Temporal Redundancy
동영상은 시간적으로 차이가 거의 없다. 현재 프레임과 이전 프레임을 비교할 경우 많은 영역의 화소값이 동일하고 전 화면의 정보를 이용하면 직접 화소를 보내지 않고 벡터에 관련된 정보만으로 같은 영상을 재현가능.
⇒ Temporal Redundancy를 제거하는 작업.
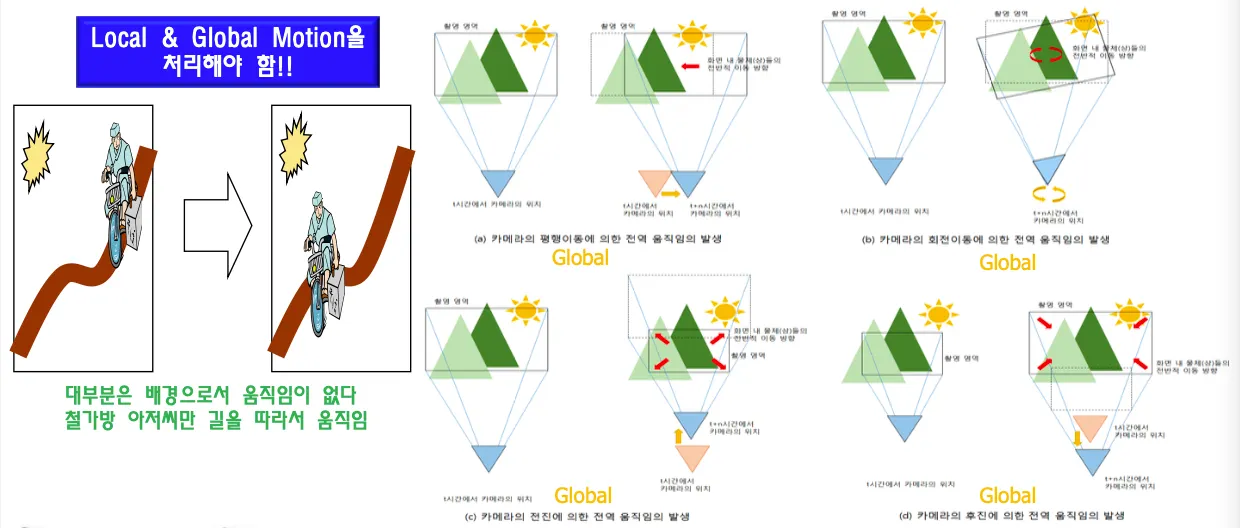
물체의 움직임(local motion)이나 카메라의 움직임(global motion)이 차이의 주 원인이다.
현재 우리의 스마트폰 액션캠같은 경우는 글로벌 움직임 보상이 기본적으로 적용되어있음
카메라 움직임에 따라서 영상에서의 움직임이 프레임 전체에 퍼진다.
카메라를 평행이동하거나 돌리거나 가까이가거나 등의 행동 ⇒ global motion 발생
글로벌움직임과 로컬 움직임을 combined motion으로 처리한다.
local motion만 처리해야하는 경우 전송해야할 데이터가 적으며 전송선로가 끊기지 않도록 가비지 데이터를 넣어서 보내줘야한다.
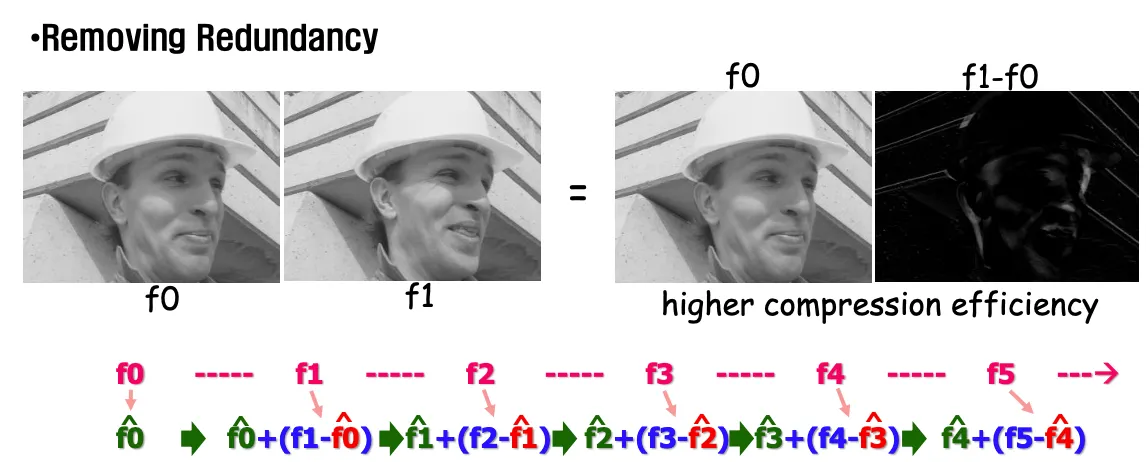
현재 영상과 이전 영상을 뺀 차영상 f1-f0을 보내면 이전 영상인 f0을 디코더가 가지고 있으므로 f1-f0을 더해 f1영상을 재현한다. f1-f0데이터를 많이 줄여서 보내는것이 중요하다.
