
swarm = 떼거지로 몰려다니는 애들
도커 엔진들이 뭉쳐서 소프트웨어 실어나른다
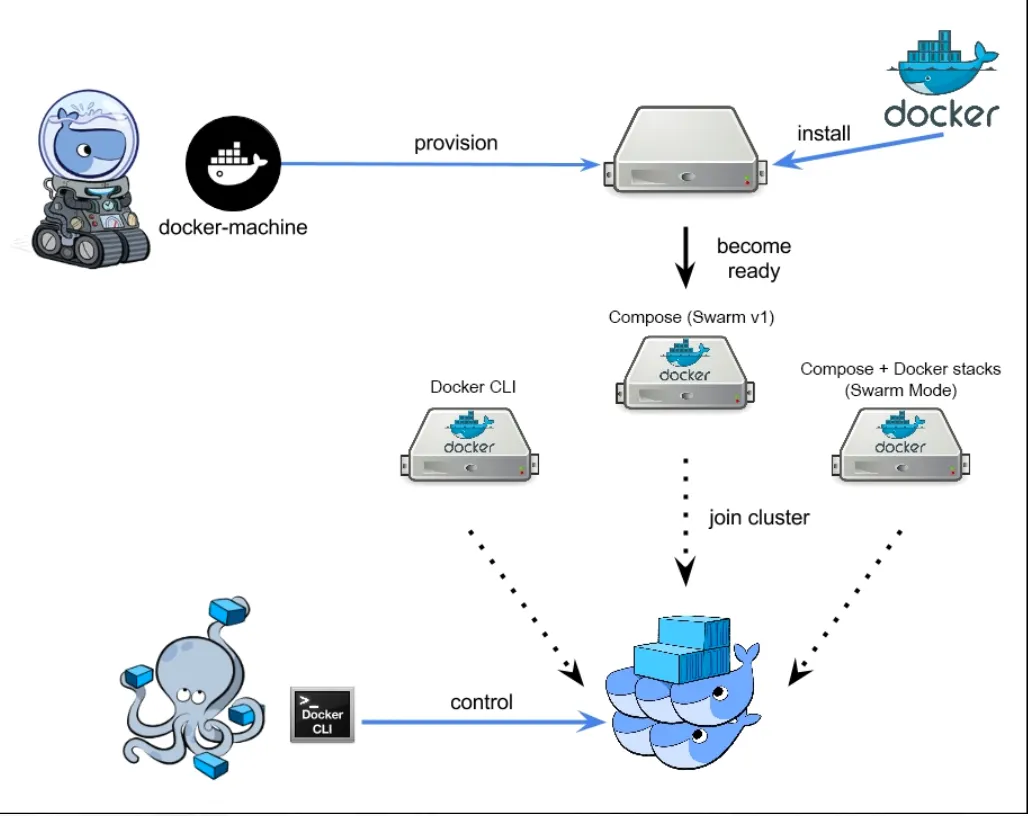
여러개의 고래들이 컨테이너 실행 멀티노드를 하나의 논리적인 것으로 묶어주는것이 도커스웜이고 yaml파일 작성해서 수행시키면 반영해서 컨테이너 실행 운영체제가 알아서 코어에 일은 분장하는것처럼 여러개의 노드들의 상태를 보고 분배한다
cluster management가 따로 필요할수도 있다 회사가 다르면
swarm이랑 비슷한게 쿠버네티스
join leave 명령 그대로 쿠버네티스에서도 이어진다
multi contianer가 하나의 목적으로 잘 운영되도록 한다
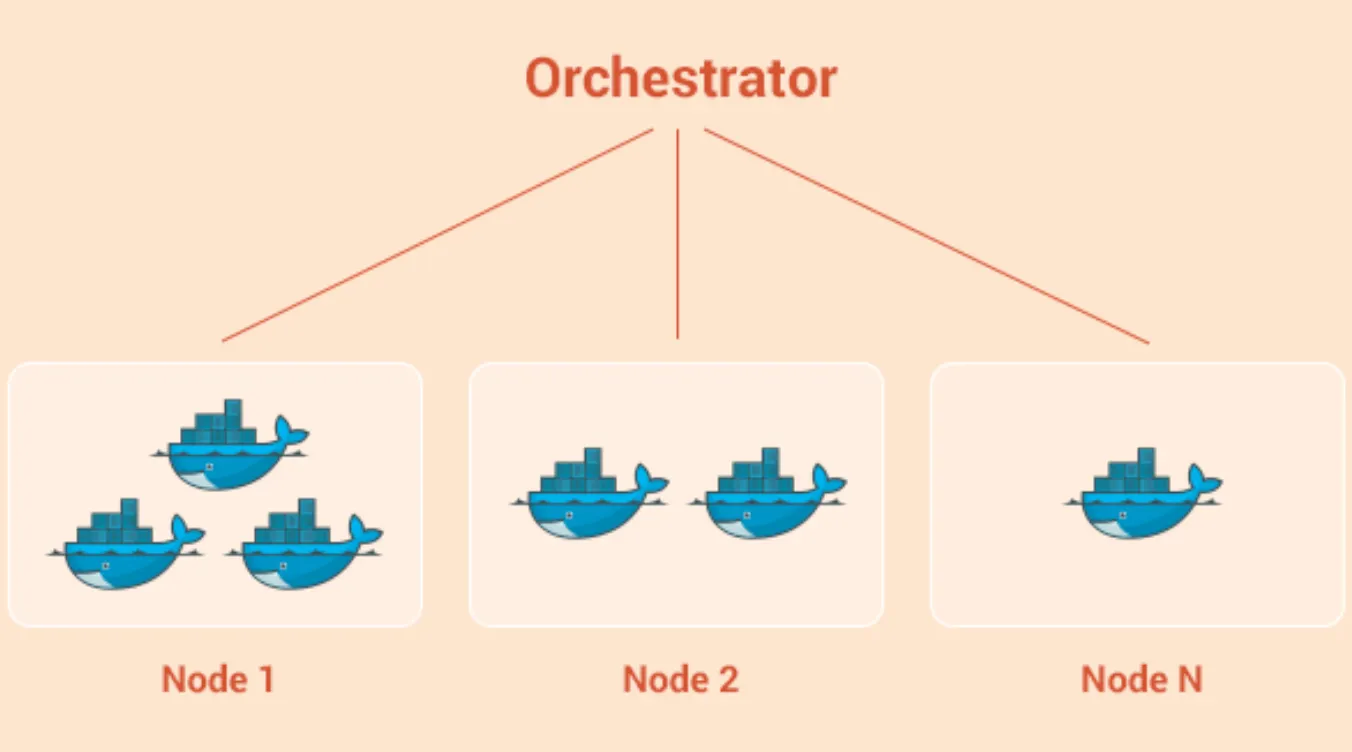
orchestrator가 컨테이너들을 하나의 cpu코어인양 누가 일을 많이 하는지 적게 하는지 죽을거같은지를 관리한다
docker compose 쓰면 알아서 두개이상의 컨테이너들 간의 네트워킹도 해주고 한꺼번에 설치 삭제도 해준다 이런것들 오케스트레이터의 역할이기도 하다
서로 떨어져있는 컴퓨터간의 통신도 똑같이 가상의 네트워크로 묶어주고 scaling, 관리 등을 한다
운영에 대한 이야기다!!
컨테이너를 관리하는것을 오케스트레이터에게 맡긴다
