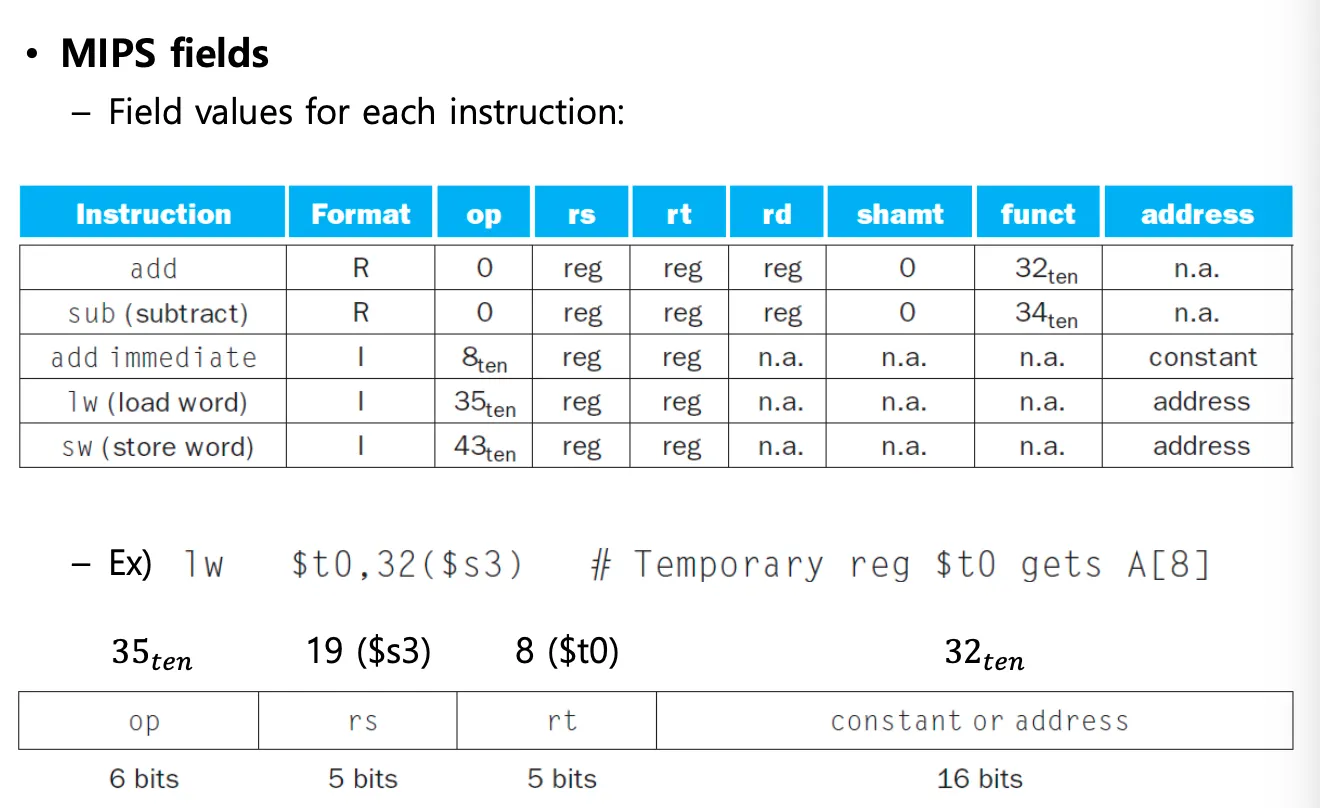
Representing Instructions
어셈블러가 머신코드를 바이너리로 변환하면 하드웨어가 이해할 수 있다.
어셈블리를 머신코드로 번역하는 포맷은 3가지가 있다: R, I, J- format
R-format

ex) add a, b, c instruction에서 a는 dest니까 rd에 들어가고 b는 rs로 c는 rt에 들어간다.
op는 operation code로 명령어가 어떤 역할을 해야하는지 알려주는 필드이다.
add를 표현하는 opcode가 정해져있고 그 코드가 op 필드에 들어간다
6개의 비트로 op를 표현하는데 모든 명령어를 구분하기에는 적기 때문에 funct를 사용한다.
op와 funct를 함께 봐야 어떤 operation인지 알 수 있다.
register의 번호도 지정되어있는데, $t0~$t7은 8~15번, $s0~$s7은 16~23번,$t8~$t9는 24,25번이다.
shamt는 add에서는 쓰이지 않는다. unused field는 0으로 초기화.