차영상(f1-f0)의 문제점은 급격한 움직임이 나올 경우 edge(급격한 절벽)이 발생한다는 것이다. edge에 해당하는 고주파항 데이터를 전송하려면 많은양의 데이터가 필요하다.
ME&MC(Motion estimation & Motion Compensation)을 적용해서 완만화한 데이터를 보내면 크기를 줄일 수 있다.
DPCM과 VLC 인코딩을 사용하면 프레임간의 difference를 3:1의 효율로 압축할 수 있다.
Pixel level의 움직임을 정확히 계산해서 모든 픽셀에 대한 optical flow를 디코더에 보내는 방식은 정확하지만 비효율적이기 때문에 object를 블록단위로 결정해서 계산량과 정보량을 줄인다. 이것은 block level approach라고 한다. ex)말이 통째로 같이 움직이니까 말을 object로 처리

야구공이 이동한거지 새로 생긴게 아니니 움직였다는 정보만 motion vector로 보내면 보낼 데이터가 줄어든다.
f0 = 레퍼런스 이미지, f1 = current image
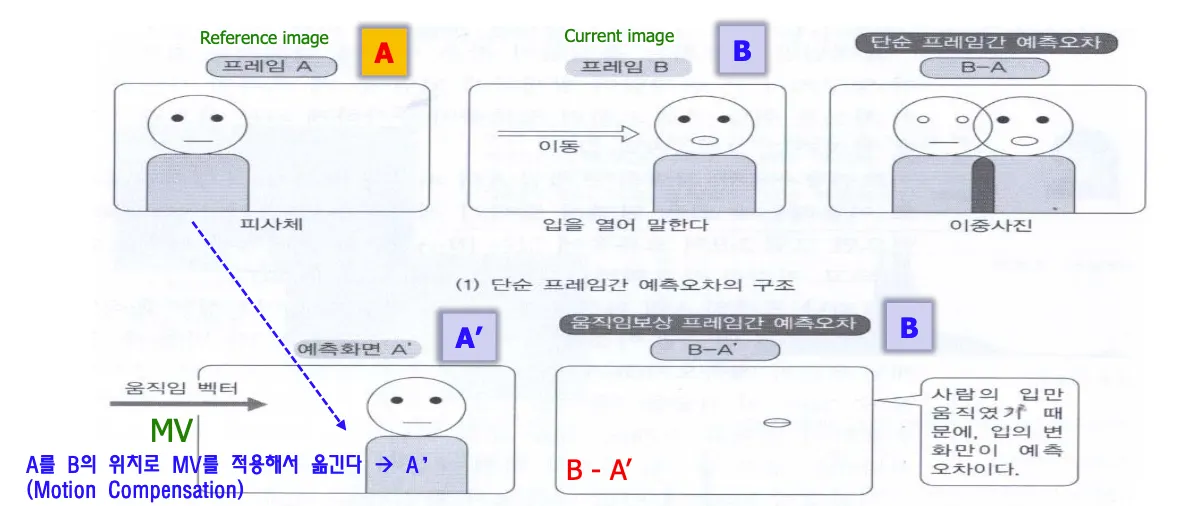

피사체가 얼마나 옮겨갔는지 motion vector를 구하는것이 motion estimation이고, A를 B의 위치로 MV(Motion vector)를 적용해서 옮기는 것이 motion compensation이다.
MC수행한 프레임과 B의 예측오차 b-A’를 구하면 차영상이 훨씬 줄어들었다.
디코더는 줄어든 차영상 = residual과 motion vector difference를 받아서 B영상을 reconstruct한다.
블록단위로 ME/MC를 수행하며 블록의 크기를 작게 할수록 residual을 많이 줄일 수 있다.
