
k8s cluster service
desired state management
worker = container host kublet실행
매니저 위치에 해당하는 애가 있고 worker에 해당하는 애가 있고
yaml 파일 사용해서 매니저를 통해서컨테이너들을 실행
차이가 있는건 worker에 있는 kublet 매니저에 연결된다
도커스웜에서는 docker engine을 설치했는데 하나를 매니저라고 하고
쿠버네티스는 주종관계가 확실함. worker는 kublet이라는 agent프로그램 설치되고 join leave동작을 한다.
yaml파일이 있기는 한데 container감싸는 pod이라는게 존재
docker cli를 쓰지 않음
pod을 2개 만들어서 pod1안에 있는거랑 pod2안에 있는것끼리 대화하도록
worker kublet경량화
api호출 동일한데 굳이 강조하지 않고
yaml파일 서비스 동일한데 pod단위로 한다
가장 극단적으로 다른건 load balancing은 같지만 desired state가 있다
가장 극적으로 다른건 docker swarm은 도커에게 명령을 내린다 쿠버네티스는
cicd에 기반한 인간을 대체하는 기능을 원했기 때문에 desired state 서비스 운영하기 원하는 사람이 쿠버네티스에게 희망의사를 밝힘 희망하는 바에 대해서 쿠버네티스에게 의사표명 부탁하면 쿠버네티스가 부탁을 받아서
docker swarm에서 노드 죽이면 죽는다 그냥
쿠버네티스는 희망하는 상태에 따라서 쿠버네티스가 부합하도록 다른 worker로 옮겨준다. 희망한 상태를 맞추기 위해서 쿠버네티스가 직접 개입
그런 작업들이 미리 짜져있다
강력하게 배를 운영하는것을 표현 조타하는 사람이라는 뜻
management of containerized applications
desired 상태에 도달하도록 노력함
쿠버네티스는 실제로 서비스하면서 늘리고 줄이는 용도이다
컨테이너 orchestrator
쿠버네티스 이전에도 아마존 등은 수천만개 프로그램 이미 실행해왔다
borg논문 구글에서 나온것
large scale cluster management
2015년 docker container활성화된 시점
도커 컨테이너 쿠버네티스 얘기 안나옴
쿠버네티스 아니다
borglet worker들 마스터 필요한 작업을 이들에게 내린다
c++로 짰다
두번째 논문 omega
flexible scalable scheduler
jupiter rising
네트워크를 만들었다 장치를 직접 만들었다 하드웨어 운영체제 통신 프로토콜 등을 다 만들었따 서버 소프트웨어 개발자의 요구를 받아서
서버간의 트래픽 양이 50배 늘어났다 그래서 직접 하드웨어 네트워크 장치 소프트웨어 통신 프로토콜을 다 만든것
컨테이너까지는 사람들이 관심이 없었다 흥미로운 장난감정도 인식 근데 kubernetes나오고 cloud native computing foundation이 만들어졌다
sandbox 프로젝트 아직 성숙하지 않아서 테스트중
이전에는 클라우드 컴퓨팅 기반 cpu disk network 수천 수만개….
심플해졌다 클라우드 native하다고 한다. 수천수만의 cpu disk network를 필요한만큼 쓸수 있다. 클라우드 native를 하는데 개발 방법론으로 devops cicd를 병행한다. 그걸 platform engineering이라고 한다
클라우드 컴퓨팅 컨테이너 오케스트레이터 cicd devops할줄 아는 사람
cncf에서 graduated 상용 가능한 서비스
이미지 변경도 할 수 있고 하드웨어 기타등등에 문제가 발생했을때 대처도 할 수 있고 명령받는애가 아니다 요청하면 필요할때 알아서 restart move해준다 개수맞춰주고 등등..
포켓몬고
클라우드 컴퓨팅 주 고객은 벤처회사가 많았는데
당시 포켓몬고 예상 트래픽을 훨씬 넘었다 50배정도
쿠버네티스가 포켓몬고 서비스를 실수없이 커버하는것을 보고 검증된다
vm비즈니스를 열심히 하다가 vmware가 vm회사인데?
linux over linux문제로 딱히 중요하지 않다고 했는데?