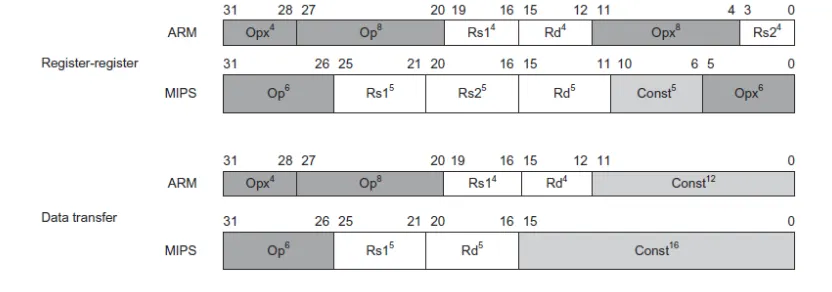
I-Format

i format 4개의 필드가 있고 총 32비트인건 똑같다.
Arithmetic operation에는 R-Format을 사용하고 data transfer operation에는 I-Format을 사용한다.
immediate가 붙는 instruction도 I-Format을 사용한다.
ex) lw, sw operation, addi instruction 등.
rs, rt등의 필드의 비트수가 5인 이유는 레지스터의 개수가 32개이기 때문이다 32개를 구분하기 위해서는 5비트면 충분하다.
t0에서 t7까지 8개가 자주쓰이고 나머지 2개는 잘 안쓰이기 때문에 t8, t9는 뒤에 매핑해놓은 것이다.
상수나 주소를 constants or address 필드에 저장한다.
I-Format은 funct가 없어서 op만 보고 어떤 명령어인지 알 수 있다.
Logical Operations
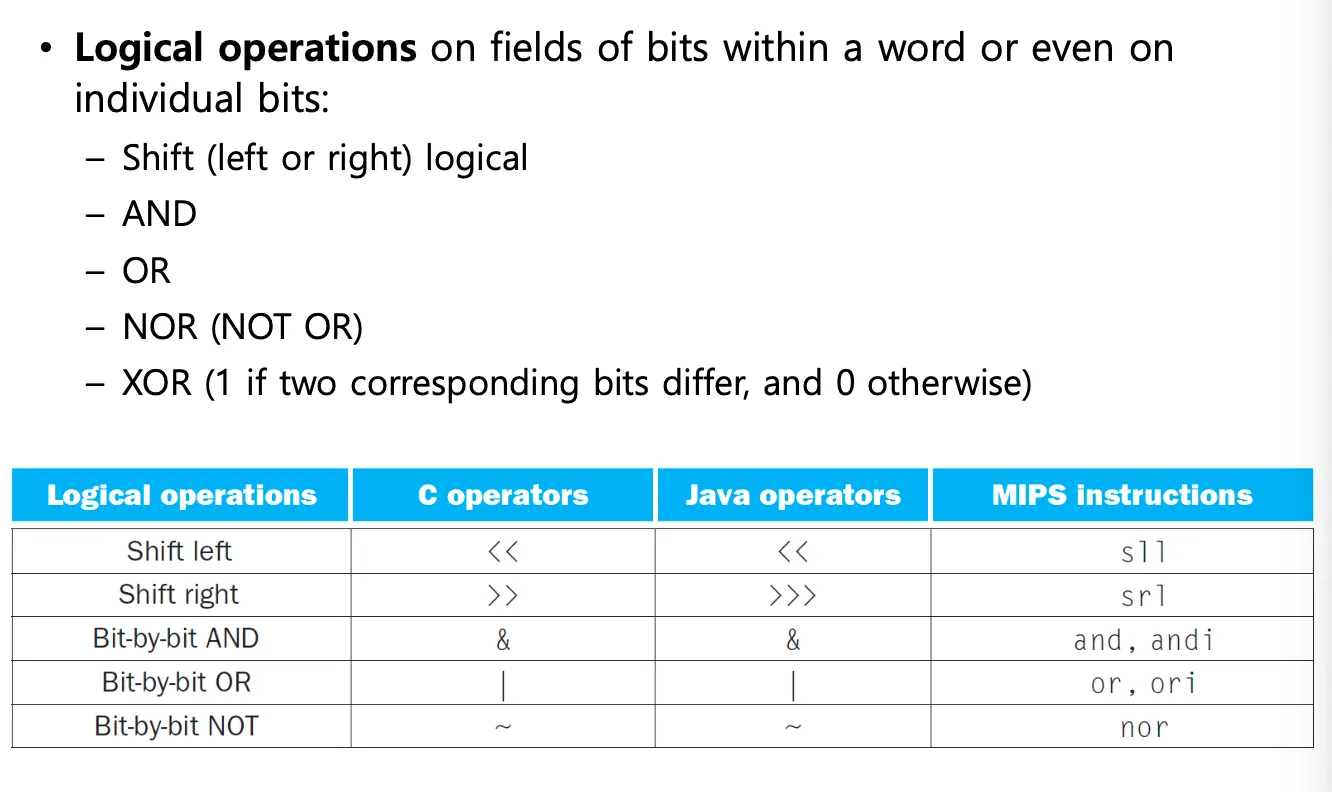

sll operation은 2의 배수를 곱하는 연산과 같다.
sll $t2, $s0, 4는 $s0에 2의 4승 = 16을 곱한것과 같다.

