
Processor
cpu time으로 cpu의 performance를 측정한다.
cpu time = instruction count * cpi * clock cycle time

Instruction Execution
모든 instruction에 대해서 두가지 step은 항상 동일하다.
1.
코드를 포함하는 program counter를 메모리로 보내고 instruction을 메모리에서 가져온다.
pc의 주소값에 있는 코드를 읽어서 수행한다는 뜻
2.
instruction을 읽으면 세 개의 operand들이 있는데, 그 값을 읽어서 레지스터를 세팅한다.
Instruction class
ALU를 사용하는 경우는
1.
lw, sw명령으로 주소를 계산할때 사용
2.
branch명령으로 beq등을 수행할 때 크기를 비교하기 위해서 뺄셈에 사용
3.
pc가 target address로 가거나 pc+4를 위해서 사용
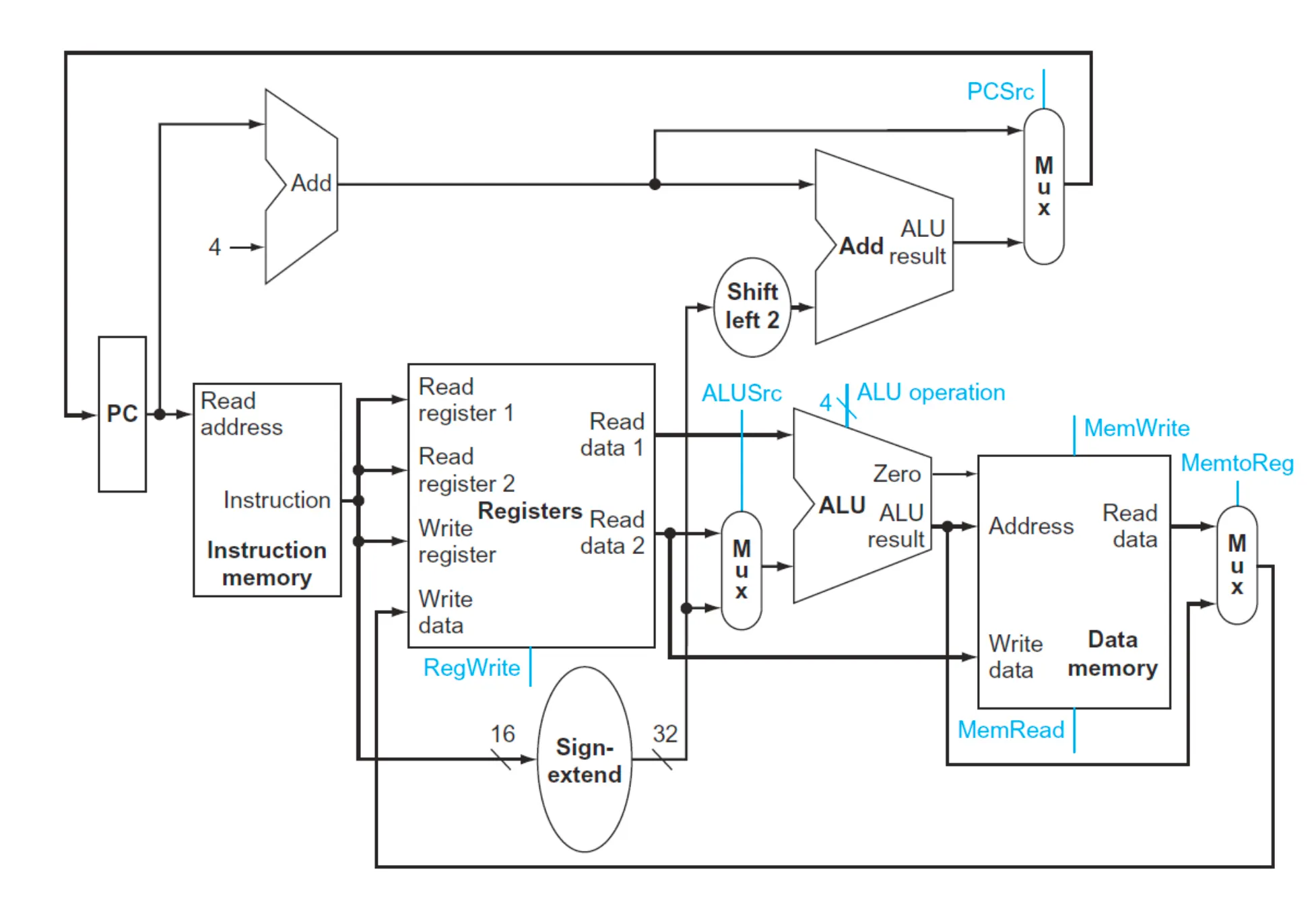
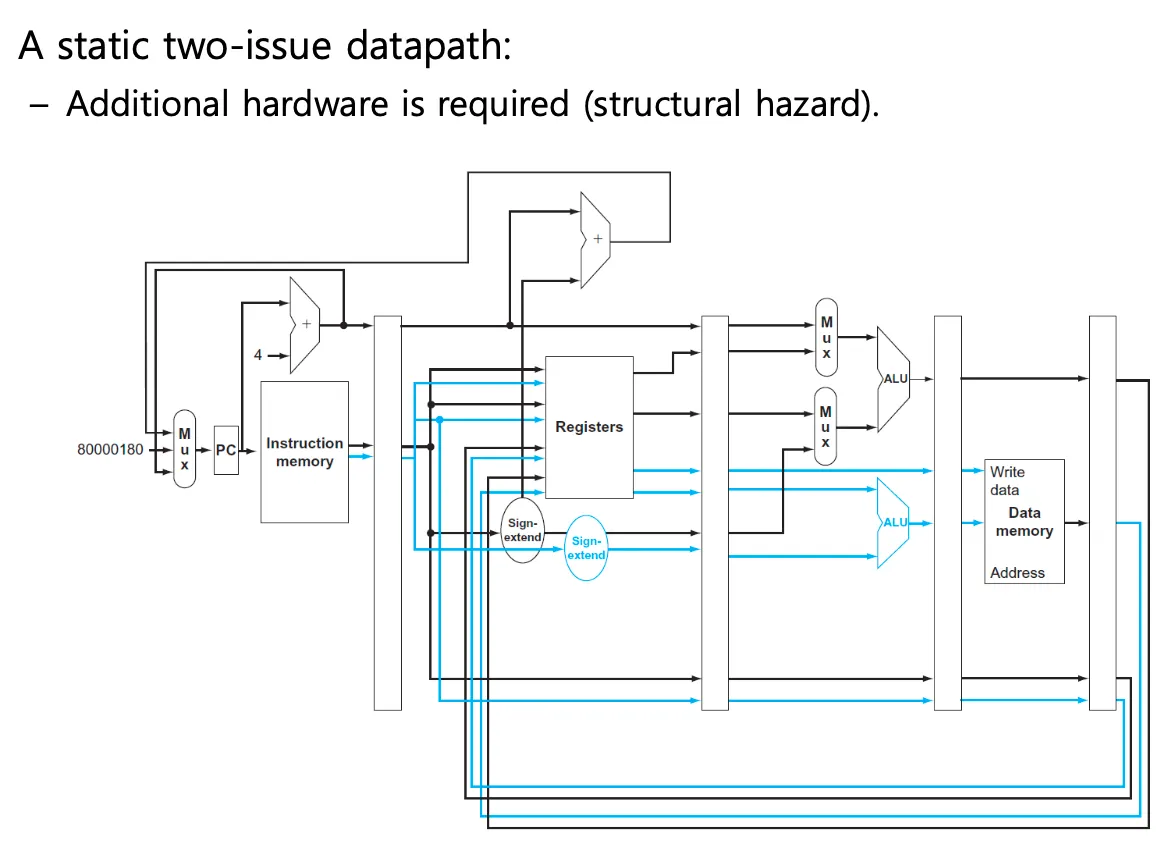
MIPS CPU Implementation
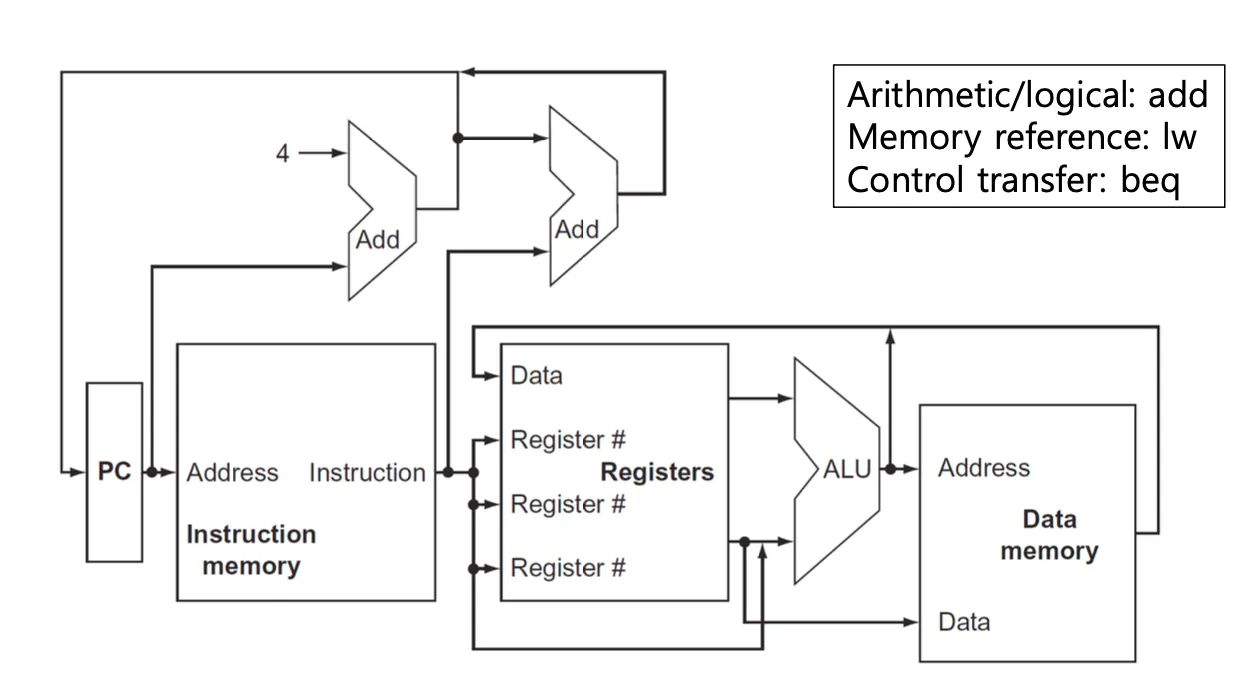
pc는 현재 실행해야하는 코드의 주소를 가리키고 있다. 그 주소를 instruction memory에 보내주면 주소에 해당하는 코드를 로드해서 Registers로 보낸다.