컨테이너나 orchestrator를 가장 많이 얘기하는곳 중 하나가 vmware
컨테이너 개수가 압도적으로 늘었다 vm보다
왜 굳이 컨테이너가 좋다고 할까?
unicorn project 피닉스 프로젝트 읽기
직접 구축할수 있는 사람수는 얼마 없어서 vmware가 돈으로 해결해준다 기술지원해줌 vmware도 경량화되어있다. 그래서 이유가 뭔데?? 교수님한테 질문
docker는 개발도구 kubernetes는 운영도구
pod으로 묶어서 pod을 실행하면 컨테이너 및 데이터베이스 있고
pod안에 있는걸 docker나 dockerswarm을 실행하라고 명령 kuberenes는 지시가 아니라 희망상태를 쓰고 줘서 맞춰서 실행하달라고 요청
version control, 노드 죽었을때 다른데서 돌리는것 등
쿠버네티스 버전업 됐다는건 사람이 직접하던 일이 프로그램화되어서 들어가있거나 몰랐던 일에 대해서 프로그램이 처리하는것들이 추가된것
전원케이블 뽑지마라고 하는 이유
하드디스크는 mechainical한 장치 디스크를 읽고 있다가 arm이 추락해서 디스크에 bad sector가 발생함
11/18
k8s = kubernetes k와s사이에 알파벳이 8개가 있어서
node묶여서 클러스터에 컨테이너 띄운다
pod과 ingress?
도커아닌 podman등으로도 컨테이너 만들고 k8s로 실행할수있다
pod안에 복수개의 컨테이너가 들어있고 ip address주어진다 복수 컨테이너들의 집합인 pod은 하나의 ip 주소를 공유한다
쿠버네티스는 서비스 운용 입장이라서 개별 컨테이너보다 그게 모여서 의미를 갖는게 중요하고 pod이라는 개념이 가장 작은 운영입장에서의 block이다
노드로 만들어져 있는 클러스터 위에서 pod을 실행한다
pod의 구성요소 컨테이너들, 스토리지, unique ip address
ip주소는 pod단위로 쿠버네티스가 주고 컨테이너들은 동일한 네트워크 공유
바깥하고 통신할때에는 숙명적으로 하나의 ip주소를 공유해야해서 nat address translation처럼 다른 포트 쓰는 상황도 고려를 해야한다!
pod안에 이종의 컨테이너와 별도의 데이터베이스
worker node는 kublet이라고 부르는 agent가 있어서 docker swarm때 master join처럼 클러스터 구축하도록 join하게 한다
도커스웜과 똑같이 manager worker init join leave등을 한다
노드의 집단을 클러스터라고 하고 멀티노드를 logical 한컴퓨터로 만들었다
cpu가 4만개 ram 320이고 노드들 들어오고 나가는 행위로 증가 줄어들기 하는것
대부분 전문적인 서버 스토리지, 원격지에 분리된 보안된 스토리지 등을 사용한다
쿠버네티스는 스토리지가 powerful하다 실제 필드에서 전문적인 스토리지팀이 다룬다 클라우드에서 안정적으로 보호받는 network로 접근하는 storage
실행하라고 desired state전달하면 요청상태와 클러스터 상태 보고 할당한 후 유지되도록 끊임없이 모니터링한다
쿠버니테스는 yaml파일로 서비스 실행할때 deployment라고 한다
replicas = 4 ⇒pod을 4개 띄워줘 yaml파일에 desired state작성
서비스 deployment하면 쿠버네티스가 실행한다 개발자는 desired상태 제공하고 쿠버네티스가 내가 제시한 상태를 만들어준다. 쿠버네티스는 많은 프로그램들의 집합체. 실행에 옮기는 애가 deployment controller. deployment실제로 실행하는 애
replica를 4개 유지? replica controller가 한다. 정말 소프트웨어의 집합체
pod으로 실제로 yaml파일을 실행에 옮기면 deployment
컨테이너들의 집합이다 쿠버네티스도!! 각 프로그램이 컨테이너로 되어있다
kubectl create deployment my-dep --image=busybox
이미지를 가져다가 실행함.
우분투 이미지, 알파인 이미지
알파인 쓰면 명령이 제대로 돌아가지 않는 느낌을 받는다 작아서
알파인같이 작은 리눅스에는 busybox를 설치한다
알파인 쓰는 이유는 우분투에서 딱히 쓰는게 없어서.
busybox는 소프트웨어이름. 유닉스 위해 탄생했는데 리눅스에서도 사용함. single executable file이다. utilities를 모아놓은것 swiss army knife of embedded linux
유닉스 = 운영체제가 시간지날수록 점점 커질것이다. 커널이 커지는게 아니라 새로운 기능이 추가되는거니 명령이 별도의 실행파일로서 별도로 만들어진다. 그럼 운영체제 계속 커진다. 운영체제 안에 기능으로 들어갈 필요는 없다. 작아진 운영체제 위에 기능을 별도의 프로그램으로 개발하고 그 프로그램을 설치하기.