srl은 항상 2로 나누는것과 같을까? unsigned인 경우 2로 나누는것과 같지만 signed라면 true가 아닐 수 있다. sll은 부호와 상관없이 항상 2의i승을 곱한것과 똑같다.
AND, OR, NOR연산



nor은 or연산을 수행한 다음 not으로 반전해준 것이다. 다르면 1을 반환한다.
Decision Making Insturctions
if와 go-to가 있다.
conditional branch명령에는 같으면 label로 지정된 곳으로 점프하는 연산인 branch if equal = beq
다르면 label로 지정된 곳으로 점프하는 branch if not equal = bne가 있다.
beq register1, register2, L1 # 같으면 L1으로 점프
bne register1, register2, L1 # 다르면 L1으로 점프
YAML
복사

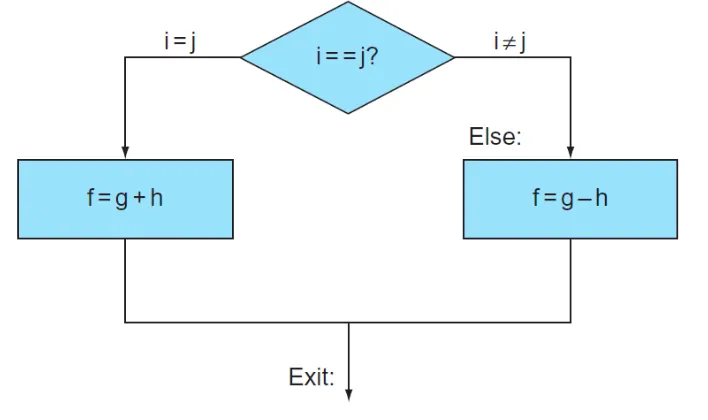
bne s3, s4, Else # s3 s4다르면 else로 가라
add s0 s1 s2 #i j 다르면 skip
j exit # exit으로 점프 (같아서 실행되고 exit으로 가는것)
Else: sub s0 s1 s2 # i j 같으면 skip
Exit:
Assembly
복사
jump명령은 j-format이다.
branch명령을 통해서 if문을 구현할 수 있다.

0($t1)인 이유는 이미 offset까지 고려해서 base address를 계산해놨기 때문이다
array에서 값을 로드하는 instruction은 항상 3가지로 정해져있다.
sll로 4를 곱해서 Alignment Resriction을 맞추고, add로 array의 주소를 계산하고 lw로 해당하는 주소의 데이터를 가져와서 레지스터에 저장한다.
slt
slt = set on less than set은 항상 1을 의미함
slt $t0, $s3, $s4 # s3가 작으면 t0를 1로 세팅해라
slti $t0, $s2, 10 #상수를 사용
Assembly
복사