add를 예로 들면 rs와 rt를 ALU의 입력으로 넣어주고 ALU는 덧셈을 수행한 다음 메모리에 접근할 필요 없으므로 바로 Data에 저장된다. pc는 Adder에서 +4가 되어서 다음 코드의 위치를 가리키고 branch인 경우에는 Adder를 한 번 더거쳐서 pc+4 +8과 같은 연산을 한다. 그 과정에서 sll을 통해서 word address를 byte address로 바꾸는 과정도 포함된다.
R-Foramt 명령어는 연산 수행 결과를 rd레지스터에 저장한다.

라인이 겹치는 부분에 MUX(multiplexer)를 달아준다. 값에 따라서 방향을 결정해주는 스위치이다.
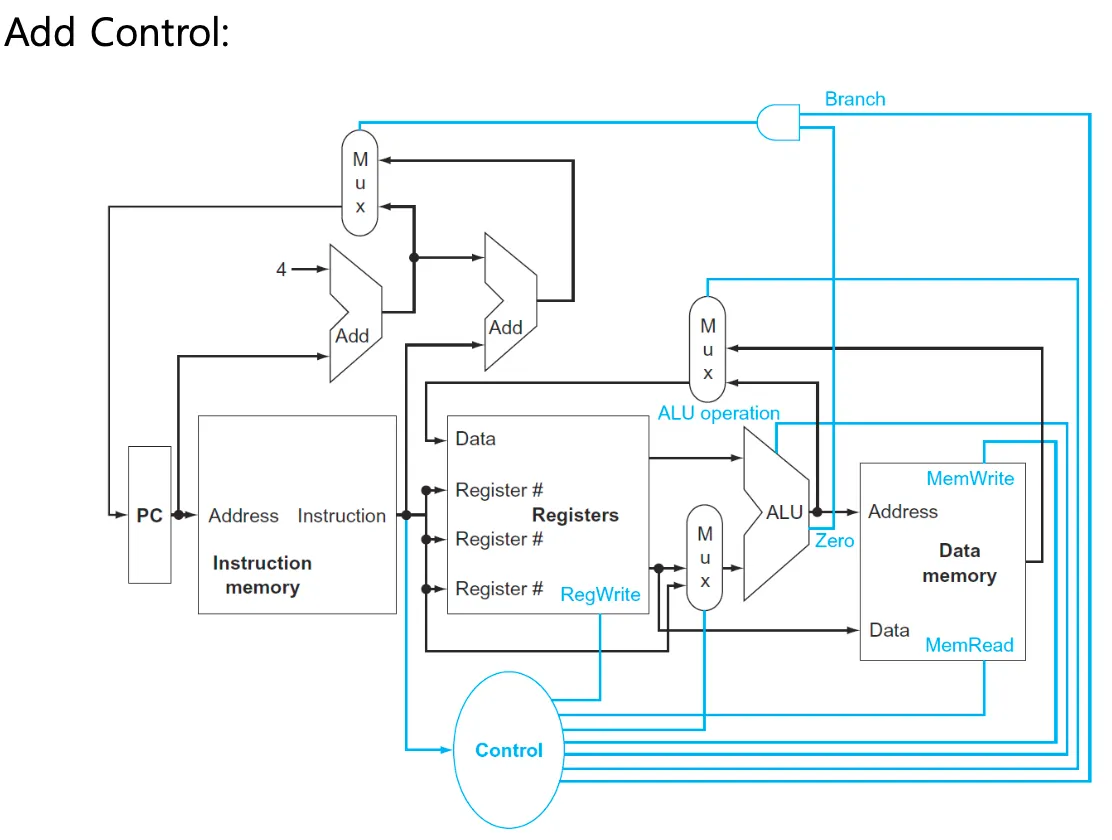
프로세서는 control + datapath이다. control을 추가하면 아래와 같다.
Logic Design
logic element에는 combinational과 state element가 있다.
현재 입력에만 의존해서 output이 결정되는 AND-gate, ALU 등이 combinational element이다.
state element는 memory element라고도 하며 output이 내부의 상태와 input에 따라서 달라질 수 있는 element로 레지스터, 메모리 등이 해당한다.
combinational logic은 한 clock cycle동안 데이터를 변경하고 반드시 그 안에 끝나야 한다.
rising edge부터 다음 rising edge까지가 한 사이클이며 state는 rising edge에서 변경된다.
combinational logic이 오래 걸리면 여러개의 사이클을 쓴다.
datapath element
계산을 수행하거나 데이터를 저장하기 위한 element로 메모리, register file, ALU, PC 등.
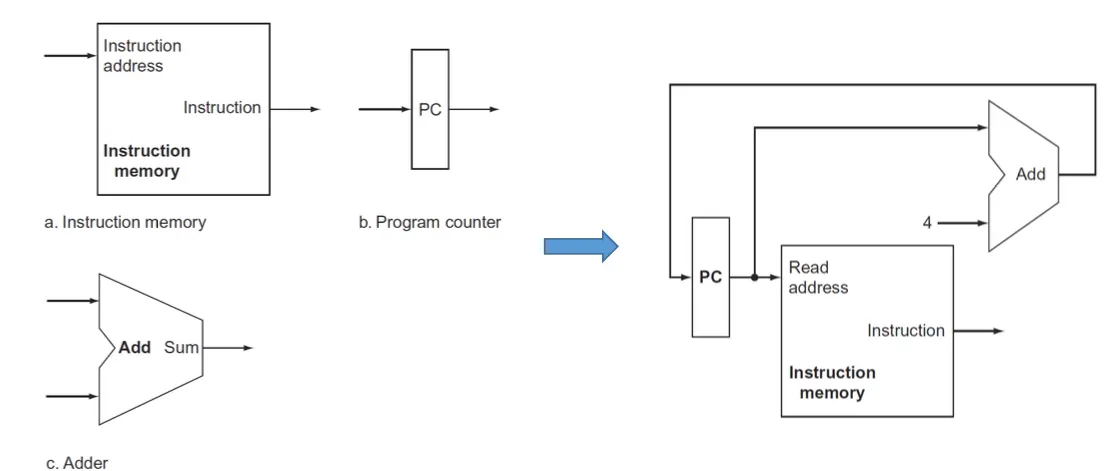
PC가 현재 instruction의 주소를 주면 주소를 읽어서 instruction을 출력으로 주고 PC는 adder에서 4가 더해져서 다음 코드를 가리킬 수 있도록 업데이트 된다.
arithmetic, logical instruction은 R-format이다. R-Format은 레지스터파일과 ALU에만 접근하고 메모리에는 접근하지 않는다.
레지스터 파일은 32개의 레지스터를 포함하고 있다.
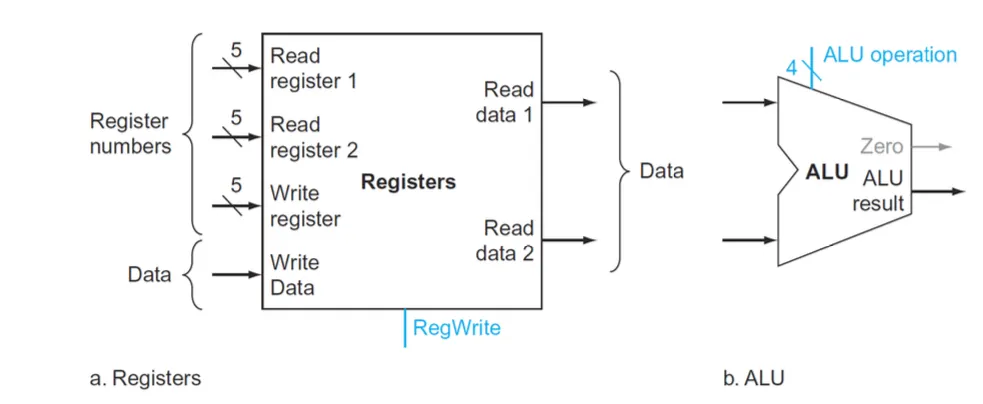
Registers에서 버스의 length가 5비트로 표시되어있다. 레지스터의 개수가 32개이므로 구분하기 위해서 5비트 이상이 필요없기 때문이고 버스에 별도의 표시가 없으면 32비트이다.