유닉스 리눅스 신봉자는 굉장히 작게 기능을 만든다.
grep이라는 명령 = 파일 안에 어떤 키워드가 어디있는지 바꾸는 등의 명령
nano같은 터미널 에디터. 원래 기본은 vi였다. 따라서 alpine이라는 작은 운영체제는 명령들이 부족하니까.. 유닉스 스타일의 자연스러운건 개별적으로 그 명령을 설치하는것. 불편하고 힘든 일.. 리눅스 변종들이 많은데 시스템의 개발자가 필요한 명령들만 넣어놨으니. n개의 프로그램이어야 할 애를 하나로 때려박은것.
명령을 하나하나 설치하는건 원시적이고 busybox를 설치해서 모든 명령어 사용이 가능함.
도커 쿠버네티스 젠킨스 busybox 기억해뒀다가 alpine에 busybox설치해보고
kubectl create deployment라고 하면 create가 큰 명령 같지만 사실 다른 프로그램에 요청하는것 작게작게 만들어놨다
Ingress
집합체. firewall reverse_proxy load balancer
앞쪽에서 받아서 뿌리는 애. 클러스터 안은 노드들의 집합
클러스터 밖은 쿠버네티스가 장악한 바깥세계. 구멍은 고객 요청 입구
ingress는 입구를 장악하고서 필요할만한 기능을 구현해놓은애
load balancing등을 수행. pod중에 누구에게 줄지 결정
ssl termination secure socket layer tcp암호화 프로토콜
암호화는 우리의 서버 사이에서는 안한다.
ssl은 웹브라우저로부터 우리 쿠버네티스 서버의 입구 사이의 암호화된 프로토콜
내부는 암호화 안하고 외부만 암호화하니까 입구에서 끊어야함. ssl termination
virtual hosting? a라는 컴퓨터가 domain을 받아주는 컴퓨터고 이 서버가 죽을수 있는데 이 서비스는 죽으면 안된다. ip주소를 물리적인 장치에 주지않고 virtual주소로 오게한다. 고객은 가짜 ip주소를 보고 있어서 물리적인게 바뀌어도 영향을 받지 않음. 사용자는 이름가지고 접근한다. ip는 독립적. virtual ip도 있음..
ip주소로 컴퓨터를 식별한다? 사실 거짓말이다 줄에 주는거다.
내 서버가 줄을 4개 가지고 있으면 4개의 ip를 가진다
ip주소는 컴퓨터를 식별한다? 사실은 거짓말이다..
ip주소라는 컨셉 자체가 이해가 어렵다 굉장히 복잡하게 돌아감. 몰라도 됨 네트워크 사용하는 사람은. 네트워크 장치 건드릴거 아니면
Killercoda
쿠버네티스 playground 제공함
linux virtual machine이다
멀티노드 싱글노드 둘다 제공함
실습방법 no.1
방법2. 도커데스크탑 enable k8s하면 굉장히 많은 controller가 컨테이너 형식으로 수행된다. 죽이면 다시 살아난다. 계속 복구하기 때문에. 제대로 안끄면 계속해서 유지한다.
minikube 도커데스크탑에 k8s enable하면 명령어 다 칠수있긴 한데
그래서 minkube설치안해도 된다. 명령어 먹힘
그래도 설치하기. 실습하기 편해진다 쿠버네티스가 너무크고 multinode구축이 너무 힘들었던 개발자/학습자들이 한대의 컴퓨터로 쿠버네티스 쉽게 배우고 개발할 수 있도록 만든것
내 노트북에 클러스터 만들기 용이한 기능을 제공함
hello kubernetes
클러스터 생성 deploy pod과 node확인하고 service접속해보기
쿠버네티스에서는 라벨 굉장히 많이 씀
도커데스크탑에서 쿠버네티스 키고 minikube설치 기본명령 실행해보고 4개의 튜토리얼 읽고 실행해보기 마지막것만 확인받고 방탈출
minikube version
minikube start --wait=false
kubectl version
kubectl cluster-info
kubectl get nodes
kubectl get all
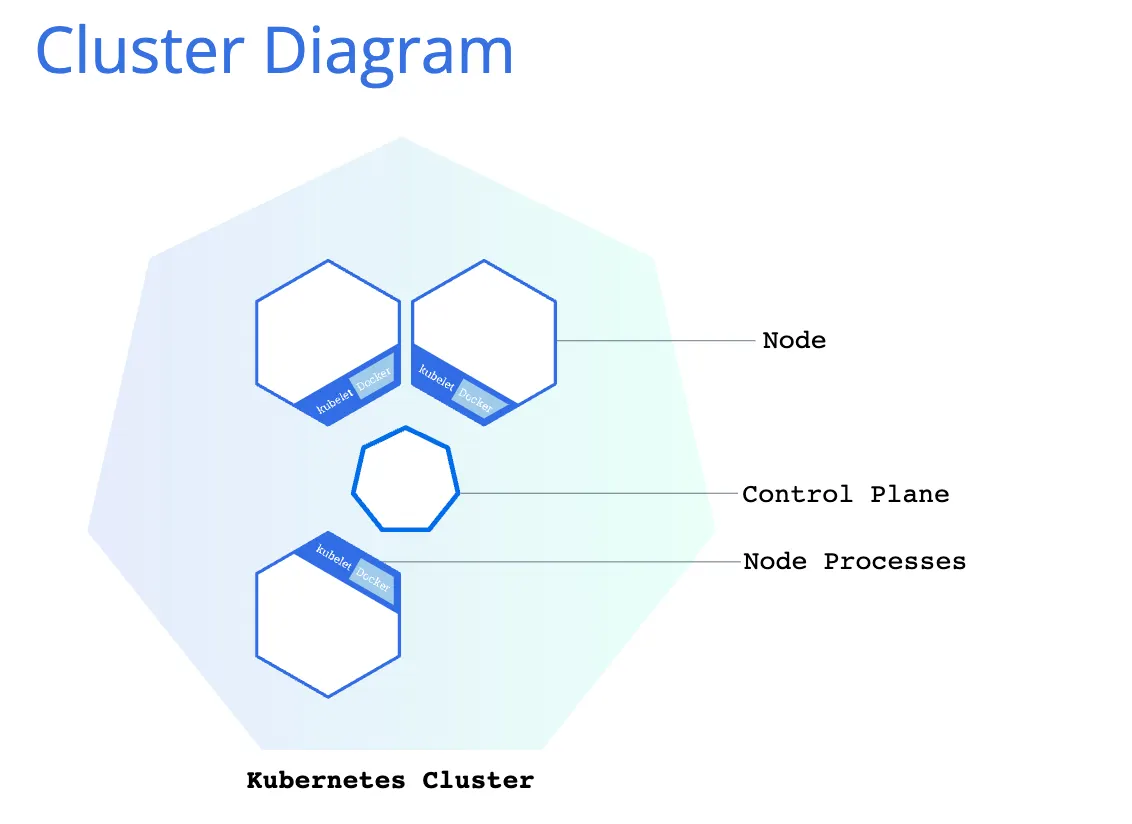
Kubernetes coordinates a highly available cluster of computers that are connected to work as a single unit. The abstractions in Kubernetes allow you to deploy containerized applications to a cluster without tying them specifically to individual machines. To make use of this new model of deployment, applications need to be packaged in a way that decouples them from individual