
Docker Storage
도커에서는 4가지 스토리지 타입 존재함.
volumes, bind mounts, tmpfs, named pipe이다.
tmpfs, named pipe는 리눅스인 경우와 윈도우인 경우로 platform dependency가 있고 많이 사용되지 않음.
컨테이너는 임시적으로 살았다 죽는 존재인데 데이터를 어떻게 저장할까?
Docker Storage는 전적으로 임시방편에 해당한다.
컨테이너는 임시로 살아있는 것이기 때문에 persist를 위한것이 아니다.
필요할때 필요한만큼 만들고 죽였다 살리는데 죽을때 흔적을 남기는게 살아나는 애한테 영향을 주는건 컨테이너 철학에 맞지않다.
컨테이너의 writable layer로 host machine의 파일시스템에 접근한다. 컨테이너는 disk processing용이 아니기 때문에 기본적으로 잘 사용되지 않고 host가 직접 사용하는것보다 performance가 떨어진다.
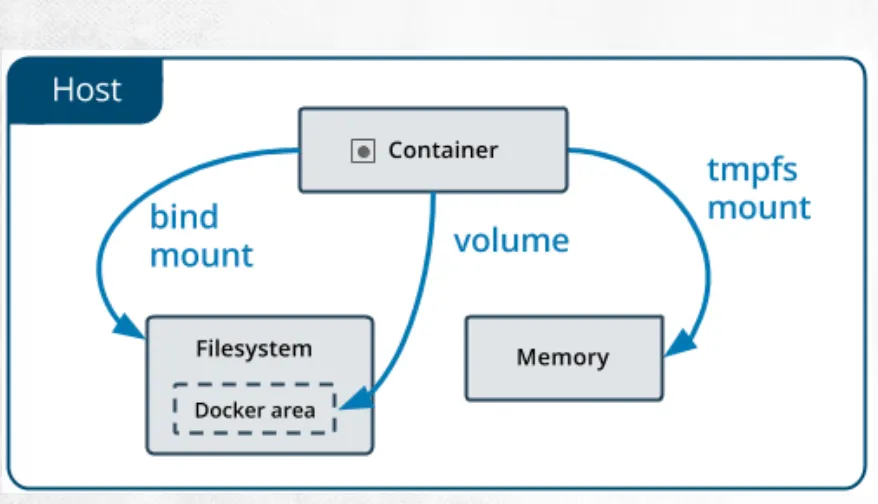
컨테이너에서 host컴퓨터의 파일시스템을 향하고 있음.
도커 엔진이 실행되고 있는 컴퓨터의 디스크를 향하고 있다. 즉 컨테이너 바깥에 저장한다.
bind mount
bind mount나 volume을 사용해서 컨테이너가 어떤 형태의 파일 만들거나 작업하는 경우 host에 저장된다.
host컴퓨터에 만들어지는 정보는 컨테이너의 사라짐과 함께 사라지는 임시정보라고 보는게 맞다.
volume은 파일시스템에서 도커 엔진을 실행하는 컴퓨터 디스크 내부의 docker area를 사용한다.
docker area는 도커 엔진이 만들고 관리하는 공간이라서 개발자나 운영자가 직접 접근하는것을 권장하지 않음.
디스크를 꽂아서 리눅스가 인식해서 디스크를 운영체제가 쓸수있게 해주는 상황을 mount라고 부른다.
bind는 운영체제의 중재하에 특정 디렉토리를 어플리케이션이 사용하도록 매핑해주는것이다.
즉 bind mount는 이미 디스크에 있는 폴더를 컨테이너가 접근할 수 있도록 매핑해주는 것이다.
Bind Mount는 호스트의 특정 디렉토리를 컨테이너와 연결해 이미 존재하는 데이터를 컨테이너가 사용할 수 있게 하고, 원격 스토리지로도 연결할 수 있다. 컨테이너가 종료되어도 호스트의 데이터는 사라지지 않는다.
컨테이너는 bind mount로 연결된 스토리지를 자신의 디스크처럼 인식한다.