연산의 결과값은 Data에 들어가고 write data는 rd 레지스터에 저장하는것이다.
Registers에는 두 개의 read포트와 한개의 write포트가 있다. RegWrite은 Register Write으로 control이 1이면 rd에 데이터를 쓰고 0이면 쓰지 않는다.
read data1,2 포트의 출력은 32비트다. rs는 read data1으로 나가고 rt는 read data2로 나간다,
ALU도 32비트 입력 두개를 받아서 32비트 결과를 출력한다. 결과값은 Data에 들어가고 rd에 저장된다.
sub명령인 경우에도 ALU Operation의 control signal의 값에 따라서 더하거나 빼는것만 달라질 뿐 과정은 같다. ALU Operation은 4bit signal이다.
Zero는 branch를 위한 출력으로 beq $t0, $t1, Label 명령을 예로 들면 똑같을 경우 Label로 점프해야 하지만 똑같은지 다른지는 빼기 연산을 해야 알 수 있다. ALU가 뺄셈을 수행하고 0이 나오면 Zero의 출력은 1이 되고 0이 아니면 출력은 0이 된다.
PC가 가리키는 명령어가 beq $t0, $t1, Label이라면 beq명령의 주소값을 Instruction memory에 전달하고 주소값에 있는 명령을 읽어서 registers로 보내고, src가 없으니 두개의 register에만 값이 들어가고 Label의 주소는 Adder로 들어가기 전에 sll연산으로 4를 곱해서 word address를 byte address로 변환하는 과정을 거친다.
register 두 개의 값은 ALU에게 들어가서 뺄셈연산을 해서 값을 비교해서 값이 같으면 Zero는 1이 되고 다르면 0이 출력되고 Branch를 결정하는 AND-gate로 전달되어서 control에서 준 값과 비교한다. 둘 다 1이어야 AND-gate의 출력이 1이 되는데 Control에서 branch 명령인 경우 1을 전달한다.
AND-gate의 출력이 1이면 MUX가 1을 받는다. MUX는 2개의 Adder와 연결될 수 있는데 MUX가 0인 경우에는 pc+4와 연결되어서 다음 명령어를 가리키고 1이면 Label의 주소를 byte address로 변환했던 path와 연결되어서 점프를 수행하게 된다.
Memory Reference
lw, sw명령은 I-Format이다
Data memory에는 MemRead와 MemWrite control이 있고 MemRead의 control이 1인 경우에는 lw를 수행하고 MemWrite의 control이 1인 경우에는 sw를 수행한다.
lw t0, 4(s0) 명령일 경우 ALU가 4+ base address연산을 수행한다음 Data memory의 address로 전달하고 read data이므로 Write data포트는 사용되지 않음 sw일 경우에는 Write data로 레지스터의 값이 들어온다.
Sign Extension unit은 16비트 input을 받아서 extended된 32비트 result로 반환한다.
branch명령은 I-Format으로 주소값의 사이즈가 16비트인데 ALU는 입력과 출력이 모두 32비트이므로 Sign Extension Unit을 통해서 32비트로 연장해준다. Adder가 받는 인풋도 모두 32비트이다.
32비트로 extend한 주소값에 sll연산으로 곱하기 4를 해서 byte address로 변경해준다.
그다음 pc+4와 더해주면 점프할 위치 = Branch target이 결과로 나온다.
Datapath
lw t0, 4(s0)명령어를 예시로 들면, lw는 I-Format이고
PC가 실행할 명령어를 가리키고 있고 instruction memory로 주소를 보내주고
instruction memory가 Format을 보고 field size에 맞게 쪼개고 opcode를 보고 lw명령이라는것을 파악하고 각 field를 읽어서 레지스터 값을 Registers에 보내준다.
write register는 연산결과를 저장할 레지스터로 $t0은 write register로 들어가고 $s0은 read register로 들어가고, offset은 sign-extend에 들어간다.
read data1에는 $s0의 값이 들어가고 offset 16비트는 sign extend로 들어가서 32비트로 바뀐 다음 MUX에서 ALU로 연결되고 $s0과 offset을 더해서 그 결과가 Data Memory의 address로 들어가고 lw명령이므로 write data는 받지 않고 주소값에 있는 데이터를 읽어서 MUX로 보내고 MUX에서 Registers의 Write data로 들어가고 RegWrite가 데이터값을 $t0에 기록함.
ALU Result에서 MUX로 바로 가는 경우는 Data memory를 거치지 않는 add연산일 경우이다.
10/29
ALUOP
function filed 필드에서 6개의 비트. 다쓰진 않고 뒤의 4개만 쓴다
alu control signal은 aluop와 function filed가지고 정한다
aluop는 opcode보고 결정한다
data transfer, branch, r-type 정해져있다
00, 01, 10이다 opcode가
branch의 alu action은 subtract을 해야한다 크기를 비교해야하기 때문에
Lw SW는 add이다 주소계산을 위해서
lw t04(s0) 주소를 계산할때는 base address와 offset을 더해야한다
lw sw는 i format인데 function field없다 그래서 XXXXX = dont care
브랜치도 dont care
r-type만 function field가 의미가 있다
alu control input이 lw든 add든 똑같다
같은 역할을 하기 때문
00,01,10 외우기
X는 0이라고 생각하면 된다
브랜치면 subtract이니까 자동으로 결정된다
r-type의 function field보면 dont care인데 앞의 2개가
실제값은 10으로 되어있다 근데 다 똑같으니까 구분은 안된다
19페이지에 ALUControl ALUOp가 생겼는데
4개의 비트를 전달한다 ALU에 어떤 역할을 하는지 알려주는거다
그럼 ALU가 어떤 동작을 할지 결정한다.
rd는 저장되는 위치
lw sw는 rt에 저장한다 rd가 없어서
rs는 항상 읽기만 하고 rt는 load만 쓰고 보통 읽기
instruction의 32비트를 필드개수만큼쪼개주는데
rs는 read register들어가고
rt 는어떤때는 read 어떤때는 write load를 위해서
RegDst = reigster destination 어디로 붙을지 정해준다
1이면 rd가 wriet에 붙고 0이면 rt가 붙는다 write register에
branch명령의 주소는 sign extend로 간다
function code는 따로 빼서 alu control로 간다 그래서 aluop만듦
양수면 0으로 채우고 음수면 1로 채운다 sign extend
aluop는 11은 없다!
main control unit에서 9개의 signal을 만든다
7개의 시그널과 2개의 aluop
검은색은 datapath 파란색은 control이다
합치면 processor이다
컨트롤은 opcode를 받는다 instruction 31-26
r i j포맷 모두 opcode는 있다 컨트롤이 받는다
aluop만 선이 두껍다 aluop는 두개의 비트를 가져서 그렇다
regDst는 mux로 가는데 write register에 rt를 보내줄건지 rd를 보내줄건지 결정한다 1이면 rd 0이면 rt
브랜치는 and gate를 지난다 하나는 제로 시그널
and gate의 출력을 pcsrc라고 한다 pc source
컨트롤이 만드는게 아니다 and gate에 의해서 자동으로 결정되는 시그널
pc+4할거냐 브랜치할거냐를 결정하는거다
브랜치와 제로의 and게이트 결과이지 pcsrc는 컨트롤 시그널이 아님!!
memread는 memory read가 필요할때 lw명령어 등
memtoreg는 아래로 붙으면 alu결과를 바로 레지스터로 보냄
memwrite는 메모리에다 쓰는 명령어가 sw밖에 없으니 sw일때 1이고 나머지0
alusrc는 alu의 입력을 결정해준다
regwrite은 대표적으로 add lw명령어 등

r-format은 regdst1이고 aluop는 10
rtype은 브랜치 안쓰고 데이터 엑세스 안쓴다
회색부분은 안쓰는것!
6개 입력을 받아서 9개의 시그널을 생성한다
점프는 opcode를 컨트롤에게 주면 점프인걸 알고 jump를1로 만든다
나머지 전부 안쓴다 레지스터 관련 정보가 없기 때문에
pc의 윗주소 값이 중요한다 일단 무조건 4는 더하고
26개가 입력으로 들어간다 곱하기 4하면 28개의 비트가 나오고 4개의 부족한 비트는 pc에서 가져온다 pseudodirect에서 한것과 같다
거기에다 pc+4의 앞에 4개를 더해서 jump address 32개 비트 완성!