slt명령은 branch명령과 함께 많이 쓰인다. $t0이 0이 아니면 L로 점프하라.
Procedures in MIPS
프로시저 = function
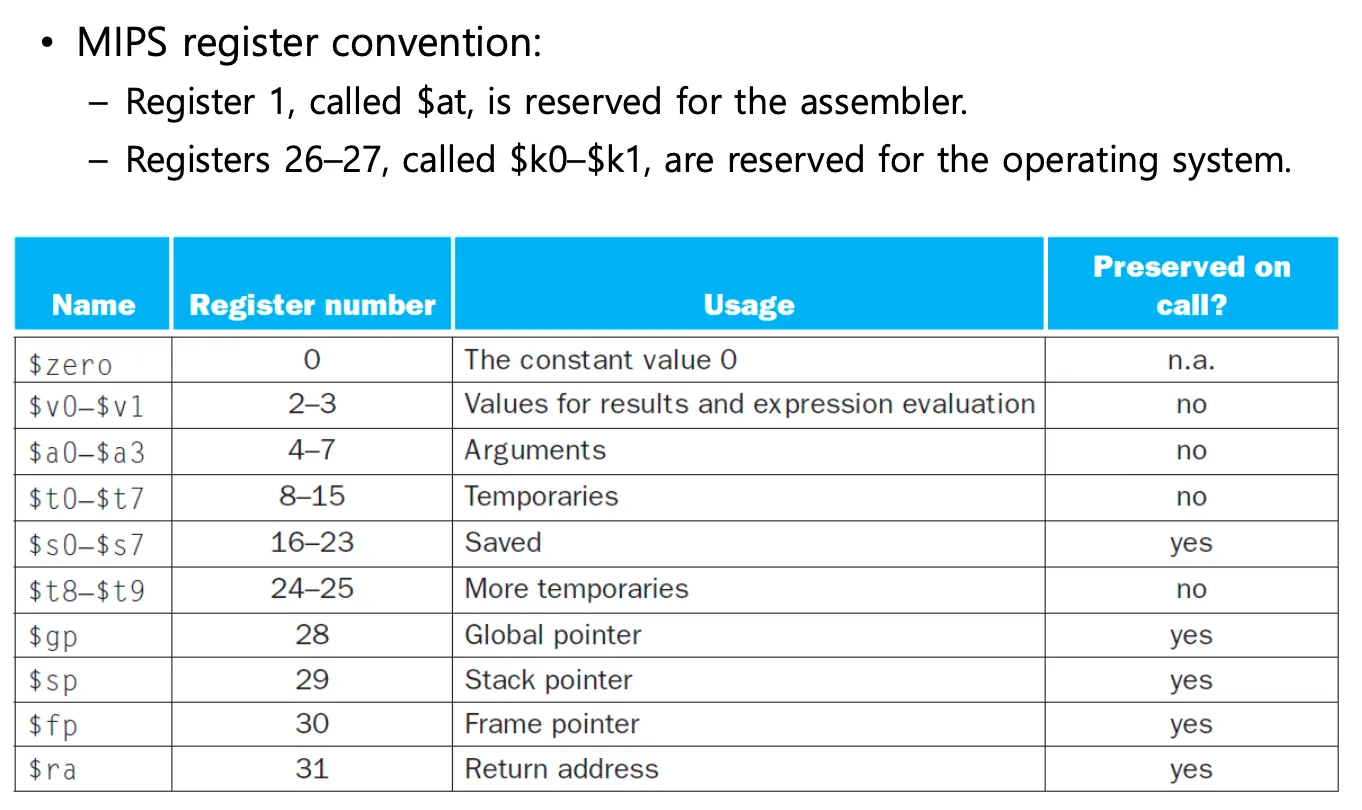
프로시저에서 중요한 레지스터는 3가지이다: $a,$v,$ra
$a = argument(함수의 input)
$v = value(함수의 output)
$ra = return address(돌아올 주소값)
함수가 실행되면 그 함수가 있는 위치로 뛰고 실행을 마치면 return address로 돌아온다.
jal = jump and link instruction ⇒ 함수를 호출하는 명령어로 함수가 정의되어있는 위치로 점프한다.
즉, 함수를 호출한다. link는 점프를 해서 실행한 이후 원래 위치로 돌아오는것을 말한다.
돌아올 위치는 $ra에 저장되어있다.
jal명령을 수행하면 함수를 호출함과 동시에 return address를 $ra에 save한다.
jr = jump register instruction 함수 실행을 마치고 리턴하는 명령어이다.
jr $ra return address 주소로 점프하기.
Using More Registers
$a0 ~ $a3까지 argument 레지스터는 4개가 있다. argument가 더 많을 경우 $t나 $s를 임시로 쓴다.
$v는 2개가 있음
$t는 값이 프로시저 전후로 preserve되는것을 보장하지 않는다.
$s는 프로시저 실행 전후로 반드시 값을 유지해줘야한다.
Stack
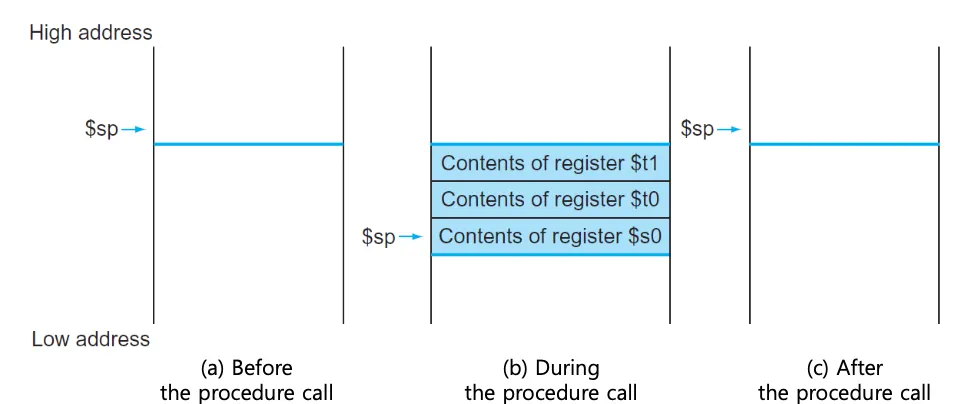
레지스터의 값을 preserve하려면 메모리의 stack영역에 저장한다.
메인 메모리에 값을 저장하면 높은 주소값에서 낮은 주소값으로 진행하며 저장된다.
$sp = 스택포인터 레지스터는 가장 최근에 allocate된 주소를 가리킨다.
Procedure Example
MIPS 프로시저는 leaf procedure, nested procedure의 두가지 종류가 있다.
프로시저 안에 프로시저가 있는 것이 nested procedure이고 leaf는 끝단이라는 뜻으로 단일 프로시저다.