hosts: they need to be containerized. Containerized applications are more flexible and available than in past deployment models, where applications were installed directly onto specific machines as packages deeply integrated into the host. Kubernetes automates the distribution and scheduling of application containers across a cluster in a more efficient way.
A Kubernetes cluster consists of two types of resources:
•
The Control Plane coordinates the cluster
•
Nodes are the workers that run applications
The Control Plane is responsible for managing the cluster. The Control Plane coordinates all activities in your cluster, such as scheduling applications, maintaining applications' desired state, scaling applications, and rolling out new updates.
A node is a VM or a physical computer that serves as a worker machine in a Kubernetes cluster. Each node has a Kubelet, which is an agent for managing the node and communicating with the Kubernetes control plane. The node should also have tools for handling container operations, such as containerd or CRI-O. A Kubernetes cluster that handles production traffic should have a minimum of three nodes because if one node goes down, both an etcd member and a control plane instance are lost, and redundancy is compromised. You can mitigate this risk by adding more control plane nodes.
When you deploy applications on Kubernetes, you tell the control plane to start the application containers. The control plane schedules the containers to run on the cluster's nodes. Node-level components, such as the kubelet, communicate with the control plane using the Kubernetes API, which the control plane exposes. End users can also use the Kubernetes API directly to interact with the cluster.
A Kubernetes cluster can be deployed on either physical or virtual machines. To get started with Kubernetes development, you can use Minikube. Minikube is a lightweight Kubernetes implementation that creates a VM on your local machine and deploys a simple cluster containing only one node. Minikube is available for Linux, macOS, and Windows systems. The Minikube CLI provides basic bootstrapping operations for working with your cluster, including start, stop, status, and delete.
