
개요
H.263은 real time communication 표준이며, ipppp..구조를 가진다.
64kbps 이하급 low bit rate 모바일 네트워크 등의 환경에서 동영상 데이터 압축을 목표로 한다.
h.261의 코딩 알고리즘을 기반으로 함.
•
half pel단위 MC를 수행하며 루프필터는 사용하지 않음
•
DCT coefficient의 3D VLC
•
Median연산을 통한 움직임 벡터 예측
•
향상된 CBP전송
•
GOB헤더 생략 기능
코딩효율 향상을 위한 옵션 모드
•
unrestricted mv mode
•
advanced prediction mode
•
pb-frames mode
Motion Vector Prediction (MVP)
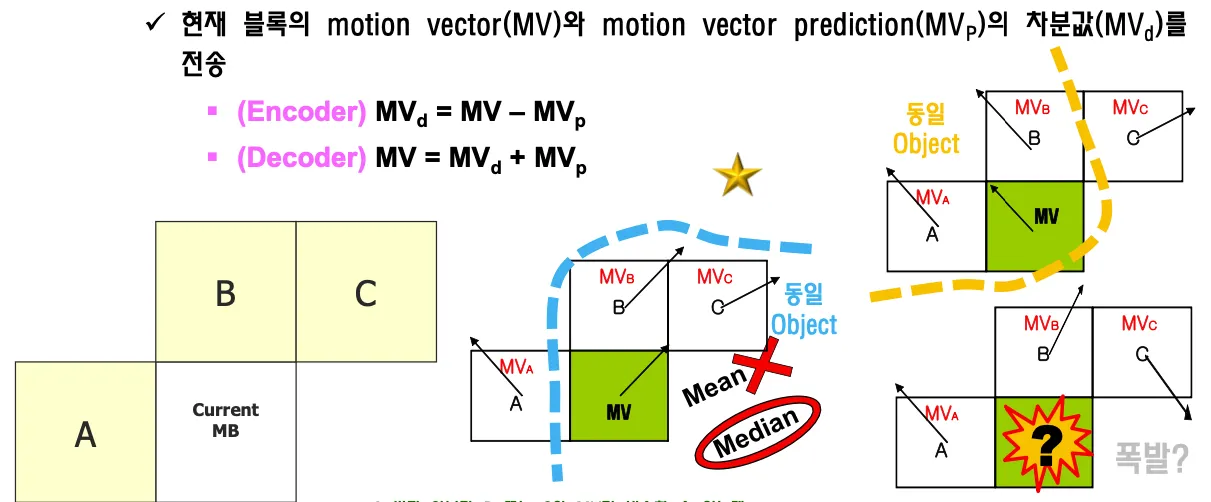
median 연산을 해서 motion vector를 보낸다.
current MB가 a, b,c의 mv값 중 어디와 같을지 모른다. encoder에서는 어디와 같은지 아는데 decoder에서 어디와 같은지 알리려면 mode 정보를 보내야한다.
H.261, MPEG-1에서는 a로부터만 가져오기로 약속했지만 그러면 코딩 퍼포먼스가 떨어진다. 그렇다고 모드정보를 보내면 정보량이 늘어난다. 그래서 이걸 탈피하기 위해서 a,b,c 의 median 값을 보낸다
어떻게 약속하면 모드정보 없이 mvp를 잘 알려줄 수 있을까를 고민한 결과이다. mena값이 아니라 median값이다. 동일 object인지를 판단하기 위해서이다. 동일 object끼리는 비슷한 방향으로 움직인다.
object를 찾기 어렵기 때문에 block을 object로 가정한다.
CBP
H.261에서는 Luminance(Y)의 특징과 Chrominance(CbCr)의 특징이 다른데 한꺼번에 놓고 VLC를 구하니까 발생확률을 제대로 적용하지 못했는데 H.263에서는 분리해서 적용한다.