매크로블록 단위의 region이 object를 대신하고, 블록 내에서는 높은 확률로 연관성이 있는 pixel들로 이루어져 있으므로 모션은 일정한 방향과 거리를 가질 가능성이 높음.
motion이란 frame간의 object의 움직임이다.
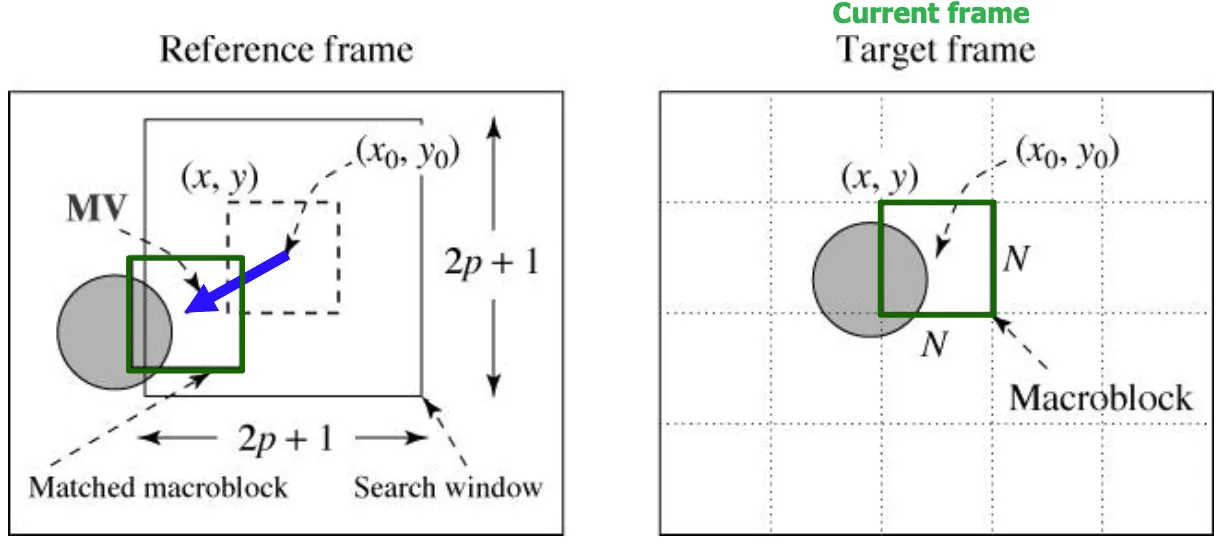
Motion Search
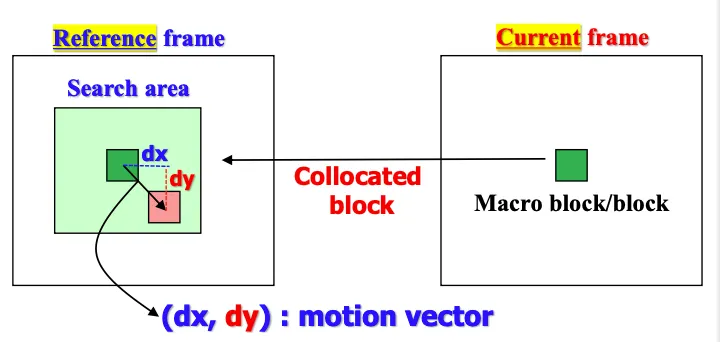
현재 프레임의 이 블록이 레퍼런스 프레임의 어디에서 왔는지를 찾는것을 template matching이라고 한다.
template matching은 블록단위가 아니라 픽셀 단위로 수행한다.
레퍼런스 프레임 주변을 search area로 설정하고 유사도가 높은 = matching하는 부분을 찾는다.
레퍼런스 프레임에서 이동한 (dx,dy)가 motion vector가 된다.
search area는 인코더 입장에서 결정하는 것이고 프레임 간에 급격하게 빠르게 움직인다면 넓게 잡아야하고 움직임이 적을때는 작게 결정해야 계산복잡도 측면에서 유리하므로 상황에 맞는 적절한 값이 선정되어야 한다.
인코더는 motion vector difference와 차영상을 구해서 보내고 디코더에서 모션벡터를 활용해 motion compensation을 수행한 이후에(레퍼런스 이미지에서 해당하는 부분을 뜯어다 갖다놓음) residual을 더해서 reconstruction을 수행한다.
cost function / Residual Coding
cost function = A와 B가 얼마나 유사한지 비교하는 척도
지금 현재 코딩하려는 블럭과 가장 유사한 region의 위치를 찾는데 유사도 판정이 필요함
매크로블록 내의 각 픽셀들의 차를 계산해서 값의 크기가 작을수록 높은 상관관계이며 만약 똑같다면 diff는 0.
diff계산은 단순화를 위해 절댓값으로 구할수도 있고, 가장 정확한건 Euclidean distance공식이다.