스택 포인터는 아래로 성장하기 때문에 마이너스를 붙여준다.
stack pointer의 값을 내린다음 그 위치에 저장한다.
$s는 보존되어야 하기 때문에 stack에 미리 저장을 해둔다.
프로시저에서 복귀할때는 $s값을 원래대로 돌려놓고 가야한다.
lw로 $s0에 다시 값을 복구하고 addi로 $sp에 4를 더해준다.
Nested Procedures

$a는 프로시저 호출할때 공유되어 사용한다. F1호출에도 $a를 쓰고 F2호출에도 a를 쓴다.
F2를 호출할 때 F1의 argument값이 사라지는것을 막기 위해서 메모리에 저장하고 함수가 끝날 때 다시 복구한다
F1에서 jr $ra할때 return address가 덮어씌워지면 main함수로 돌아가는게 아니라 F2로 돌아가버린다. 따라서 $ra도 sw명령을 통해 미리 저장해놔야한다.
Frame Pointer
Stack공간에서 사용하는 포인터는 $sp와 $fp가 있다
fp = frame pointer로 stack의 base주소를 가지고 있다.
$sp는 스택이 커지면 값이 계속 감소하고 $fp는 시작주소를 그대로 가지고 있다.
$fp는 함수의 시작점을 가르쳐주는 용도로 사용하며 스택을 위에서부터 엑세스할 수 있도록 해준다.
Memory Layout
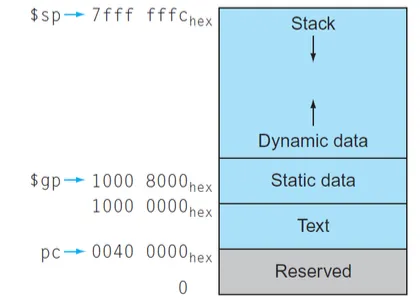
0부터 일정 공간은 운영체제에 의해 예약된 공간이고
text필드에서는 소스코드가 컴파일된 머신코드가 저장되어있다.
static data는 상수나 static변수 등 바뀌지 않는 값을 저장하고 $gp가 static공간을 가리킨다.
pc = program counter 현재 수행하고 있는 명령어를 가리키고 있는 포인터이다.
실행하고 다음으로 내려가면 pc의 값도 +된다.
heap공간은 dynamic data를 관리하며 낮은주소에서 높은주소로 자란다. dynamic 데이터는 해제해주지 않으면 heap에 계속 저장되어있어서 Stack영역을 침범해서 에러를 발생시킬 수 있다.
Character Data


16개 채우고 나머지 16비트는 0또는 1로 sign extention해서 채운다.
32-Bit immediate Operands
큰 상수를 다루기 위해서는 나눈 다음 다시 조립해야 한다.
lui = instruction load upper immediate 명령어는 큰 수를 만들때 쓴다. 레지스터의 upper 16비트의 상수를 세팅해준다.

$t0의 위쪽 비트 16개를 상수 255로 대체한다. 뒤쪽 16비트는 0으로 채운다.
상수 2304와 OR연산해서 뒤쪽 16비트를 원하는 숫자로 만든다.
이런 과정으로 32비트 사이즈의 큰 상수를 만든다.
MIPS Addressing