MB내 각 8x8블록 내에 코딩할 데이터가 있는지 판단한다. CBP for Y와 CBP for Chrominance로 분리
intra block일 경우 y값 다 코딩하고 inter일 경우 y값 다 코딩 안하는 경우가 많다
Unrestricted Motion Vector
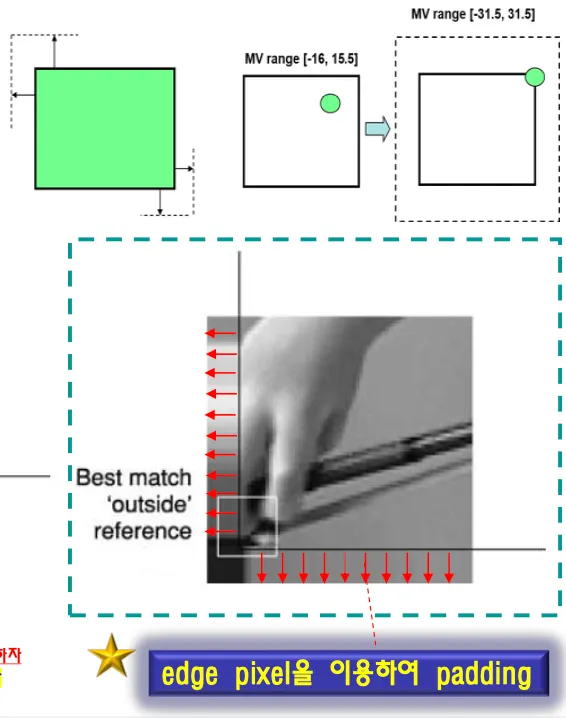
object가 영상 안으로 들어갔다 나왔다가 하는 경우가 있음. 밖에있던 영상이 안으로 들어온다
Motion vector가 픽처의 바깥쪽을 포인팅 할 수 있도록 허용한다.
Search Range를 영상 밖으로 확대하는 것이다.
영상 바깥까지 찾아서 matching될수 있다. 원래 영상 밖에잇는 데이터는 그냥 garabe이다.
영상 밖에는 픽셀값이 존재하지 않으므로 극단적인 차값이 구해진다.
영상경계의 edge픽셀값을 padding해서 cost/error값 왜곡을 피한다.
Advanced prediction mode
매크로 블록의 크기를 경우에 따라서 크게, 세밀하게 조절해서 나눌수 있게 함.
16x16블록 한개 혹은 8x8블록 4개 중에서 선택적으로 사용함.
요즘 코덱에서는 asymmetric하게 다양하게 쪼갤수도 있다. 32X16처럼
4개의 mv를 사용하면 더 나은 예측결과를 가지고 올 수 있지만 많은 비트를 필요로 한다.
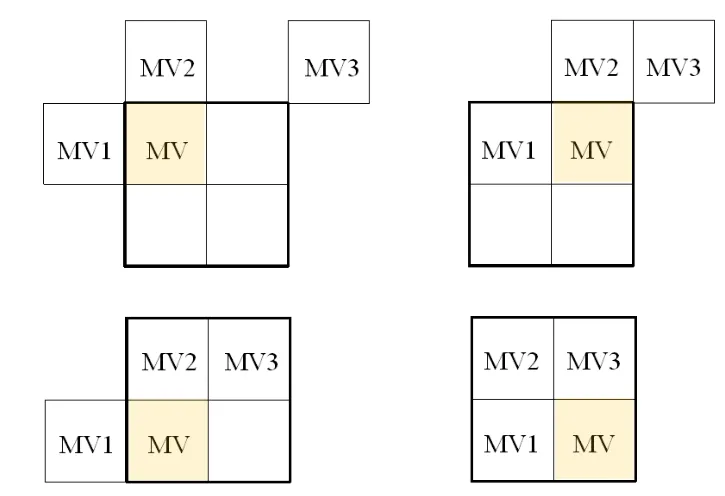
mvp를 어떻게 구해야할지가 복잡해진다.
주면 매크로블록이 4칸으로 나뉠수도 있고 하나일수도 있기 때문
주변블록의 mv의 크기가 얼마인지 모른다.