이미 존재하는 데이터를 기반으로 프로세싱을 위한 컨테이너에 연결하는 형태로 많이 사용한다.
volume
volumes 또한 host machine에 저장되는건 맞는데 도커에서 관리하는 방식이다.
volume도 스토리지의 일종이며 컨테이너가 죽어도 volume은 남아있다.
docker area는 host mahcine에 있는데 컨테이너가 알아서 처리하다가 죽을때 반납하며 외부에서 접근할 수 없다.
volume은 도커가 만들고 관리한다. multi-container가 volume을 동시에 접근하는 경우도 가능하고 데이터의 전후관계가 있다면 volume에서 한 컨테이너가 먼저 volume에 프로세싱한 데이터를 기록하고 다음 컨테이너가 그 데이터를 기반으로 작업하도록 pipelining할 수 있다.
volume에 데이터를 기록하는 방법은 도커 cli와 daemon간의 http통신이므로 원격으로 데이터를 기록할 수도 있다.
docker volume create //볼륨 만들어라
prune //지워라
C++
복사
bind mount는 host machine의 어디에나 연결된 곳에 데이터를 저장한다.
non-docker process이므로 컨테이너가 살아날 때 반드시 있어야하는 것은 아니다.
tmpfs
temporary filesystem
컴퓨터 메모리를 디스크처럼 쓰는 기법이다.
프로그래밍할때는 파일시스템에 저장하는것처럼 느끼나 실제로는 메모리를 디스크처럼 쓰는 기법이다.
파일시스템은 HDD,SSD,메모리로 매핑이 되도록 운영체제에서 구현되어있다. 디스크를 추가하면 루트 폴더 밑에 폴더형식으로 추가된다. 디스크가 아닌 메모리를 파일을 저장하는데 사용하는건 옛날에는 일반적인 기법이었다.
DuckDB같은 데이터베이스가 그런 기술을 사용해서 메모리를 DB로 쓰기 때문에 빠르다.
데이터를 빨리 처리해야하는 경우 사용할 수 있지만 전원 끄면 사라지는 temporary 데이터이다
named pipe
A프로그램과 B프로그램이 메모리를 공유
과거 tcp http없던 시절에도 애들을 대화시켰다
TCP, HTTP가 없던 때에 프로그램끼리 메모리를 공유하게 만들기 위해서는 A가 전달할 데이터를 메모리에 쓰고 B 프로그램이 읽어가는 형식이었다. 이 메모리를 byte 가지나가는 pipe라는 뜻으로 named pipe라고 불렀다
모던에서는 메모리 공유하는 행위는 금지되어있고 통신기법으로 주고받거나 두개의 thread간에 안정적으로 주고받을수 있는 기법을 언어차원에서 제공한다.
Jenkins
자동화 서버 소프트웨어이다. 웹브라우저를 통해 접속해서 사용한다.
빌드, 배포과정을 자동화해준다.
언어마다 다양한 플러그인을 제공한다.
docker run -p 8080:8080 -p 50000:50000 -v
myvol-1:/var/jenkins_home jenkins/jenkins
YAML
복사
jenkins는 서버로서 외부와의 통신을 두개 가지고 있어서 포트매핑을 두 번 한다.
8080은 유저 엑세스용 포트이고 50000번은 디폴트로 jenkins가 사용하는 포트이다
myvol-1에 필요한 정보 저장하라고 하면서 실행하는 것이다.
Jenkins를 실행해서 작업을 수행하고 컨테이너를 종료했지만 다시 실행하면 id,password 등의 configuration을 그대로 사용할 수 있다. myvol-1 volume에 저장되어있기 때문이다.
execute shell 터미널에서 손으로 실행해야할 명령을 입력해놓는다.
리눅스 계열은 shell예서 명령을 칠 때 스케줄러 기능이 있음
손으로 타이핑해야할 명령들을 텍스트로 저장한 파일 .bat batch의 줄임말이다. batch처리는 하나씩 순차적으로 처리하는 형태를 말하며 하나씩 쳐야팔 명령어들을 하나의 파일에 모아놓은 것이다.
>>는 파이프라이닝으로 유닉스 명령어에서 한 명령의 실행 결과를 다른쪽으로 전달하는 명령이다.
cat hello.txt >> hello2.txt
YAML
복사
유닉스 프로그램 철학은 프로그램이 외부로부터 입력을 받고 자신의 데이터를 외부로 보낼 수 있는 것이다. 그래서 입력 파라미터 argc argv와 return값이 존재한다
일일이 쳐야할 명령을 bat파일에 저장하고 앞의 명령에서 수행한 결과를 전달하려고 pipeline을 구현하고 나중에 실행하고 싶어서 스케줄러 기능을 만든것이다. 호출해야할 프로그램이 다양해지고 복잡화되니 범용 소프트웨어로 등장한 것이 jenkins인 것이다. 기존에 하던 CI와 CD작업을 유닉스의 기능을 바탕으로 자동화하는 소프트웨어일 뿐이다.