하지만 한 픽셀씩 shift하면서 pixelwise로 cost function 계산을 수행하므로 계산이 복잡하면 복잡도가 급격하게 올라간다.
매크로 블록의 크기가 16x16 = 256픽셀이므로 256번의 연산을 256번 수행한다. 따라서 어떤 cost function을 사용하는지에 따라서 accuracy와 time간의 trade-off가 발생한다.
SAD(Sum of the Absolute Difference)는 절댓값을 사용하는 방법으로 가장 많이 쓰이지만 정확도는 부족
MSD(Mean Squared Difference)는 유클리드 거리공식을 사용하며 정확하지만 complexity가 높다.
Residual coding은 residual을 더하는 과정을 의미한다.
Motion Vector Search Algorithms
exhausitve(Full) search
모든 픽셀에 대해서 cost weight를 구해서 best matching 블록을 찾는다. 계산복잡도가 높다.
하드웨어적으로 hardwiring해서 구현해놓으면 빠르고 간단하게 계산할 수 있지만 소프트웨어적으로는 계산복잡도가 굉장히 높기 때문에 3-step search, diamond search등으로 구현된다.
가장 낮은 cost function 위치의 x,y 위치가 motion vector가 된다.
perfect matching인 경우에는 residual을 보낼 필요가 없다.
한두 픽셀밖에 밖에 차이가 안난다면 sharp한 edge가 생기고 높은주파수의 sine wave를 많이 보내야 한다.
즉 template matching이 정확하지 않은경우 residual이 매우 커진다.
current coding block의 모션벡터를 찾는다 → reference프레임을 찾아가서 현재위치와 동일한 것에서 주변을 search range로 잡는다 → coding block을 shift하면서 template matching을 수행해서 cost function 결과값을 구하고 가장 낮은 위치를 motion vector로 정한다.
매크로블록 간에 하나씩 모션벡터가 존재한다. 모션벡터를 정확하게 찾으면 residual이 작아져서 더 적은 데이터를 보낼 수 있다. 정밀하게 수행하기 위해서는 매크로블록당 4개까지 mv수를 늘린다.
소프트웨어적으로도 reasonable한 계산 복잡도를 가질 수 있도록 해야한다.
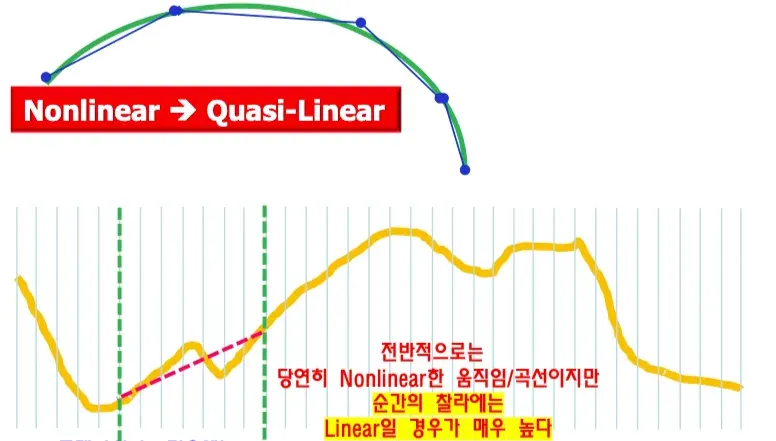
실제 자연계에서의 물체의 움직임은 non-linear하지만 순간의 찰나로 나누면 linear하다고 볼 수 있다.
점점 더 잘게 자르는 경우 차이를 더 줄일 수 있으며 직선으로 곡선을 구현한다. =quasi-linear
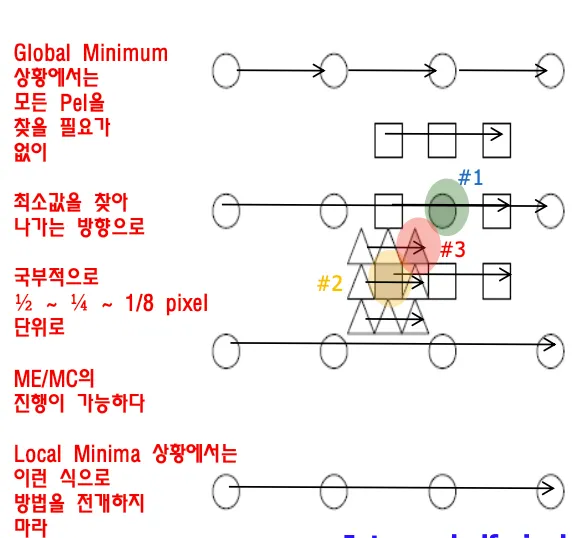
linear system의 error function은 quadratic(이차함수)이며 항상 global minimum은 아래에 있다.