16x16인 경우와 일관성있게 유지한다.
pb-frame mode
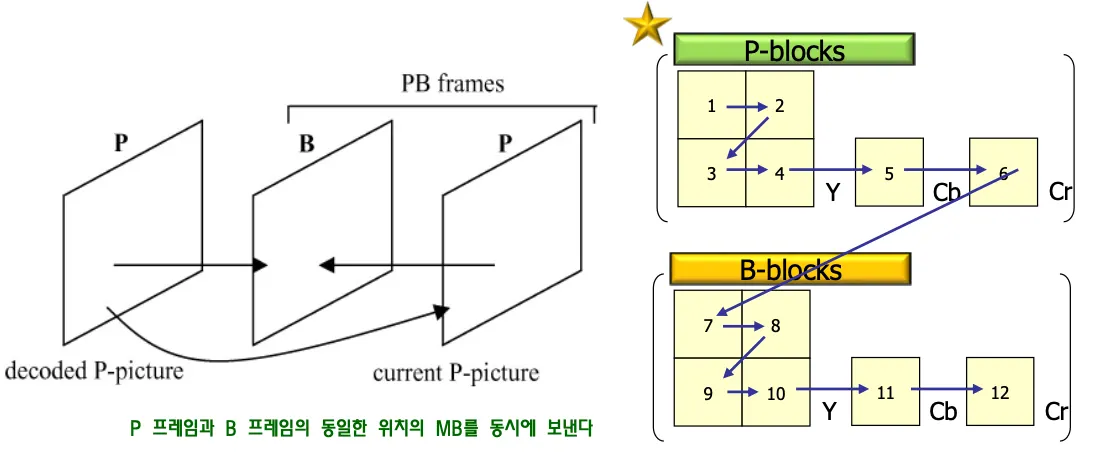
real time에서 b-frame을 적용하면 delay가 발생한다. B프레임을 사용하면 사이즈가 작으므로 화질을 개선할 수 있다. 그래서 coding efficiency를 높이기 위해서 약간의 delay를 감수한다.
두개의 픽쳐 p와b를 하나의 유닛으로 코딩한다. 한개의 매크로 블록에 12개의 블록이 들어간다.p프레임과 b프레임의 동일한 위치의 MB를 동시에 보낸다.
같이 보내서 조금이라도 파라미터 보내는 시간 줄여서 딜레이 줄인다.
Stuffing
ESTUF PSTUF = 바이트 정렬을 위한 8비트이하의 0들로 구성된 비트열. (Picture Layer)
데이터를 바이트 단위로 끊을수 있게 만들기 위해서(byte align을 위해서) 넣는 stuffing
비트 단위로 영상을 처리하지 않아도 돼서 좋다.
EOS 시그널 22바이트. EOS안오면 영상 전송 안끝난거다.
GOB Layer에서는 GSTUF ⇒ 동일하게 start bit를 byte단위로 정렬한다.
Macroblock layer
COD 해당 매크로블록은 코딩할거 없으니 넘어가라는 신호
intra일때 건너뛰게 만들고 inter일때는 매크로블록에 코딩할게 있다.
MCBPC신호등. MBTYPE과 CBP for y를 같이 넣은것
MPEG-4
학술적인 연구목적으로 개발된 코덱으로 당시에는 구현할 수 없었던 꿈의 코덱이었지만 이제는 multiple camera, depth map카메라가 대세이므로 마음만 먹으면 언제든지 구현할 수 있는 실질적인 codec이다.
각 오브젝트를 따로 떼서 처리할 수 있다. 각 shape를 찾아서 처리해아하는데 요새는 카메라가 여러개 있기 때문에 depth를 찾아낼 수 있다. 여러개의 카메라가 있어야 한다. 카메라간 거리를 통해 삼각측량으로 depth를 알수있다. 주변 배경을 바꾸거나 object를 식별할 수 있다.
배경과 각 오브젝트 분리해서 따로 보내고 디코더에서 처리할 수 있다. 사용자와 interactive하게 표현할 수 있다.
still image, audio object등을 각각 따로 코딩한다.
2d background를 sprite라고 한다. feature point들을 조작해서 내가 촬영하지 않은 영상도 만들수 있다.
facial feature point는 84개를 변경해서 표정을 변경하거나 visual, audio object등을 빼거나 할 수 있다.