도커와 쿠버네티스가 처음에 하나였다가 갈라섰다
Mesos
도커와 쿠버네티스 나오기 이전에도 오픈소스 없어도 알아서 사용했다 애플이 사용하던게 mesos였다
2015년 쿠버네티스가 1.0 출시
2015년 9월에 도커스웜 등장. 각자따로 진행되다가
11월에 쿠버네티스 서포트하겠다고 함
2017년에 쿠버네티스는 대놓고 도커 api호출하고 도커에서 만든 이미지로 실행함 몇년간 지속되다가 이혼함 하지만 legacy를 가지고 있기때문에 이후에도 하나인양 돌아갈 수 있는 프로그램 만듦. 도커 데스크탑.
도커 데스크탑에 쿠버네티스가 들어가있음.
쿠버와 도커사이에 제3지대가 생김 도커가 아닌 다른 컨테이너 수행시키는 환경도 수용해서 표준화된 scheme 도커뿐만 아니라 어떤 회사라도 실행할수있도록 하는 제3지대를 만듦. 제일유명한게 containerD
표준화된 인터페이스로 맞추고 containerd로 맞춰서 실행할 수 있도록 함
그럼에도 설치되어있는 이유는 중간자를 두지 않고 쿠버는 도커 도커는 쿠버를 호출했는데 상당기간 도커데스크탑 안에는 직접호출하는걸 유지했는데 이제는 도커데스크탑도 제3자거쳐서 도커 수행하도록 함 d= daemon
아무튼 쿠버네티스와 도커스웜은 독립적인거구나 스웜도 오케스트레이터다!