non-linear의 경우 매우 많은 local minima가 존재한다. global minimun을 찾는것은 굉장히 어렵다.
quadratic형태는 항상 global minimun찾기가 쉽다. 미분해서 0이 되는 지점이다.
따라서 곡선을 quasi-linear하게 만들면 모든 weight계산하지 않아도 된다. global minimum을 쉽게 구할 수 있으므로 full search를 수행할 필요가 없다.

세상은 non-linear하지만 quasi-linear로 가정하고 fast search algorithm을 적용할 수 있다.
three step search
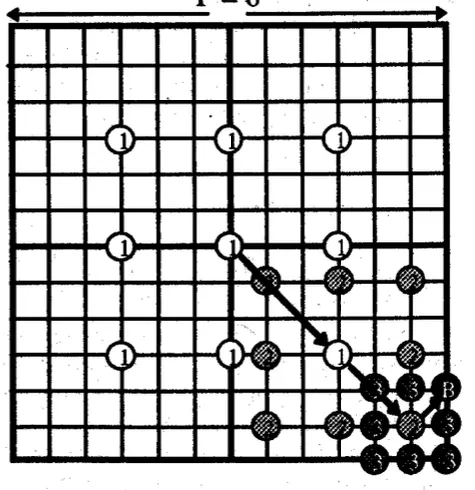
일정한 간격으로 띄워서 찾아보면서 error function의 minimum값을 찾는다.
difference가 가장 낮은 부분을 찾고 그 주변에서 또 가장 낮은 부분으로 이동하면서 조금씩 global minimum에 가까워진다.
diamond search는 대부분의 움직임이 0을 중심으로 크게 움직이지 않는다는 가정하에 가운데부터 점진적으로 찾는다
Hierarchical motion estimation
다운샘플링을 수행한 다음 motion estimation을 수행한다.
step1은 1/16크기로 다운샘플링 4X4크기로 search, step2는 1//4크기로 8X8, step3는 original 영상 크기로 16X16으로 MB Search를 수행함. Full Search보다 50배정도 빠르지만 3개의 영상을 저장해야하므로 저장공간 측면에서는 부담이 된다.
I,P and B picture
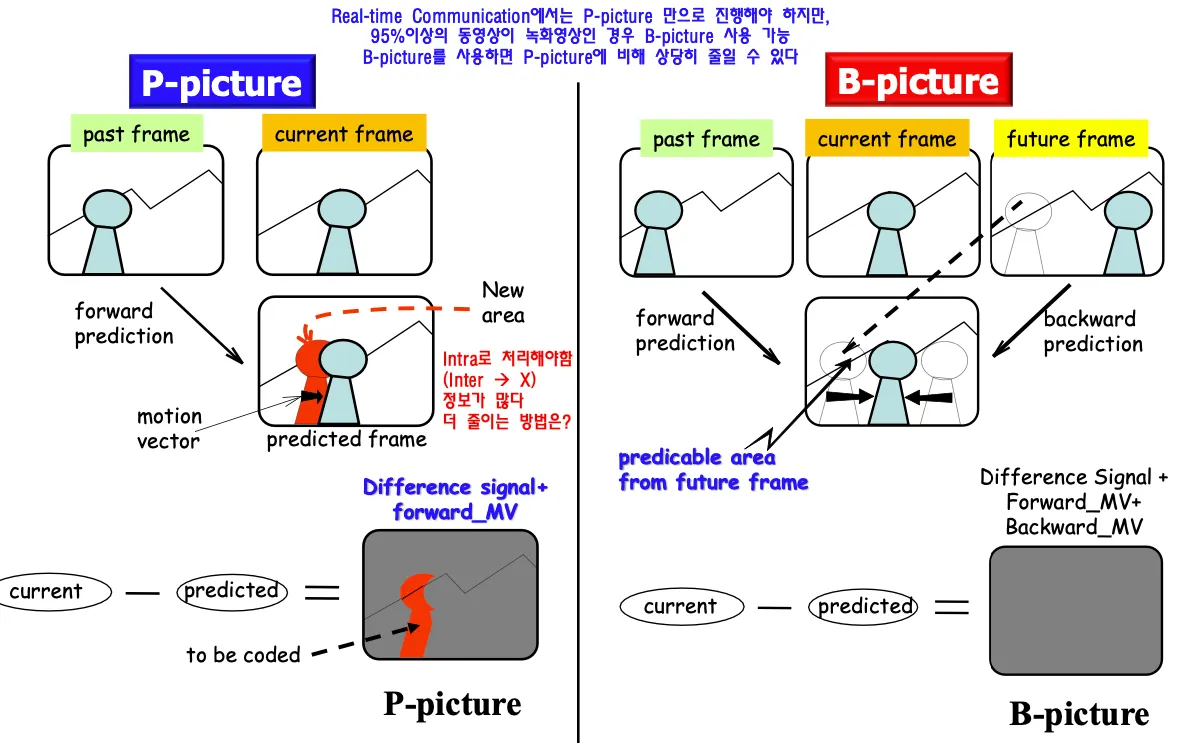
P는 predictive, B는 bi-predictive
predicted frame을 만들때 현재 프레임은 과거 프레임에서 사람 형태를 가져와서 motion vector 처리하니까 위치는 잘 처리할 수 있지만