그럼 mux로 가서 pc로 들어간다.
pc가 아니라 pc+4에서 가져오는거다!
mips core에서는 shift amount를 사용하는것을 배우지 않을거다
jump는 메인 컨트롤 시그널이라고 하지 않음
Pipelining
여러개의 명령이 수행할때 겹칠수 있도록 하는 구현 기술이다 병렬연산
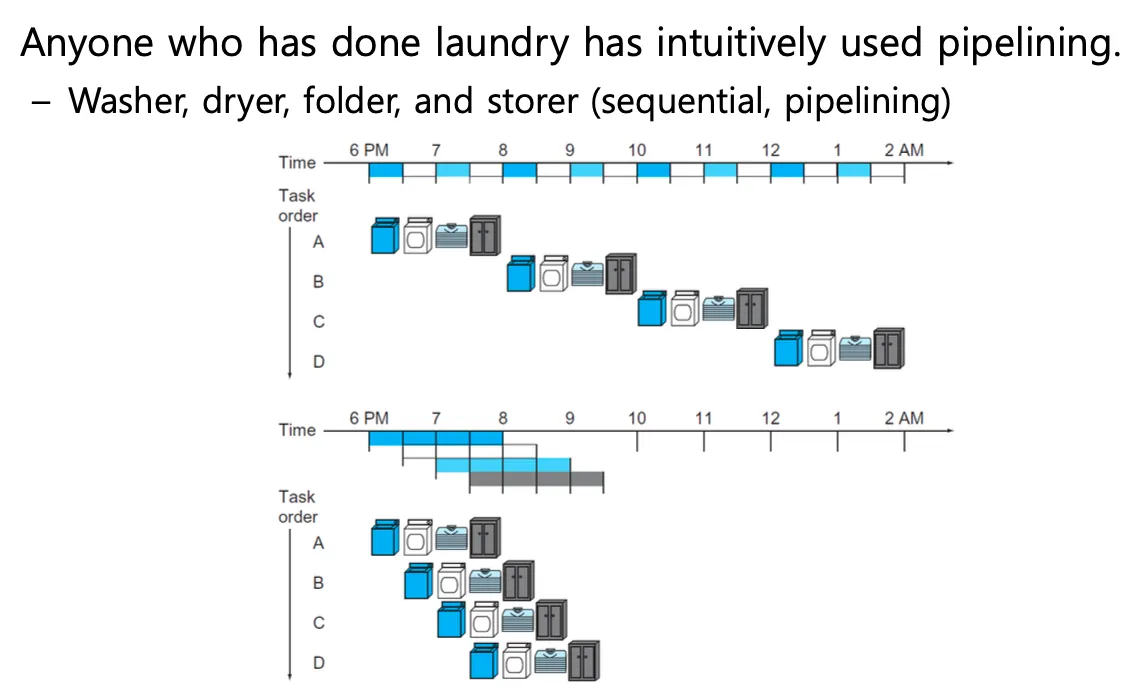
washer하는 동안은 다른건 wash못한다 dryer돌릴때는 세탁기 비어있으니 wash한다. 이런게 파이프라이닝
single stage는 빨래를 sequential하게 하는 경우이다
multi stage로 파이프처럼 쪼갠다
피이프들을 연결해서 이어붙인다 파이프를 stage라고도 한다
pipelining파이프들을 연결한다
넘어갈때 조금 오버헤드가 있긴 한데 무시하기로 하자 지금은
single stage와 성능이 같다고 고려
병렬로 여러개의 instruction을 수행할 수 있다
모든 스테이지가 같은 양의 시간을필요로하고 충분한 work가 있으면 속도는 stage수와 비례한다
병렬연산을 방해하는 요소
비는공간을 startup wind down이라고 한다
시작할때랑 끝날때만 영향을 주는거고 중간에는 계속 도는거니까 낭비가 크지 않다
스테이지가 4개면 4배만큼 빨라져야하는데 startup과 winddown때문에 4배가 안됨. task의 수가 충분하지 않으면 영향이 크다
single stage를 mips에서는 5개로 쪼갠다
IF instrution fetch
ID instruction decoding
EX execution
MEM 데이터메모리 엑세스
WB 레지스터에 쓴다 write back
파이프라인 싱글사이클 비교
lw는 5개 스테이지 다 필요해서 800
r-format은 600 데이터 엑세스 안해서
각각의 instruction마다 총 걸리는 시간이 다르다
싱글의 경우 rising edge부터 다음 rising edge까지 중에 반드시 모든 작업이 끝나야하는데 모든 명령어가.
lw가 들어왔으면 싱글 사이클 안에 끝나야한다. 그럼 최소 클록시간은 800이 되어야한다.
브랜치는 클록타임이 500밖에 안써도 어떤 명령어가 들어와도 실행해야해서 800을 다 쓴다. 300은 컴퓨터가 논다
가장 느린 instruction에 맞춘다! 시험문제 1300이고 1000일때 싱글사이클 타임 얼마인가?
파이프라인 케이스
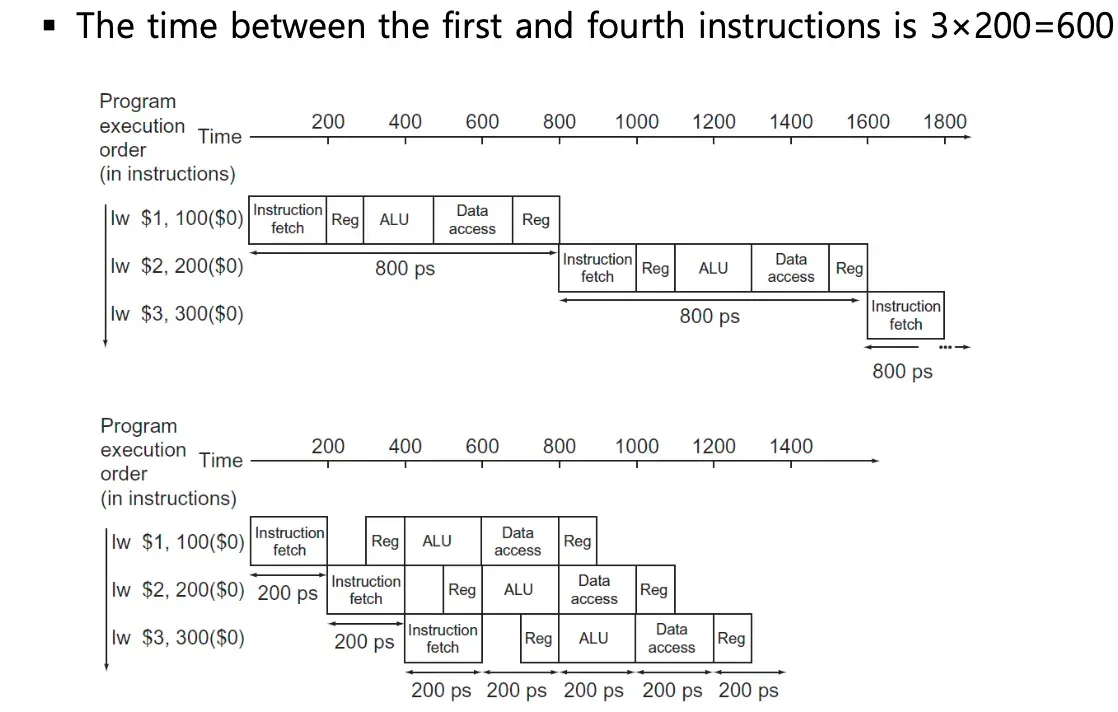
파이프라인에서는 하나의 클록 안에서 끝내야하는게 한 스테이지로 줄어든다
스테이지중에 가장 긴게 200이니까 클록 사이클을 200으로 맞추면 된다
5개의 스테이지로 나뉘고 register read regisetr write은 100만큼 손해를 보긴 한다
lw는 다섯개의 스테이지를 거치는데 200을 5개니까 1000
근데 위에는 800이다. 손해인데?
하나하나는 손해일 수 있는데 전체를 보면 무조건 빠르다
네번째 명령 실행하는데 걸리는 시간은 2400대 600이다.
만약 stage들의 걸리는 시간이 완전 똑같다면?
그럼 single을 파이프라인 수로 나눈것과 같다. 160이 된다
근데 실제로는 스테이지 간의 시간이 같지 않으므로 160은 아니다 일반적으로 다르다
2400은 3개 명령어 실행한거고
1400은 200*7이고
1.71배 빨라졌다. 4배 안빨라졌네 명령여가 적어서
그럼 100만개 더하는 경우?