스웜의 역할
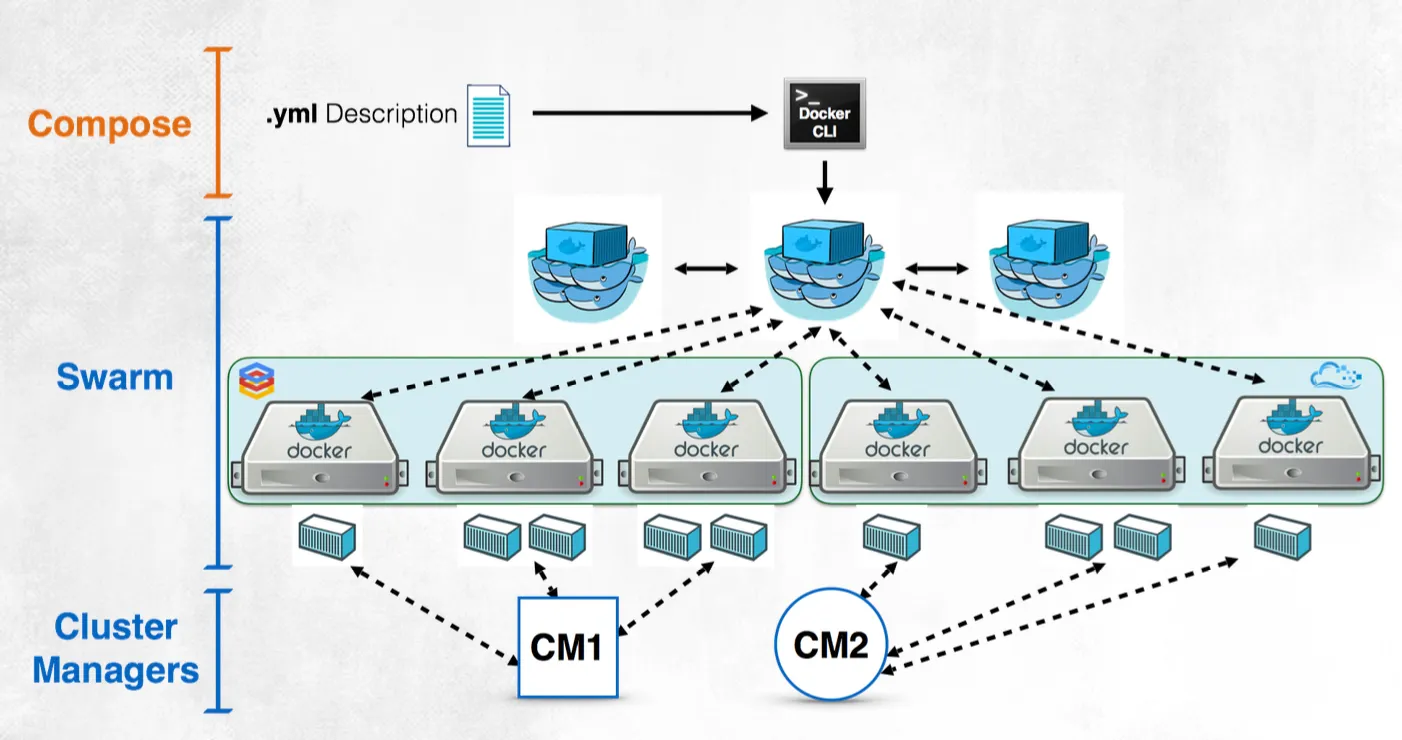
머신을 그룹으로 만든다 여러개의 도커호스트들이 하나로 되어있는 상황에서 위에서 컨테이너를 띄울테니 띄우고 조절하기위한 매니저가 있고 노예처럼 와서 붙는 worker노드가 있다. 여러개의 호스트 노드 중에서 하나를 대장으로 두는것
필요한 미니멈의 노드수는 하나다 쿠버네티스는 2개를 두라고 함
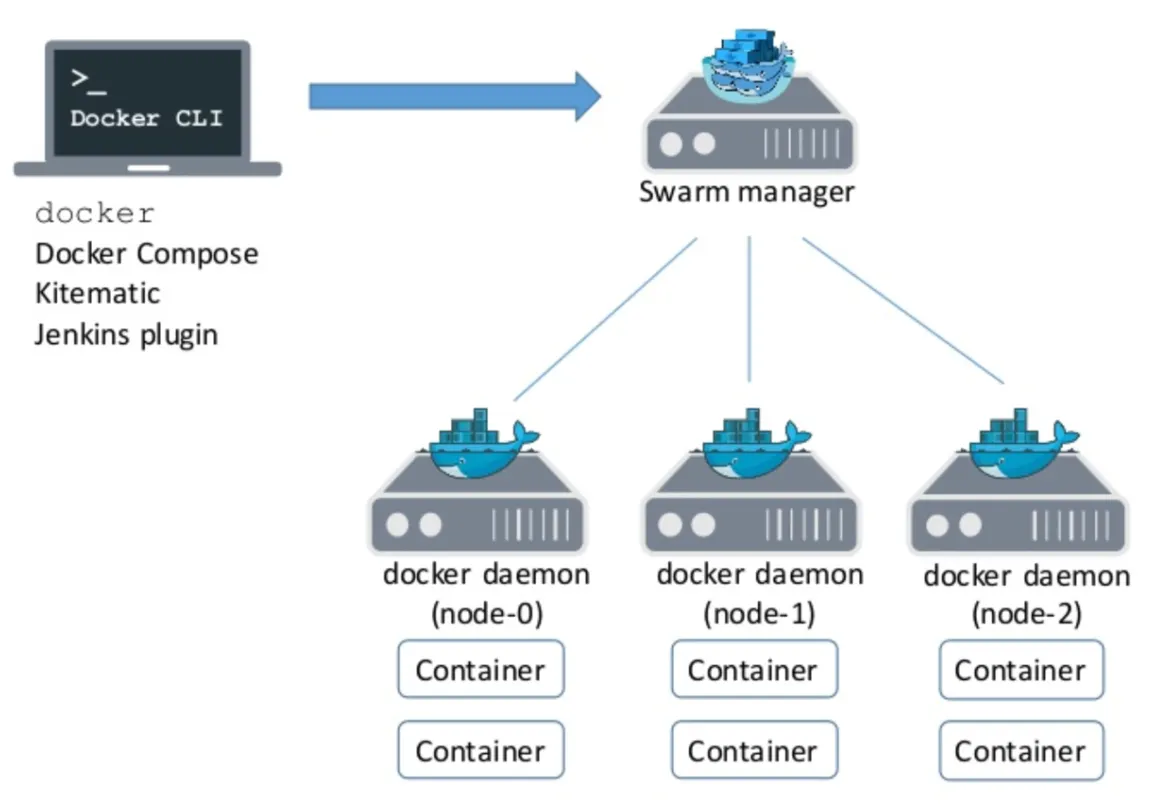
일꾼들에게서 컨테이너가 실행이 된다
매니저의 cli로 접속해서 지금하던 행위와 동일하게 컨테이너 실행하면 된다 어디서 실행할지는 swarm이 판단한다.
도커엔진 도커cli docker desktop docker swarm다 들어있는거다 이미
노트북이 매니저이면서 cli 매니저에게 연결될 worker node를 확보해야함
물리적인 컴퓨터 vm들을 묶어서 하나의 논리적인 컴퓨터처럼 보여주는거
논리적인 컴퓨터로 묶여있으니 나는 컨테이너 띄우면 된다. orchestrator
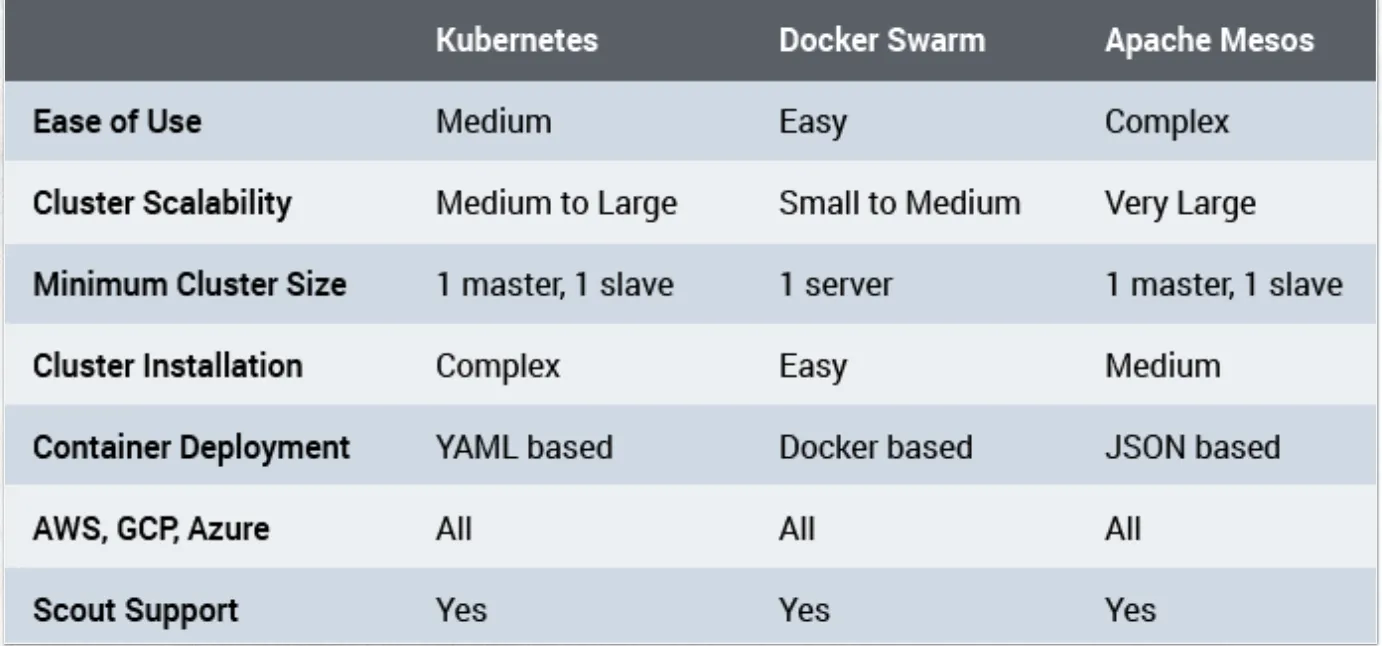