현재 영상의 이전에 사람이 있었던 부분은 배경 영상이 없다. 이런 경우 intra로 처리해야한다 ⇒ 차영상 말고 오리지널 영상을 그대로 보내야 함. real time영상인 경우에는 그렇게 할 수밖에 없다. real time은 p-picture만의 조합으로 이루어진다.
하지만 대부분의 동영상은 미리 만들어진 녹화영상이므로 약간의 딜레이가 발생하더라도 감수하고 데이터를 줄일 수 있다. b-picture는 과거 현재 미래 영상을 다 사용할 수 있는 특징을 활용해서 과거와 미래의 프레임을 둘다 사용해서 예측한다. 과거로부터 찾는것은 forward prediciton, 미래로부터 찾는것은 backward prediciton이라고 한다. 들증 하나만 선택해서 사용할수도 있고 둘을 섞어서 interpolation할수도 있다.
미래 프레임은 과거 프레임에서 사람이 가리고 있는 부분을 볼 수 있으므로 그 부분은 미래의 정보를 이용해서 만들어낸다. 처리해야할 motin vector는 늘어나지만 residual데이터는 줄어들어서 데이터 양은 줄일 수 있다.
I-Picture는 intra coded picture이다. 맨처음 영상은 그대로 다 보내야한다. 이전영상에 대한 reference없이 보내는 정지영상. I-Picture를 듬성듬성 심어놓으면 중간에 에러 발생해도 리셋된다.
real time영상일때는 b picture없음. 무조건 과거로부터 예측한다. ippppp..
녹화된 영상은 딜레이를 허용하고 과거미래 둘다 사용해서 현재 영상을 예측해서 residual을 줄인다.
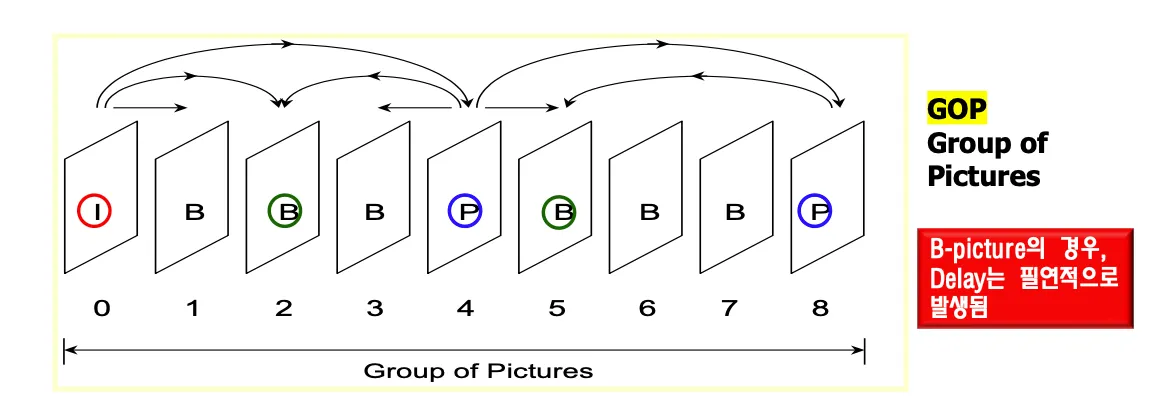
코딩순서는 04213이 되므로 0번째 영상에서 1번째 영상사이에서 딜레이가 발생한다.
i와 p사이에 있는것을 B로 코딩해서 데이터양을 줄인다. ibbbpbbbp
sub-pixel motion compensation
정수 샘플과 sub sample(1/2, 1/4 pel 등)을 탐색해서 보다 정확하게 motion estimation할 수 있다.