J-format 점프 명령에 사용함
byte address가 아니라 word address쓰는 이유는 더 많은 영역을 작은수로 커버할 수 있기 때문이다.
branch명령어 뒤에있는 16개 자리가 address이고 이것또한 word address기준이라서 4를 곱해야 한다.
대부분은 브랜치 명령어로 커버가 되는데 점프가 필요한 이유는 이동하고싶은 위치가 16비트 내로 들어오면 브랜치를 쓸 수 있지만 더 먼 위치를 한번에 가고싶으면 jump가 필요하다
PC-relative Addressing
pc = program counter 현재 프로그램에서 실행중인 해당 instruction가리키고 있는 포인터
pc도 레지스터인데 32개의 General Purpose Register에 포함되지 않는다. pc가 유저에 의해 컨트롤 될 수 있었을때 에러 발생의 원인이 되었기 때문에 유저가 못건드리게 세팅되어있다.
jr 명령으로 돌아가는 위치는 jal instruction의 위치로 돌아가는게 아니라 다음명령으로 돌아가도록 세팅되어있다. 따라서 $ra에는 pc가 아니라 pc+4가 저장된다. 이것을 pc-relative addressing이라고 한다.
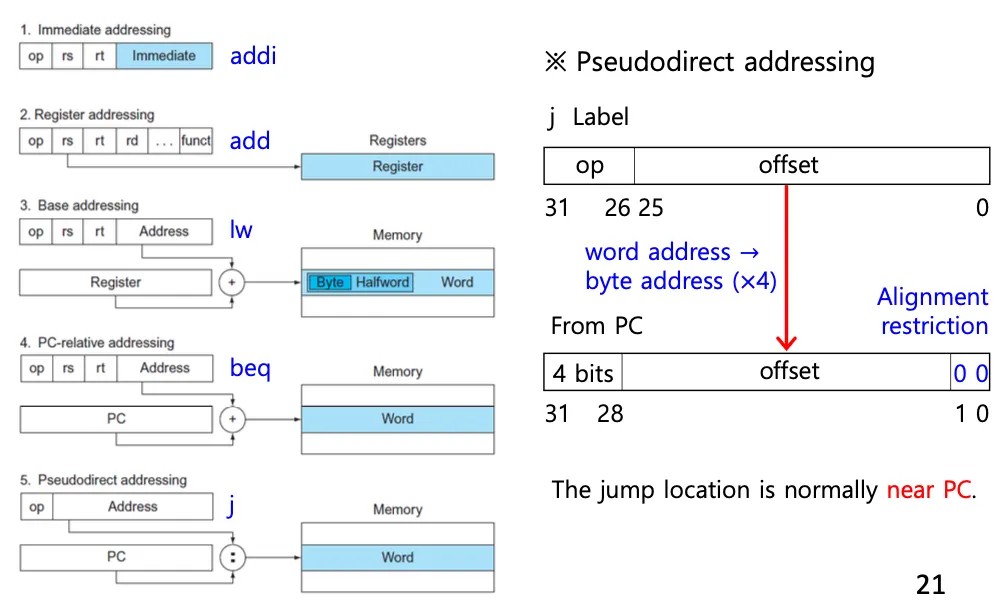
MIPS Addressing Mode summary
MIPS 어셈블리 언어에서 "주소 지정 모드"는 메모리에서 데이터를 접근하는 방법을 정의합니다.
•
즉시 주소 지정 (Immediate Addressing): 명령어 자체에 데이터 값이 포함되어 있습니다. 예를 들어, addi $t0, $t1, 5는 $t1에 5를 더한 값을 $t0에 저장합니다.
•
레지스터 주소 지정 (Register Addressing): 사용되는 데이터가 레지스터에 저장되어 있습니다. 예를 들어, add $t0, $t1, $t2는 $t1과 $t2의 값을 더해 $t0에 저장합니다.
•
기본 주소 지정 (Base Addressing): 레지스터의 값을 기본 주소로 사용하여 메모리에서 데이터를 읽거나 씁니다. 예를 들어, lw $t0, 4($t1)는 $t1의 값에 4를 더한 주소에서 데이터를 로드합니다.
•
PC-relative addressing은 beq명령이 해당함.
•
Pseudodirect addressing은 j명령이 해당함. sll을 통해서 4를 곱하고 프로그램 카운터에서 4개의 비트를 가져온다. 그 이유는 jump location이 보통 PC의 주변에 있기 때문이다. 0으로 채우는 경우 뒷자리가 커져도 PC와 가까운 곳으로 이동할 수 없다
Instruction Format Summary

Parallelism and Synchronization
프로세서1이 값을 쓰고 있고 프로세서2가 거기에서 값을 읽고 있으면 어떤 결과가 나올지 예측할 수 없다.
두개 이상의 프로세서가 같은 자원을 접근하는 상황을 Data race라고 한다.
이를 해결하기 위해서는 한 프로세서가 read,write하는 동안에는 다른 프로세서가 엑세스 할 수 없도록 막아서 atomic read/write를 구현해야한다.