swarm은 작은거 쿠버는 큰거
도커머신
가짜 ip지만 ip까지 docker-machine ip worker2
docker-machine ssh manager 매니저 컴퓨터로 들어간다
머신가져오고 운영체제 도커엔진 ssh 서버 설치 하나의 명령어로 편하게 하는게 도커머신
docker-machine ssh{manager name}\
docker swarm init--advertise-addr{manager ip}
JavaScript
복사
swarm을 초기화 매니저를 대장으로 삼아서 worker노드들이 붙는 논리적인 한대의 컴퓨터를 만든다 대장임을 각인시킴 매니저야 초기화해라 니가 대장이다 —advertiese-addr 대장임을 알려라 address를 알려라
docker swarm을 사용해서 도커데몬서버에게 swarm의 대장이니 다른 애들이 붙을수있도록 하고 ip주소를 기억해라
swarm이 초기화되고 현재 노드는 지금부터 매니저입니다
논리적인 하나의 컴퓨터를 만드는거다 대장을 뽑았다
worker를 더하기 위해서 swarm에다가
대장이 생겼으니 docker swarm join으로 join하도록 한다
매니저의 ip와 포트번호 주고 토큰을 준다 s로 시작해서 v로 끝나는 암호키
토큰을 알아야 join가능하다
표준포트가 2377
worker1으로 ssh로 들어가서 join실행
leave명령어로 떠나게 한다 그럼 down상태가 된다
컴퓨터 묶어서 하나의 논리적인 컴퓨터를 만들고 manager 설정하고 클러스터의 멤버가 되도록 join 그리고 끝나면 leave
우리가 실행시키는 orchestrator들은 많은 프로그램들로 실행되고 있다 init했더니 매니저 정해지고 join하려면 포트넘버 정해져있고 swarm에서 init하는건 오케스트레이터 데몬이 실행되는것 별도의 포트넘버가 있는것
굉장히 많은 프로그램들의 연합체. swarm안에도 프로그램들이 많고 서로 통신한다
그래서 몇개는 포트가 사용될수 있도록 보장되어야하고 포트 막으면 안됨
구글의 클라우드 서버 아마존 클라우드 서버 내 컴퓨터 묶을수있는데 포트넘버는 열려있어야하고
컴퓨터가 멀리 떨어져있어도 하나로 묶을수있고 포트를 열어야 통신하고 클러스터링할수 있다.