정확하게 motion estimation을 수행하면 edge를 줄일 수 있으므로 압축률을 높일 수 있다.
sub-pixel은 실제로 존재하지 않는 값이지만 만들어내서 low pass filtering한 효과를 내며 단차를 줄일 수 있따. integer pel단위보다 더 정확한 움직임을 찾을 수 있으며 최근에는 1/8pel도 사용한다.
단차를 어쩔수없이 보내야하는 상황 보내려고 하면 좁고 날카로운 절벽이 발생되고 전송해야하니 압축률이 떨어짐
픽셀등 사이를 확대해서
붙어있는 픽셀들 사이를 확대하고 그 사이를 interpolation으로 채워넣는다.
1/4 pel 단위로 sub-sampling을 수행하려면 모든 픽셀에 대해서 수행하기에는 계산복잡도가 높으므로 quasi-linear한 특성을 이용해서 global minimun에 접근하고 그 주변을 1/4 pel을 적용한다.
따라서 best integer matching을 찾고 → 1/2 pel 단위로 best matching을 찾고 → 다시 그 주변에서 1/4pel 단위로 best matching을 찾으면 된다.
이렇게 수행하면 complexity가 많이 늘어나지 않는다.
Summary
I-frame 코딩은 YCbCr으로 6개의 블록으로 나눠서 DCT+양자화 수행하고( loss발생) → VLC하고(lossless) → 비트스트림으로 만들어서 보낸다.
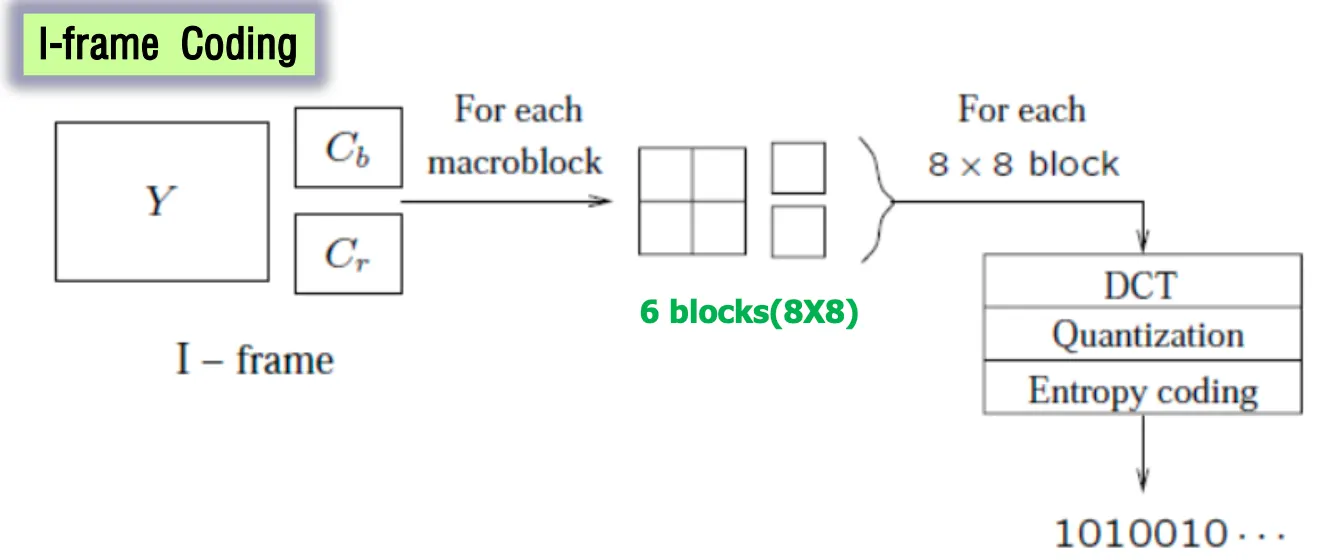
For each 8X8 block a DCT transform is applied, the DCT coefficients then go through quantization zigzag scan and entropy coding.