4배로 수렴한다! 명령어가 많아지면 startup winddown의 영향이 거의 사라진다
5배 빨라지면 각각이 똑같이 160씩 걸린다면 그럴수 있다
그런데 긴거기준으로 맞추기 때문에 4배인것
파이프라인 구현
모든 instruction이 똑같은 길이를 갖는다 32비트
instruction을 fetch하고 디코드하기가 쉽다
instrution format의 3개밖에 없다
memory operand는 lw sw에서만 쓴다
주소 한군데에만 엑세스하기 때문에 메모리에서 align되어있다
두개의 데이터 메모리 엑세스를 요구하지 않는다
11/1
싱글태스크 과점에서는 수행시간이 변하지 않는다는것이 중요하다
전체적인 시간을 throughput이라고 하는데 throughput은 많이 줄어든다 1.7배
pipeline hazard 위험요소
다음 명령어가 바로 실행되지 못하도록 막히는 상황
총 3가지:
•
structurual hazard
•
data hazard
•
control hazard
strucutral 은 required resource가 하드웨어적으로 없다
하드웨어 이슈. 혹은 바빠서 실행할수없다거나 하드웨어관련 소프트웨어적으로 풀 수없다
해결하기위한 솔루션은 제공하지 않는다 책에서는 개념만 알고있기
data hazard는 이전 instruction이 끝내지기를 기다리는 상황
데이터가 아직 없어서 생기는 hazard
$s0가 명령어 사이에 겹친다. add가 끝나야 subtract할수있다
아직 결과가 나오지 않았는데 이전값으로 실행할 수없다. 데이터가 준비가 안되어서 실행할수없는상황
writeback 레지스터에 값을 저장하는 단계 5단계. 이게 끝날때까지 기다려야한다 subtract은
그럼 그 사이에 노는 idle타임이 발생한다. 세칸을 낭비하고 실행한다
이런 hazard를 제거하기 위해 컴파일러에 의존한다 hazard만들어지는것을 컴파일러가 미리 해결해준다
최적화를 수행해준다. 우리가 짠대로 컴파일하지 않고 배치를 다시 한다 어셈블리로 변환할때
디폴트로 pipeline기술이 들어가있으므로 컴파일러가 위치를 미리 바꿔놓는다
모든 hzard를 제거하기는 어렵다
forwarding bypassing 계산이 완료되었을때 결과를 바로 쓰는것
add는 메모리를 안거치니까 execution직후에 알 수 있다 굳이 write back이후가 아니라도
그래서 subtract이 사용할수 있도록 미리 보내주자 = bypass forward
데이터가 준비되는대로 ex의 입력으로 보내줌
특수한 hazar하나 더있음 lw명령어에만 한정되는 특수한 케이스인데
lw 저장되는 단계는 write back인데
ex의 입력으로 필요한 단계. lw의 ex에서 주소를 계산하는데 값은 메모리를 거쳐야만 알 수 있다.
다른건 ex이후에 바로 알 수 있었는데 lw는 메모리에서 가져와야해서 미리 알 수가 없다
그래서 mem까지는 기다렸다가 받아갸야한다.
bubble hazard를 해결하기 위해서 어쩔수없이 무조건 지연이 발생해야하는데 이것을 bubble이라고 함
아무것도 안하는 단계
control hazard 결정을 내려야함 branch hazard라고도 함
branch가 control의 flow를 결정함 원래는 pc = pc+4로 업데이트 되는데 브랜치하면 pc+4 + 4*address
branch가 true일때 그렇게 된다. 파이프라인기술에서는 바로 다음거실행해야하는데 멀리있는거면 못함
값을 비교하기위해서 빼보기 전까지 bracnh true false를 알수가 없다
MIPS 파이프라인
second stage에서 비교할수있도록 adder를 넣는다 ID에다가
컨트롤 solution
stall 무조건 기다린다
ALU에서 값이 똑같은지 비교하는데 그러면 alu끝날때까지는 기다려야함
그래서 실행할수가 없고 한단계 기다렸다가 or insruction을 실행한다.
ID단계에 alu추가하면 두번째 단계 끝나면 알게 되니까 한타임 쉬었다가 세번째에 시작한다
하지만 이 옵션의 비용이 너무 비싸다 한칸은 통째로 쉬어야하니까
이렇게 하는것보다 prediction예측
prediction이 틀렸을때만 stall하면 된다.
브랜치가 일어나지 않을거라고 predict 그럼 delay가 생기지 않게 된다
만약 점프를 해야한다고 나오면 한번 통째로 쉬고 그다음 클락사이클에 실행하면 된다
예측이 맞을때는 아무런 비용이 발생하지 않고 틀릴때만 발생하니까 훨씬 좋다
그럼 prediction을 어떻게 하느냐는 4-3
정리
파이프라이닝은 instruction througput좋아지게 한다 mutliple instruction을 병렬적으로 수행한다 하지만 각각의 execution타임은 똑같다. 파이프라인의 레이턴시는 없다고 가정했을때 똑같다는것이다
5단계가 있고 mips에서는
instruction 복잡하면 파이프라인 구현도 복잡하고
hazard가 세가지 존재한다! forwarding과 prediction으로 해결한다
스테이지가 있다는것은 순서가 존재한다는건데
hazard가 발생하는 경우는 오른쪽으로 왼쪽으로 갈때
ex의 결과가 id의 입력으로 들어가야하는 경우 시간을 역행하는 방향
파이프라인 레지스터
왼쪽을 if 오른쪽을 id
if에서 id로 새로운스테이지로 넘어갈때 전달해야하는데이터가있다
pc+4가 id단계로 넘어가야한다 instruction memory에서 결과를 넘겨줘야한다 그것도 32비트
두개의 32비트를 넘겨줘야한다 id가 실행되기 전에 데이터를 잠깐 보관하고있다가 입력으로 줘야한다
그걸 잠깐 보관해놓는 역할을 버퍼가 한다 그걸 파이프라인레지스터가 해줌
id에서계산된 결과값도 버퍼에 저장되어있다가 ex에 넘겨준다
파이프라인 레지스터의 크기도 예상해볼수있다
충분히 넓어여한다 첫번째는 64비트 두번째꺼는 128비트
write register number는 wb에서 필요하다 그래서 버퍼에 계속 저장하고 있다 wb할때까지
CC = clock cycle
vertical sclice해서 하나만 본다 여러개의 명령어 동시에 실행중
9개의 control singal이 있다
파이프라인 컨트롤 명령어
if id에서 instruction의 opcode로 디코드되어서 control box에 들어간다
그럼 control이 9개의 컨트롤 시그널을 만든다
ex단계에서는 9개중에 4개 사용하고 사라짐
5개는 다음단계 넘어가서 메모리단계 3개 나머지두개는 write back단계
pcsrc는 9개에 속하지 않는다
파이프라인버전에서 datapath control다합친 버전이 32페이지
Hazard
데이터 hazard 많은 dependency있는 상황
시간에 역행하는 방향으로 갈때 hazard가 발생한다
레지스터가 절반 나눠져서 왼쪽 오른쪽 activate되어있다
clock cycle의 first half에서 write실행 second half에서 read를 수행함
한 타임스텝을 다 쓰지 않아서 바로 전달해줄수 있는것
파이프라인 레지스터.레지스터필드
1번의 공통점은 ex/mem
2번의 공통점은 mem/wb
뒤는 idex로 동일함
ex hazard, memhazard
데이터 헤저드에서 두개로 나뉘는것이다
forwarding unit 시그널을 보내줘서 값을 넘겨준다
forwardA, forwardb로 mux를 컨트롤한다
rd가 rs로 들어가야하는상황 = forwardA
rt로 들어가야하는상황 forwardB
포워딩하려면 mux제어가 필요하고 컨트롤 시그널이 필요하다
f.a와 f.b 그 값은 어떻게 정해지냐 비트두개로 표현함 mux가 2개라서
ex해저드는 메모리 해저드보다 일찍 일어나는 상황 바로 일어나는것 그때 10
메모리 해저드는 wb까지 갔다가 rs rt로 들어가야하는 상황 01이다
그다음 a냐 b냐를 결정하는것은 rs냐 rt냐
rs에 들어가야하는 ex해저드이면 forwardA=10
rt에 들어가야하는 mem해저드이면 forwardB=01
포워딩유닛이 결국에는 mux컨트롤해서 alu의 입력을 결정하는거다
00은 해저드가 없는 정상인 상황
레지스터가 업데이트 되는 상황이고 rd가 0이 아닐때 데이터 해저드가 발생할수 있다
forwarding unit에 들어있는 알고리즘에서 판단한다
11/5
IF instruction fetch
ID instruction Decode
WB write back
CC clock cycle
데이터 해저드는 ex 와 mem이 있고 각각 a,b가 나눠진다
EX 해저드 = A가 10 B가 10, MEM해저드 = A가 01 B가 01
rs이면 A이고 rt이면 B이다
메모리 해저드 condition체크 코드 수정
위에서 계산 끝난걸 아래에서 써야하는 ex 해저드가 발생

메모리 해저드 발생함 revise해야한다
ex해저드가 발생하지 않을때로 조건 수정
ex hazard 두번으로 forwarding만 해준다
mem hazard말고 ex hazard로 해결할것으로 수정

load-use data hazard
포워딩으로 해결안돼서 버블을 쓴다.

lw일 경우에, lw의 destionation rt와 ALU의 rs나 rt와 같을때 stalling한다 = 버블
ID stage에서 detect하고 뒤에 있는 것들은 nop처리해야한다
pc와 if id레지스터 업데이트 막는다.
이전 instruction이 repeat되기 때문에
hazard detection unit이 id스테이지에 있다
IM = instruction Memory DM data memory
hazard detection unit에서 detect되면 mux에서 0이랑 연결되어서 뒤에것들을 아무것도 수행하지 않도록 해준다
control hazard = branch hazard
다음에 뭘 실행해야할지 모르는 상황
run first전략 절반확률로 예측을 맞춘다 branch true이면 예측이 틀린거니까 flush해주고 ⇒ control signal을 0으로 만든다
branch decision이 원래 EX단계에서 subtract하고 결과가 ex가 끝나면 나오니까 mem단계에 들어서면 알수있다. 너무 오래 기다려야한다. 이걸 id까지 당겨보자
추가적으로 하드웨어가 필욯다 subtract alu가 필요함
register comparator, target address adder, add IF.flush control signal이 있어야 당길 수 있다.