sc가 1을 리턴하면 다른 cpu가 엑세스하지 않았다는 뜻이므로 성공이다.
0을 리턴하면 엑세스되어 바뀌었다는 뜻이다. 0인 경우 store에 실패하고 again으로 점프해서 성공할 때까지 계속 retry한다.
Translating and Starting a Program
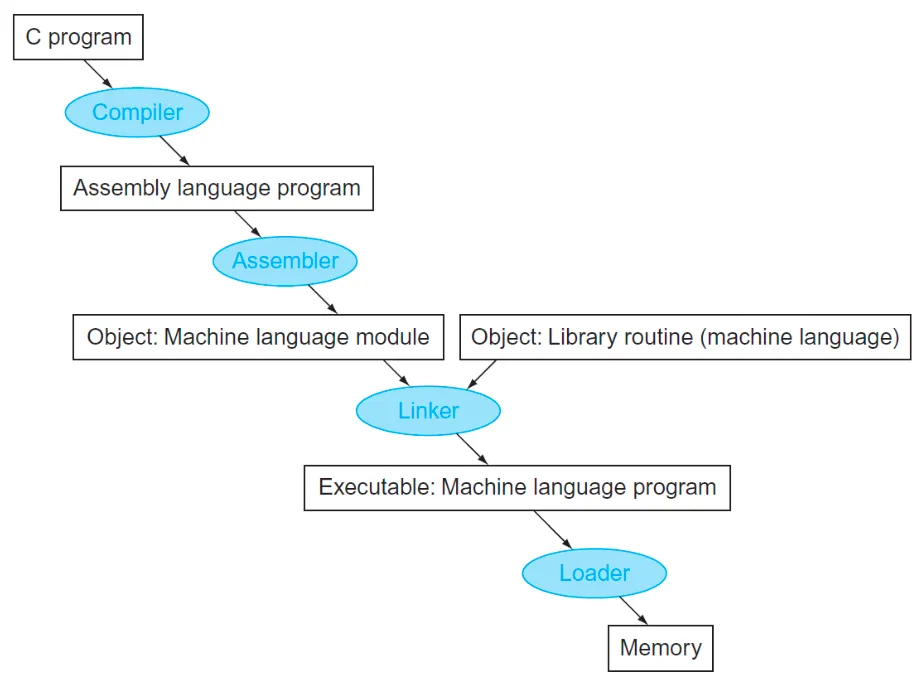
컴파일러는 c프로그램을 어셈블리 언어로 바꾸며 optimization을 수행해준다.
어셈블러는 pseudoinstruction을 이해하고 어셈블리 언어를 machine code로 변환해서 object file로 저장함.
pseudoinstruction을 사용하기 위한 비용은 $at레지스터를 어셈블러가 예약하는 것 뿐이다.

Object file: a combination of machine language instructions, data, and information needed to place instructions properly in memory.
text segment에는 c로 짠 코드가 머신코드로 저장되고 data segment에 상수 등이 저장되고 relocation information은 메모리에 올라갈 때의 위치정보를 저장하고, symbol table은 label, 변수 등을 저장한다.

Linker (Link Editor)
단 하나만 변경되었는데 프로그램 전체를 다시 컴파일하는것은 비효율적이다.
변경된 영역 object file만 다시 컴파일하고 assemble해서 쓰는게 좋기 때문에 linker를 사용한다.
링커의 동작 3단계
1.
Place code and data modules symbolically in memory.
2.
Determine the addresses of data and instruction labels.
3.
Patch both the internal and external references.
링커는 object file들을 연결해서 executable 파일을 반환한다
standar library등의 라이브러리의 object file도 연결해주는 역할을 한다.
Loader
프로그램을 실행하는 순간 exe파일이 로더에 의해서 HDD에서 메모리로 올라온다.
파일의 헤더를 통해서 정보를 파악해서 address space를 만들고 instruction과 데이터들을 메모리로 copy하고
register initialize해주고 startup routine으로 점프한다 = main함수 위치로 점프하고 argument들도 copy.
DLL = Dynamically linked library
Static linking library는 executable file에 포함되어 링킹되는것이고 dynamic linking은 프로그램 실행 후 런타임에 라이브러리를 링킹하는 것이다.
stdlib같은 큰 라이브러리를 static linking해놓으면 exe파일이 엄청 커질 수 있다. 그래서 필요한것만 갖다 쓸 수 있도록 dynamic linking한다. 라이브러리가 업데이트 됐다면 자동으로 업데이트된 버전이 사용된다.
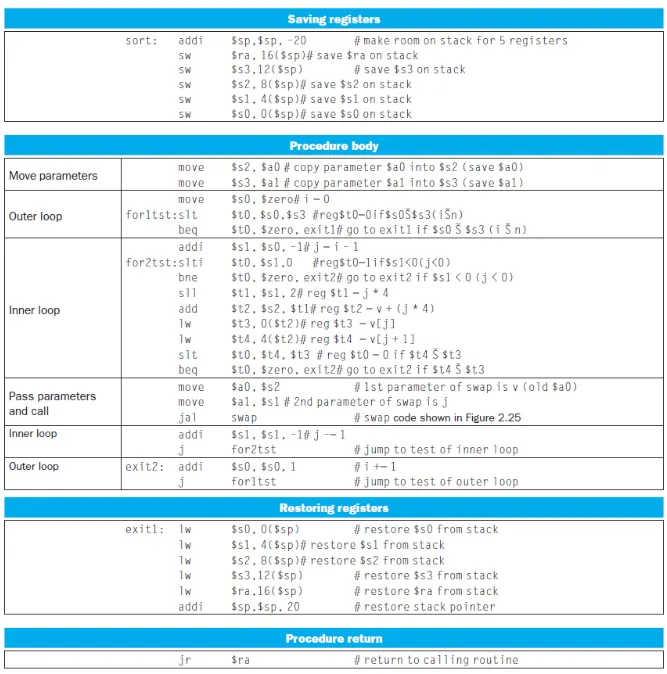
Procedure Swap