docker stack
논리적으로 묶여있는 클러스터를 도커에서는 스택이라고 얘기한다
하나의 거대한 서비스 실행하기 위해서 수많은 마이크로서비스때문에 다양한 yml파일이 쌓여서 stack이 된다 그냥 yml파일인데
라벨은 중간지대에 존재하는데 도커에서는 쓸일없었지만 쿠버에서는 많이 쓴다
매니저가 아닌 경우에 대해서만 nginx를 실행해달라
인프라와 상관없이 컨테이너 띄울수도 있지만 constraint줄수도 있다
대전에서 데이터분석 돌리면 대전에 있는 노드에만 컨테이너 띄우기 등 내가 돌리는 프로그램은 gpu만쓸거니까 특정 gpu만 쓰기 하드웨어 dependency있게 만들기 그런 constraint을 쓰는거다
컨테이너도 메모리 cpu gpu등을 기술할 수 있다 iac는 물리적인 것까지 포함
내컴퓨터 파일을 원격서버에 복사 scp, ftp 파일을 보내는 방법
scp secure copy
스웜에서 실행시키려면 스웜한테 yml을 실행시켜달란 명령 docker stack
docker run으로 시작해서 compose로 갔다가 stack이 됐지만 하는건 똑같다
두개의 노드에서 실행중인 4개의 컨테이너를 rm하면 오케스트레이터가 정리해줌
그다음은 노드 leave
swarm에 조인한 worker만 leave할게 아니라 매니저도 떠나라고 해야한다 그럼끝
머신만들고 swarm init으로 대장 만들고 worker join시키고 실행시킬 yml파일 준비하고 yml파일을 매니저에게 주고 매니저에서 docker stack deploy로 실행시킴 이후는 알아서 4개가 실행됐고 스택 지우고 worker leave manager leave 도커머신 중지
도커스웜은 노드 하나 꺼지면 그냥 죽는데 쿠버네티스는 하나 꺼지면 돌려달라는거 다른 노드에서 더 띄움
비정상적인 상태에서 어떻게 대처할수 있는건지를 보여줌 safety의 차이가 난다
서버는 누군가가 노가다하고 있기 때문에 돌아가는것 하드웨어때문 죽는게 정상이다 그래서 대처가 필요함. 망가진거 확인하고 누가 갈아끼우는 사람이 있다
회사에서는 임베디드할때 관계도에 따라 dependency뽑아내서 넣는다 #include iostream를 다 넣는게 아니라.
컨테이너 실행되는 노드들의 온도를 알아야한다 그게 휴대폰에 들어가있다 열받으면 프레임 낮춘다
온도 알려주는 api있거나 노드들에 온도센서 장착해야한다
이건 도커와 쿠버네티스의 몫이 아님 온도센서 정보 받아서 컨테이서 상황 파악해서 백업.
프로세서 아키텍처 알고 있으면 constranint로 더 좋은 성능 뽑아낼 수 있다
프로세서들은 이진트리 구조로 연결되어있음
평균전압으로 0,1 구분
전압이낮으면 cpu가 중간중간 일을 놓침 프로그램이 정상작동 하기도 하고 비정상작동하기도 한다
전압이 불안한 곳으로 수출한 경우 프로그램이 돌다가 이상해짐
docker-compose.yml 파일을 docker stack deploy 명령어로 Swarm 모드에서 실행하면, Manager 노드가 자동으로 로드 밸런서를 통해 워커 노드들에 작업을 분배합니다.
동작 방식
1.
서비스 배포와 작업 분배
•
docker stack deploy 명령어를 통해 배포된 서비스는 Swarm에 의해 여러 노드에 복제(레플리카)됩니다.
•
Manager 노드는 서비스에 정의된 replicas 설정에 따라 각 워커 노드에 컨테이너를 분배하며, 각 서비스의 상태를 모니터링하고 복제본을 관리합니다.
2.
내장 로드 밸런싱
•
Docker Swarm은 서비스 단위의 로드 밸런싱을 기본 제공합니다. 따라서 클라이언트가 서비스에 요청을 보내면, 요청은 Swarm의 내부 네트워크를 통해 사용 가능한 컨테이너에 고르게 분배됩니다.
•
모든 Swarm 노드는 로드 밸런서 역할을 할 수 있습니다. 예를 들어, 클러스터 내의 어느 노드로 들어온 요청이든지 Swarm 네트워크를 통해 자동으로 해당 서비스의 가용한 컨테이너로 라우팅됩니다.
3.
외부에서의 접근
•
docker-compose.yml의 서비스에 외부 포트를 설정하면, Swarm은 로드 밸런서를 통해 지정된 포트로 들어오는 외부 요청을 적절한 컨테이너로 분배합니다.
•
예를 들어, 아래처럼 ports를 지정한 경우:포트 80으로 들어오는 모든 요청은 Swarm 로드 밸런서를 통해 3개의 web 컨테이너로 분배됩니다.
services:
web:
image: nginx
ports:
- "80:80"
deploy:
replicas: 3
YAML
복사
Docker Compose 파일을 사용해서 Docker Swarm에서 서비스를 쉽게 배포하고 관리할 수 있습니다. 이를 통해 두 툴의 기능을 연결하는 효과를 얻을 수 있습니다.
1.
Compose 파일로 Swarm에서 스택 실행
Docker Compose의 구성 파일(docker-compose.yml)을 그대로 활용하여 Swarm에서 서비스를 실행할 수 있습니다. Swarm은 Compose 파일의 정의를 읽고 각 노드에 컨테이너를 배포합니다. docker stack deploy 명령을 통해 Swarm 모드에서 Compose 파일을 기반으로 서비스를 배포할 수 있습니다.
bash
Copy code
docker stack deploy -c docker-compose.yml <stack_name>
Shell
복사
2.