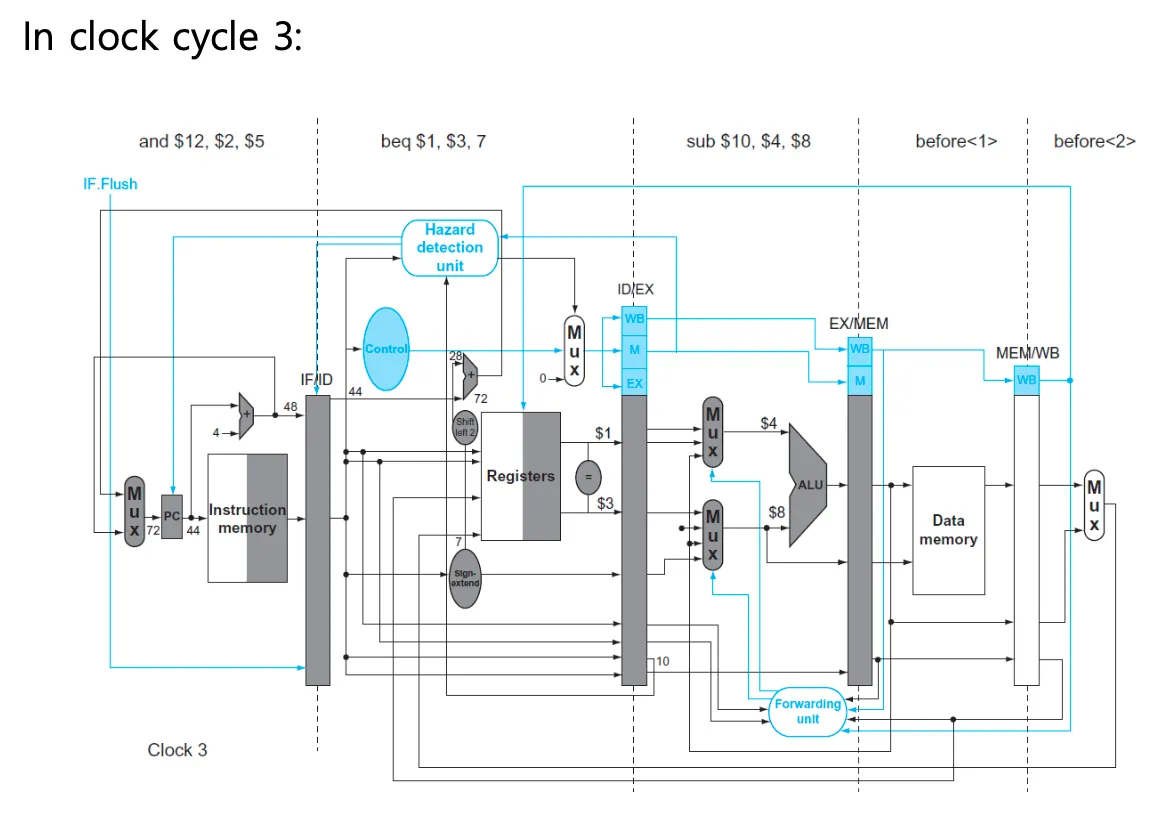
첫번째 clock cycle에서는 sub들어오고 두번째에서 beq들어오고 세번째에서 and들어옴
현재 전략은 run first무조건 다음걸 실행함. 그래서 and가 들어와있는것
sub beq는 문제없이 실행되어야한다 영향을 받으면 안되고 and만 bubble로 nop
그다음 lw를 fetch한다. 딱 하나의 버블만 있으면 해결된다
IF.Flush는 if/id pipeline register를 nop로 만든다
flush는 컨트롤 시그널에서 나온다
branch decision이 id단계에서 안되고 mem단계면 어떻게 될까?
reducing branch prediction
히스토리 정보가 예측에 있어서 중요하다.
브랜치 반응 히스토리를 저장하기 위한 버퍼 관리
최근에 브랜치가 최근에 일어났는지 안일어났는지 기록을 해놓는 버퍼 한비트정도
틀리면 flush pipeline
run first혹은 무조건 stall중에서 run first가 더 좋았는데 두개중 틀릴수있어도 훨씬 efficient하다
어떻게 예측하냐 1비트 predictor를 두고 성능은 안좋지만
마지막 iteration정보를 저장. 이중 for문에서 beq가 두개가 있고 inner loop도는 브랜치와 outer도는 브랜치 있을때 beq를 만나서 inner loop를 몇번돌고 outer loop돌고 하니까 beq도는 순간 1로 저장을 하고 다시 실행함 다음번에도 브랜칭이 일어날거라고 예측함. 몇번 맞추다가 false나고 inner 루프 빠져나올때 0으로 업데이트
outer loop돌때 다시 틀리고 1로 업데이트. 이후 inner루프에서 계속 맞고 다시 inner 루프 빠져나올때 틀린다. 빠져나올때마다 틀림
2비트 predictor ⇒ 확률이 95프로이상 나옴 4개의 state가짐
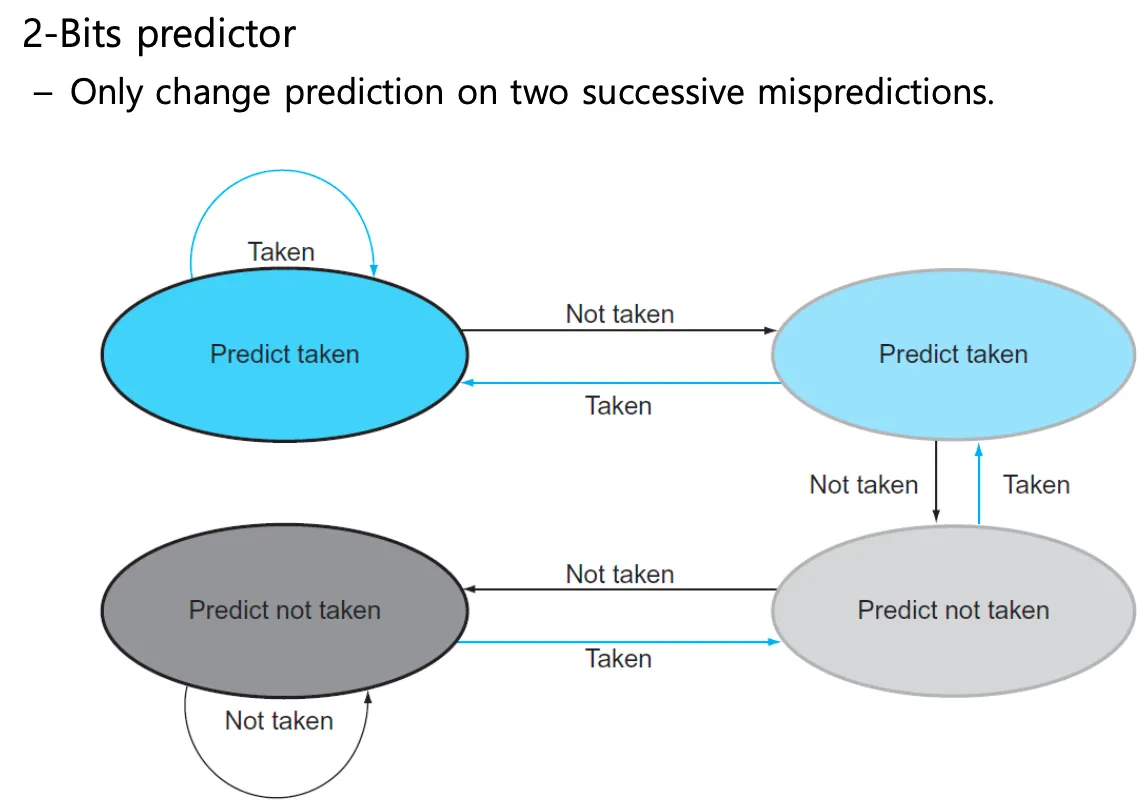
두번 연속으로 misprediction이 나오면 상태가 변경되는것 beq여러번 나와서
11 한번틀리면 10 두번연속틀리면 01
Exceptions
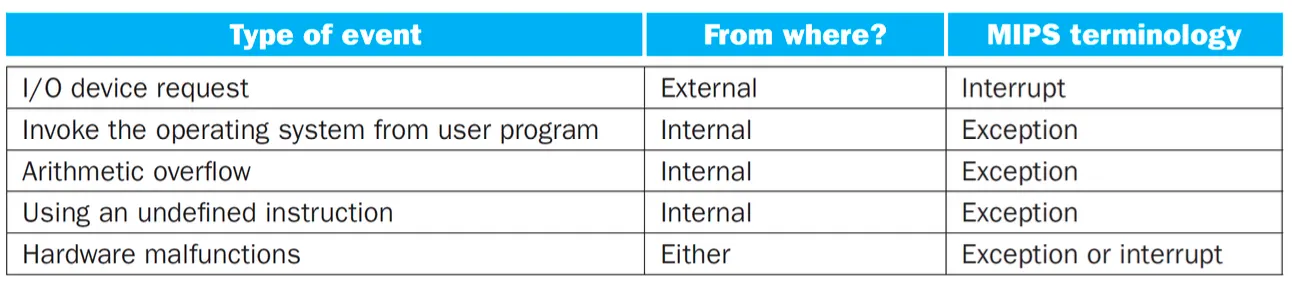
unscheduled event 프로세서 안에서 발생할수도 있고 밖에서 발생할수도 있음
안에서 발생하는것 exception 밖에서 발생하는것은 interrupt
중요한건 두가지 타입이 있다
1.