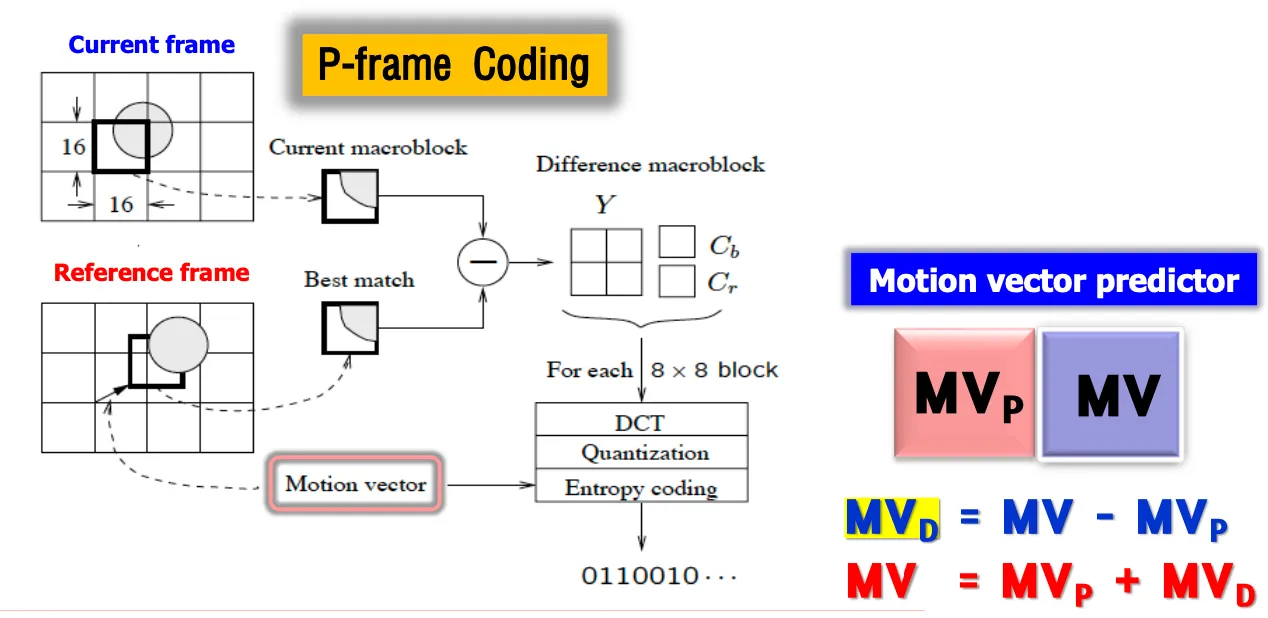
P-frame코딩의 경우는 현재 프레임과 레퍼런스 프레임(과거영상 reconstructed)간 모션을 찾는다
current프레임 위치를 reference프레임으로 가져가서 그 주변에서 search area잡고 cost function수행해서 찾고 모션벡터를 구하고 보낸다. current의 매크로블록(오리지널)과 best match된 reconstructed 영상의 차를 residual로 보낸다.
매크로블록단위이므로 y4개, cbcr1개씩 차영상이 만들어지면 그걸 DCT 양자화 엔트로피 코딩해서 zigzag스캔 수행하고 비트스트림으로 보낸다.
디코더는 motion vector difference와 자기가 가지고 있는 motion vector predictor를 더해서 mv를 재현하고 그 모션벡터 위치에서 블록을 가져와서 residual을 더해준다 → motion compenstaiton
B-frame에서는 현재와 미래 둘다에서 모션벡터 두개 가져오고 residual값은 둘중 하나를 빼서 구하던지 둘의 interpolation을 사용한다.

I가 보내야할 데이터양이 가장 많고 P > B 순서이다. B가 압도적으로 작다.
B-Picture는 3가지 motion type이 존재하며 디코더는 어떤 타입의 매크로블록이 인코더로부터 전송되는지 알 수 있어야 한다. MVD를 보내기 전에 먼저 제어신호를 보낸다. MC유무에 따라 있으면 Inter, 없으면 intra이다.

Motion compensation하는 경우에도 모션만 보내는지 residual을 같이 보내는지로 구분된다.
따라서 비트스트림으로 보내야하는 데이터는 세가지이다. 매크로블록 타입, MVD, residual
매크로 블록 타입으로 어떤 데이터를 보내고 어떤걸 안보낼지 알려준다.
레퍼런스 프레임 또한 reconstructed된 영상이다!