Swarm에서 Compose 파일을 확장 가능하게 사용
Compose 파일을 Swarm에서 사용할 때는 추가적인 기능, 예를 들어 각 서비스의 replicas 설정이나 네트워크 및 볼륨을 여러 노드에 걸쳐 사용할 수 있도록 조정하는 방식으로 확장됩니다.
요약
•
Docker Compose는 로컬 개발 환경에서 멀티 컨테이너 애플리케이션을 쉽게 실행할 수 있게 돕는 툴입니다.
•
Docker Swarm은 멀티 노드에 걸친 오케스트레이션을 지원하며, 프로덕션 환경에 적합합니다.
•
Docker Compose 파일을 Swarm에서도 활용할 수 있어, 개발과 배포 환경에서 동일한 설정 파일을 공유할 수 있다는 장점이 있습니다.
Docker Compose
•
목적: docker-compose.yml 파일을 사용해 여러 컨테이너를 정의하고, 로컬 개발 환경에서 멀티 컨테이너 애플리케이션을 쉽게 구성하고 실행합니다.
•
사용 대상: 일반적으로 단일 호스트(즉, 하나의 컴퓨터나 서버)에서 멀티 컨테이너 애플리케이션을 실행할 때 사용합니다.
•
오케스트레이션 기능: 기본적으로 오케스트레이션 기능(자동 복구, 스케일링)은 없으며, 간단한 멀티 컨테이너 애플리케이션을 실행하고 관리하는 데 집중합니다.
Docker Swarm
•
목적: 여러 호스트(서버) 간에 컨테이너를 관리하고 분산시킬 수 있는 오케스트레이션 툴입니다.
•
사용 대상: 여러 노드에 걸쳐 분산된 컨테이너를 관리하며, 고가용성, 복구 기능, 스케일링이 필요한 프로덕션 환경에 적합합니다.
•
오케스트레이션 기능: Docker Swarm은 자동 복구, 부하 분산, 스케일링 등 다양한 오케스트레이션 기능을 지원합니다.
Docker Swarm에서 오토스케일링은 Worker 노드의 수를 늘리는 것과 컨테이너(서비스)의 수를 늘리는 것 두 가지 방법으로 구현될 수 있으며, 이 둘은 서로 다른 목적을 갖고 있습니다.
1. Worker 노드의 수를 늘리는 오토스케일링
•
목적: 클러스터의 전체 용량을 확장하기 위해, 즉 더 많은 컨테이너를 실행할 수 있도록 리소스를 늘리는 것입니다.
•
작동 방식: 추가된 워커 노드는 클러스터에 연결되며, Manager는 새로 추가된 노드로 컨테이너를 분배할 수 있습니다. 이로 인해 클러스터가 더 많은 서비스와 작업을 처리할 수 있게 됩니다.
•
예시: 트래픽이 증가하여 기존 노드의 CPU나 메모리 리소스가 포화 상태에 가까워질 때 새로운 워커 노드를 추가하여 리소스 여유를 확보합니다.
2. 컨테이너(서비스) 수를 늘리는 오토스케일링
•
목적: 클러스터의 특정 서비스 인스턴스를 확장하여 요청 처리량을 증가시키기 위함입니다. 예를 들어, 트래픽 증가로 인해 웹 서버 서비스 인스턴스를 여러 개로 늘려야 할 때 유용합니다.
•
작동 방식: Manager가 기존 워커 노드들의 리소스를 고려하여 더 많은 서비스 인스턴스를 스케줄링합니다. 이 과정에서 특정 서비스의 복제본(레플리카) 수를 늘리면서 오토스케일링을 실행하게 됩니다.
•
예시: 웹 서버 서비스의 복제본을 5개에서 10개로 증가시키면, 트래픽이 분산되어 응답 속도가 개선됩니다.
Manager가 컨테이너를 실행하지 않는 것은 아닙니다. Manager 노드도 워커 노드 역할을 겸할 수 있으므로, 기본적으로 컨테이너를 실행할 수 있습니다. 하지만 클러스터의 안정성과 성능을 위해서 일반적으로는 Manager 노드에서 워크로드를 최소화하거나 아예 컨테이너를 실행하지 않도록 설정하는 것이 좋습니다. 예를 들어, --availability pause 옵션을 통해 Manager 노드가 컨테이너를 실행하지 않도록 할 수 있습니다.
현재 있는 컨테이너에 들어와있는 사용자들이 다 나갈때까지 기다렸다가 setting바꾼 새로운 컨테이너로 데이터 옮기고 과거는 죽인다
사실상 docker swarm에서 로드밸런싱 scale up down서비스 업데이트 정도 해주는데 이정도 기능으로도 괜찮으면 docker swarm쓰는거다!