C를 assembly로 변환하기 위한 3단계
1.
Allocate registers to program variables.
2.
Produce code for the body of the procedure
3.
Preserve registers across the procedure invocation.
input parameter 2개는 $a0과 $a1에 들어간다.
variable temp는 $t0을 사용한다고 가정. swap은 leaf 프로시저이기 때문에 $t에 보관해도 괜찮음.

lw를 통해서 array의 값을 가져오려면 주소를 알아야하는데, 주소를 알아오려면 index값인 k에 alignment restriction으로 인해서 sll로 4를 곱하고 그 값을 v[]의 베이스 주소값인 $a0에 더해서 lw를 수행할 주소를 계산
k와 k+1을 둘다 가져오고 sw로 저장한 이후에 jr로 return address로 복귀
Procedure Sort

procedure sort는 nested procedure이고 i,j, $ra값은 swap프로시저 실행전후로 preserve해야한다.
v와 n은 argument이므로 $a에 할당하고 i와j는 $s0, $s1에 할당한다.

slt = set on less than ⇒ 처음에 i를 0으로 초기화하고 slt로 i값과 n값을 비교한다음 같으면 exit1으로 점프하고 다르면 swap을 수행한 이후 i값을 1늘리고 루프를 돈다.

slti를 이용해서 0보다 작으면 $t0에 1을 저장하고 bne를 통해 $t0의 값이 0이 아닌 경우 exit2로 점프
0인경우 j에 4를 곱하고 v[]의 주소값에 더해서 그 주소값으로 v[j], v[j+1]을 lw로 가져온 다음
slt와 beq를 이용해서 v[j+1] > v[j]인지 비교하고 맞으면 exit2로 점프하고 아니면 swap을 수행한 다음
addi로 j값을 1 감소시키고 다시 루프를 돈다.
swap을 수행할때는 $s2와 $s1을 argument register인 $a0과 $a1에 move한 이후 jal로 swap프로시저를 호출함.
내부에서 프로시저를 한번 더 호출하기 위해서는 preserve과정이 필요하다
$s0~$s3까지와 $ra를 저장해야하므로 stack에 -20을 더해서 5칸을 만들어주고 sw를 수행한다.
swap프로시저가 끝난 이후에는 lw를 통해서 다시 가져고 jr $ra를 통해 main함수로 복귀한다.
Array vs Pointers

clear1의 input parameter인 array[]와 size는 $a0, $a1에 할당하고
temporal variable인 i는 $t0에 할당한다.
leaf procedure이기 때문에 preserve과정은 필요없다

포인터를 사용하는 clear2도 크게 다르지 않은데 sll명령과 add명령이 루프 바깥에 존재한다. array는 계속해서 주소값을 계산하고 sw를 수행하는데 포인터는 addi로 4씩 주소값에 더하면서 다음 주소를 접근한다.
for문에 들어가는 명령이 적으면 수행횟수가 줄어들기 때문에 포인터를 썼을 때 성능이 더 좋다.

ARM v7
MIPS와 같은 해에 나온 임베디드에 들어가는 ISA.
MIPS와 다른 기능은 opx 필드: 해당 명령어를 수행할지 말지를 결정하는 conditional execution 필드. 버전 올라가면서 없어졌으며 점점 MIPS와 기능이 비슷해졌다. ARM v8는 64비트 주소체계를 사용함.
Fallacies and Pitfalls
1.
강력한 한줄의 코드로 작성하는것이 여러줄을 사용하는것보다 효과적이다.
⇒ False. 간단하고 반복적인 여러줄의 코드가 성능이 훨씬 좋을 수 있다
2.
어셈블리로 코드를 짜면 높은 성능을 낼 수 있다.
⇒ False. 어셈블리로 짜는것보다 컴파일러가 최적화를 더 잘하고 다른 언어로의 포팅도 쉽다.
3.
Instruction set은 변하지 않는다
⇒ False. 현재도 instruction개수는 계속 증가하고 있따.
sequential word는 sequential address가 아니다. alignment restriction때문에 4씩 증가하기 때문.