정의되지 않은 명령어를 실행할때
2.
산수연산에서 overflow가 발생할때
MIPS는 어떻게 대응하는가
현재 주소를 EPC에 저장함. = exception program counter
원인을 cause register에 저장함
5개의 비트 필드가 있는데 10이면 undefined, 12이면 arithmetic overflow
해결할수 있는 함수로 점프를 시켜줌 문제를 해결하고 다시 돌아간다
어느위치? 무조건 문제 발생했을때 점프하는 함수 주소값 정해져있다. vectored interrupts

exception 발생은 control hazard의 다른 형태라고 본다
exception발생했다는것은 정상적으로 실행할것을 점프하는것이니까
값이 업데이트되는것을 막고 이전 instruction 완료하고 다음건 ex.flush
11/7
exception 종류
undefined instruction
arithmetic overflow
EPC, cause register
epc는 error발생주소에 4를 더해서 저장
pc-relative address = pc+4
add에서 overflow발생했다면 가리키는게 pc일거고
계산이 이상한값이 나오면 해결하기 위해서 handler로 procedure로 점프함 정해진 위치. ⇒ vector address
수행하고 다시 pc로 돌아와서 수행한다면 또 오버플로우가 날거기 때문에 무한루프가 돌아서 pc+4를 저장해놓는것

add에서 문제 발생했다고 하는 경우 쭉 실행하다가 overflow발생하고 핸들러에 의해서 vector address로 점프하고 sw가 실행됨
첫번째 clock cycle은 sub and or add가 if단계일때
add는 여섯번째 clock cyclce의 ex에 있다
뒤에 slt랑 lw들어와있고
add의 문제 overflow 덧셈을 해봐야 문제가 있는지 알수있기때문에 ex오기전에는 문제있는지 알수없음 ex에서 계산될때 문제가 있는지 안다.
그전에는 문제가 없기 때문에 clock 6을 예로 든것
앞에있는 and or는 문제없게 실행되도록 두고
add를 취소하고 slt lw도 다 없애버려야 함
그래서 버블 3개가 들어가고 sw가 들어감 → vector address에서 수행하는 명령어
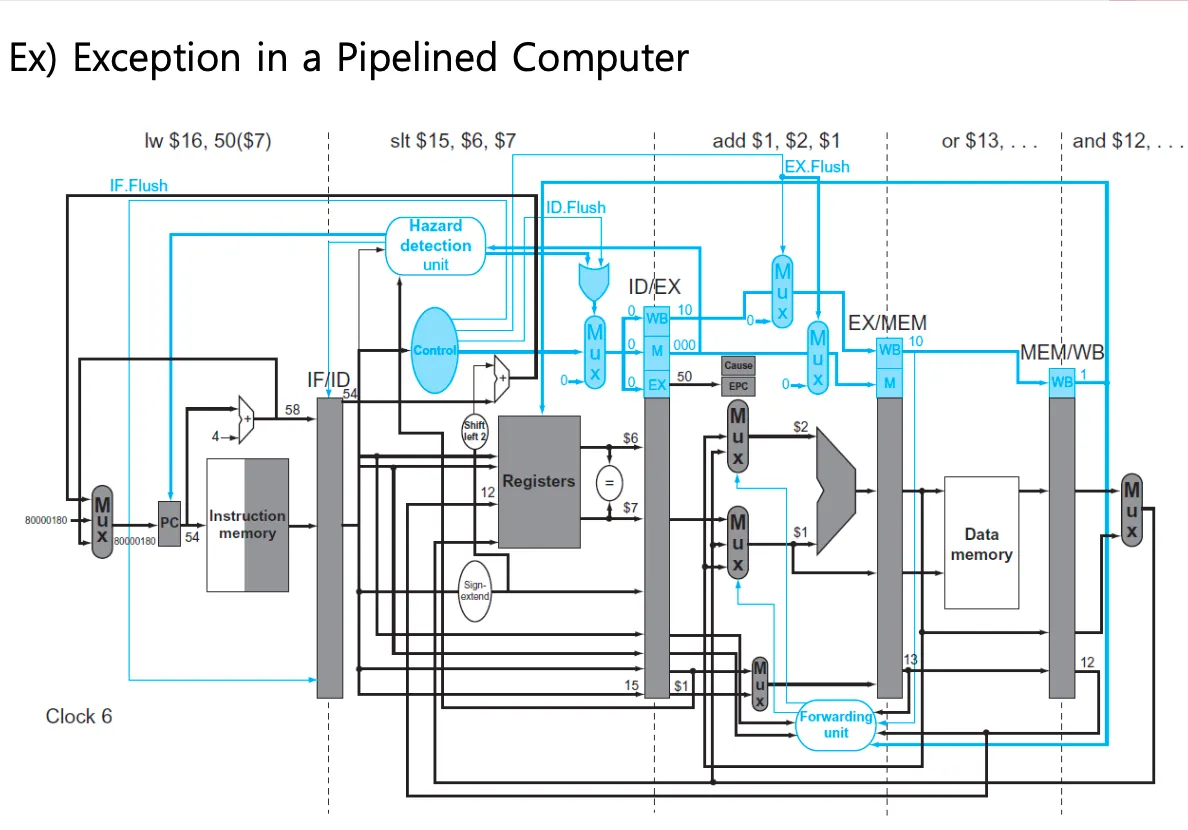
EPC에 저장되는것은 pc+4
Parallelism via Instruction
병렬성 명령어 단위로 병렬적으로 수행 ILP = instruction level parallelism
최대한 pipeline의 depth를 증가시켜야 여러 명령어가 중첩이 되는것
아무리 중첩시켜봤자 5개가 최대인데 하나의 스테이지를 많이 쪼개면 더 중복되게 할 수 있다. overlap많이 시키려면 파이프라인의 스테이지 수를 많이 늘린다 =depth를 늘린다.
single stage였던걸 잘게 쪼개면 하나의 stage가 하는 일의 양은 줄어든다
스테이지당 일은 less
clock cylce은 가장 긴거에 맞춘다. 파이프라인 버전에서는 각 스테이지 중 가장 긴거에 맞춘다. →clock cycle도 줄어든다
ILP를 향상시키기위한 첫번째 방법이었다
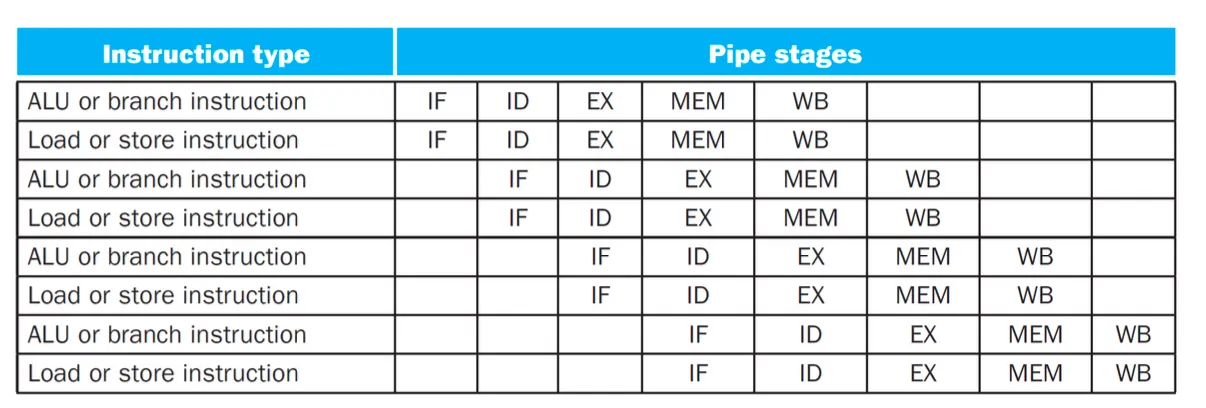
두번째는 multiple issue 한 클락사이클에서는 딱 하나의 명령어만 실행가능했는데 특정 타임스텝에 여러개의 명령어를 실행하자. clock cycle하나에 두개를 동시에 실행 issue = 실행
Replicate pipeline stages
파이프라인 하나 더 있어야 multiple 수행할 수 있다. = structural hazard 하드웨어가 더 필요함.