근데 더 필요하면 쿠버네티스를 쓰게 된다.
서비스 기반 아키텍처
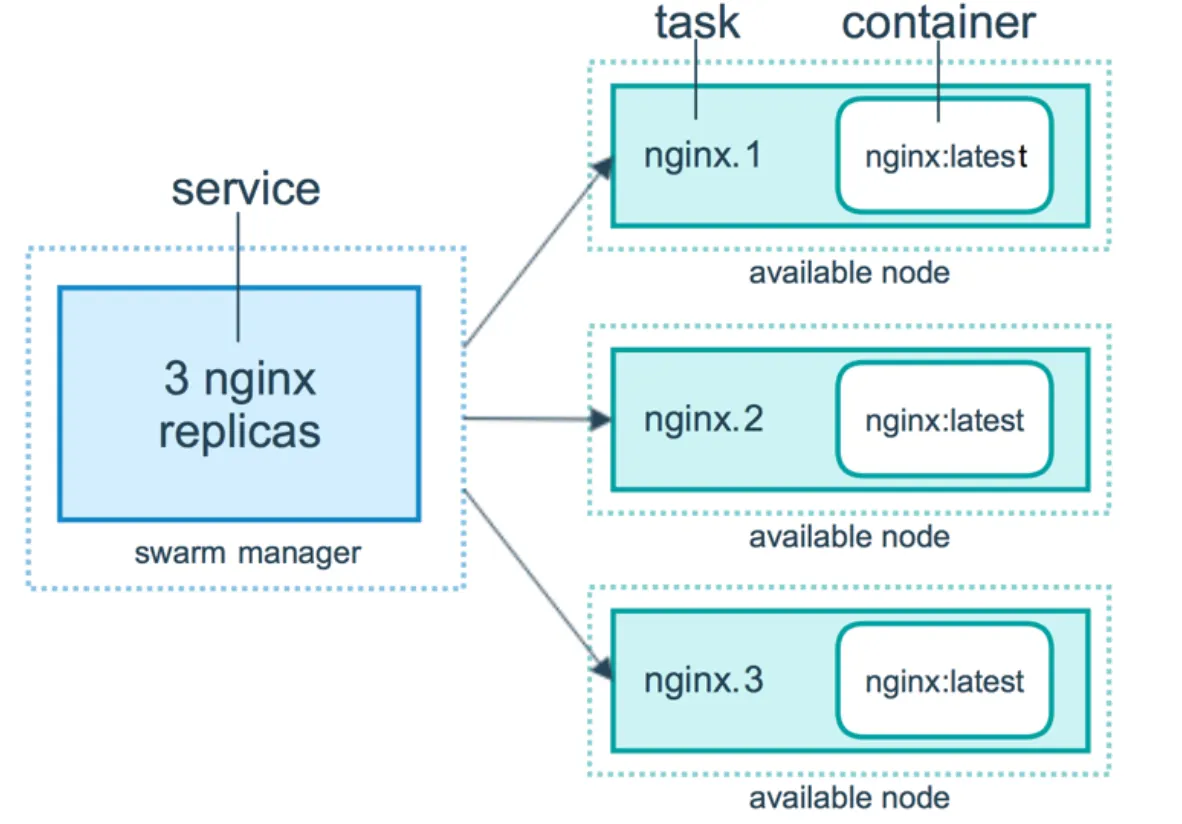
Docker Swarm은 개별 컨테이너를 생성하는 대신, 모든 작업을 서비스라는 단위로 관리합니다. 서비스는 여러 개의 컨테이너로 구성된 스케일 가능한 그룹으로, 자동으로 네트워킹 기능이 추가됩니다.
서비스의 주요 장점은 컨테이너의 복제본 수를 쉽게 조정할 수 있고, 자동으로 로드 밸런싱 및 장애 조치(failover)를 지원한다는 것입니다.
스택 파일(Stack Files)
Swarm에서 애플리케이션을 구성하고 관리하기 위해 스택 파일이라는 YAML 형식의 매니페스트 파일을 사용합니다. 이 파일은 Swarm 애플리케이션의 모든 구성 요소와 설정을 정의합니다.
스택 파일을 사용하면 다양한 환경에서 애플리케이션을 쉽게 생성하고 파괴할 수 있습니다.
스택 파일의 구성 요소
스택 파일에는 서비스, 네트워크, 볼륨 등 여러 구성 요소가 포함될 수 있습니다. 예를 들어, 여러 개의 서비스를 정의하고, 이들 사이의 네트워크 설정을 지정할 수 있습니다.