CPI < 1, cpi는 cycle per instruction cyclce/ instruction
한 사이클에 명령어 하나 보냈는데 mutiple issue에서는 한 사이클에 여러개의 명령어 실행하려고 하면 분모가 2가 된다 그럼 값이 1보다 작아진다
한 타임스텝에 여러개의 명령어 실행하려고 하니까 1보다 작아짐 그래서 IPC를 사용함 instruction/cycle 역수취해준것
4-way = 한 타임스텝에 몇개의 명령어 동시에? 4개
4ghz 4way multiple issue 일때
160억의 instruction을 초당 실행하는것과 똑같다 16BIPS
Peak CPI = 0.25 1사이클에 4개 실행하는것과 똑같다.
보기 불편해서 역수취한게 IPC인것
Multiple issue가 실제로 어떻게 구현되어있나?
static multiple issue
execution전에 컴파일러가 열심히 뛰어서 많은 결정을 미리 해주는 방법
컴파일러는 instruction들을 issue packet으로 그룹핑함
2-way일 경우 clock cylce 1에 위에 두개 실행 2에 밑에 두개 실행
lw add sw addi있을경우
이렇게 묶는걸 issue packet이라고 부름
CC마다 하나씩 issue packet하나씩 실행함. 하나의 instruction처럼 행동하는데 64비트로 늘어났다 32비트인데 원래 그래서 이것의 이름을 very long instruction word (VLIW)라고 부른다
컴파일러는 모든 발생할 수 있는 위험요소들을 제거함. lw add묶어놓으면 문제는 lw는 프로세서 기준으로 가져오는건데 load use hazard발생하는데
하나로 묶어버리면 동시에 실행되니까 참고할수가 없는데?? 이런 hazard를 컴파일러가 미리 확인하고 제거함. 명령어의 위치를 바꿔서 hazard발생하지 않도록 함
최적화가 코드의 순서를 컴파일러가 바꿔놓는것 미리미리 hazard제거함
static multiple issue는 많은 결정들이 컴파일러에서 일어난다!!
프로그램 실행 전이니까 static이다!
packet안에는 dependency를 최대한 줄이고 약간은 있을수 있다 피할수없다 아무리 열심히 바꿔놔도 hazard를 전부 피할수는 없다
그럼 nop로 두고 각각 실행함
lw하고 버블 들어가고 add수행
위의 두개 그룹핑해서 첫번째 clock사이클에 같이 실행 두개씩!!
2way에서는 왼쪽에 올수있는걸 한정해놓음 alu와 브랜치
오른쪽에 올수있는건 load, store
alu/branch와 load/store를 한쌍씩 실행함
hazard를 피해가려고 할때는 nop를 패딩으로 넣는다

addu lw넣으면 cc1에 ? load use data hazard발생
lw보다 addu가 먼저올수는 없다 addu의 위치를 바꿔야한다
그다음 aadu가 올까? 버블을 껴주고 실행해야한다 한사이클 아예 쉰다
addu보다 sw가 먼저 수행될수없다 t0을 업데이트하고 수행해야하니까 그래서 addu가 세번째 라인이니 그뒤에 sw넣어주는것 그래서 2,3사이클에 넣을수없다
branch는 s1업데이트 이후여야 하니까 cc4에서 실행
addi를 clock cylce1에서 수행할 수 있을까? 가능 근데 실행시간차이는 없다
two issue프로세서는 전반적으로 성능 향상시킬수있다.
하지만 상대적으로 performance loss가 발생함
data,control hazard일때
ex 해저드일때 single issue에서 forwarding을 했다. 근데 two issue에서는 load store는 alu result를 같은 packet에서 못사용함
add lw있을때 ex hazard발생할때 forwarding하면 됐는데
지금은 두개를 하나로 묶는데… 동시에 실행하면 hazard를 피해갈수가 없다 그러면 두개의 packet으로 쪼개야함.
원래 두 타임스텝에 4개 실행하는데 그냥 2개실행하게 됨 → 효율 절반
사실상 stall이 되면서 효율의 loss가 발생함
multiiple issue에서는 nop되는 칸을 최소화하는게 중요한데…
load use data hazard에서는
lw가 위에 나오고 data hazrd발생하면 한타임 쉬어가야하는데 그럼 다음 패킷은 둘다 nop된다. 한번밖에 안쉬어도 두칸을 날려버리니까 손해를 본다.
좀더컴파일러에 의한 aggressive scheduling이 필요함
Loop unrolling
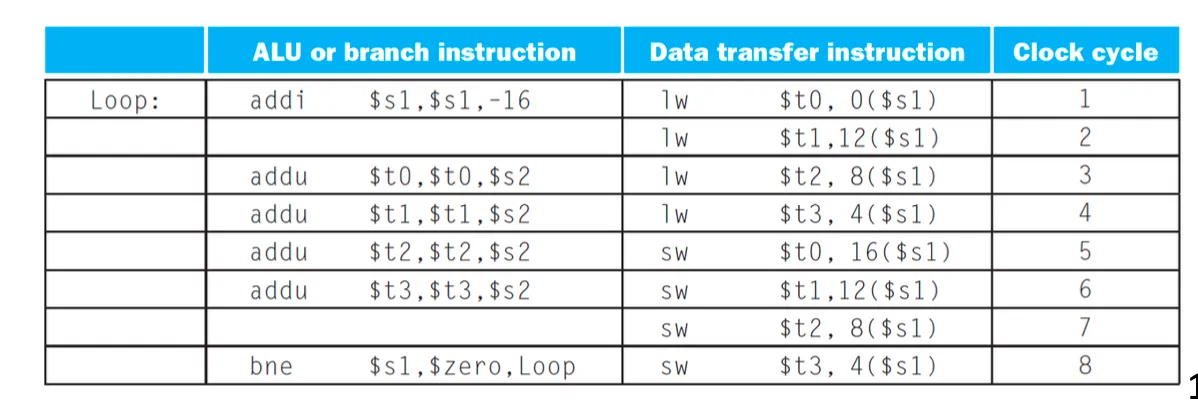
병렬성을 더 높이기 위해서 loop body를 복사
위의 예시에서는 4번 반복되기 때문에 4번 복제해서 풀어써넣는다
register renaming ⇒ hazard를 피하기 위해서
hazard발견방법은 register똑같은지 보는건데.. 레지스터 이름만 달라지면 hazard발생하지 않는다. 코드를 4번 복제할때 레지스터 이름을 다른걸로 바꿔주는것
lw t0 lw t1 lw t2 lw t3으로 이름 전부 다르도록 바꿔줌
복제할때마다 다른 레지스터를 사용하도록 한다
dependency를 제거해준다
addi한번 수행하는 이유는 4씩 빼는걸 16을 한번에 빼버림
브랜칭도 한번으로 줄어든다.
빈칸을 최소화하는게 좋다
loop를 펼쳐놓으면 빈칸을 훨씬 줄일 수 있다.
IPC는 클수록 좋다
dynamic multiple issue
single clock cycle에 여러개 실행한다
execution중에 실항할 명령을 선택한다
in-order라는 것은 순서대로
코딩한 순서대로 decode를 한다
디코딩된 정보대로 reservation에 저장해놓는다
여러가지 unit이 있고 out of order execute 순서에 상관없이 될때마다 실행함
commit은 업데이트 = in order로 명령어 실행순서대로 수행
실행은 비어있을때마다 바로바로 한다!
load use data hazard에 기다리는것보다 sub를 먼저 실행할 수 있음
Energy Efficiency
simple 코어 여러개와 강력한 코어 하나 중에 simple core 여러개가 더 효율적
트랜지스터의 수가 더 적은 코어가 더 에너지 효율적
파이프라인 stage가 depth가 깊을수록 좋아지는거 아닌가? 근데 줄이는 이유가 power때문. issue width는 4-way out of order specualtion수행
chip수가 8개로 늘어났다 에너지는 줄어들었다 파이프라인 수를 줄이고 코어를 늘리고
arm은 pmd에 들어감 휴대폰같은.
mips는 5개인데 arm a8은 14개
캐시는 메모리 5장에서 나온다
I랑 D는 instruction memory와 data memory
F fetch가 3단계 D가 5개 E가 6개의 스테이지로 되어있다
AGU address generation unit
디코드 되고 pipe0이 alu
ls는 load store
dynamic multiple 보면 load store위한 path와 int위한 path처럼 각각의 path가 나눠져 있는것
instruction 수행 및 load store하는게 E 단계
branch mispredict penalty는 커진다는 문제점이 있다
ideal cpi는 항상 0.5인데 pipeline에서 발생하는 stall이랑 메모리에서 발생하는 stall
메모리에 엑세스를 자주하는 task인가에 따라 차이가 난다
real cpi는 1.4~5.2 nop들이 들어가기 때문이다
core i7은 넘어가기 arm보다 real cpi가 개선됨
대부분의 케이스에서 브랜치 예측 정확도가 90프로 이상
하드웨어 기술발전이 파이프라이닝에 도움을 준다
ISA디자인 못하면 pipelining을 더 어렵게 만든다 complex하게 isa를 만들면 오버헤드가 커진다. hazard detect도 어렵다
instruction을 겹처서 수행할 수 있어서 throughput이 좋아지는것이다
hazard는 structural, data, control
data는 데이터 준비 안됐을때 = ex, mem해저드
control해저드는 브랜칭
해결방법은 forwarding, stall(nop) prediction
stall은 load-use 데이터 해저드 해결법
ILP = depth늘리기, mutliple issue
multiple에는 static, dynamic
complexity가 전력소비 유발