디코더에서 비디오를 구성하기 위해서 scene description이 필요하다
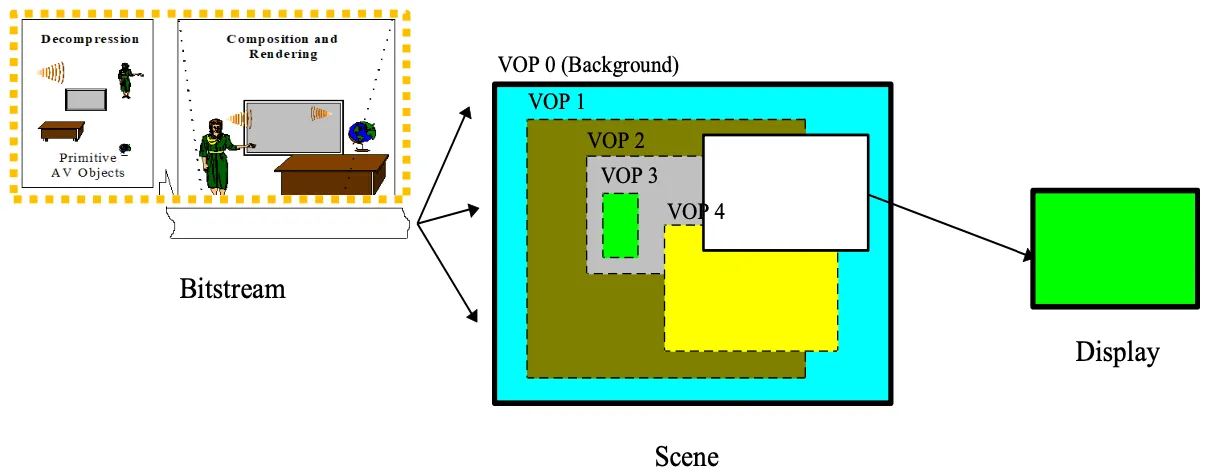
VOP Reconstruction
각 오브젝트를 따로 보내려면 각각을 따로 보내는 프레임을 만들어야한다.
Video Object Plane(VOP) 하나의 영상안의 object마다 plane을 따로 둔다.
각각의 vop는 독립적인 spatial, temporal resoultion을 가지고 있다.
video object는 사용자가 접근할수있고 조작할수 있는 flexible한 entity이다.
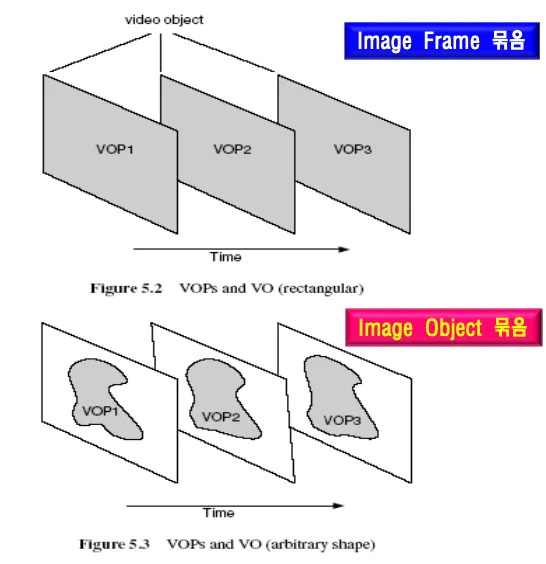
VOP = 특정 시간에서의 VO의 인스턴스
VOP는 비디오의 한 프레임, VO는 연속적인 image frame의 묶음
각 vop는 프레임 내에서 독립적으로 부호화되고 일정하지 않은 모양의 VOP가 모여서 VO가 된다.
VLBV(very low bitrate video), high bitrate는 고화질 content based에는 이미지 변경 등의 기능 포함

기본적인 frame based코덱은 텍스쳐(DCT), Motion(MV)처리하는 코어가 있고
generic 코덱은 image object의 shape을 포함해서 보내준다. object의 shape을 보낼때 edge가 많이 발생할 수 있기 때문에 처리할 수 있는 방법이 필요하다.
기존 video codec과 다른점은 오브젝트마다 각각 따로 코딩한다는 것. VOP단위로 각각 parallel Processing이 가능하다.
video object를 처리하기 위해서 shape = 경계면을 구해야한다.
VOP Encoder
1.
shape coding
2.
object밖의 0값을 ME/MC적용할수 있는 content기반 방법
3.
절벽을 없애기 위한 content based texture coding
3가지 기능이 add-on 되어야 한다.
ME/MC
Frame based ME/MC + Context-based ME/MC
h.263에서 사용했던 Unrestricted ME/MC, advanced prediction mode, Half pel ME/MC, bidirenctional Motion Compensation등을 그대로 가져온다.
Context-based ME/MC: 정확도를 높이기 위해서 패딩을 통한 Polygon Matching 사용
Bidirectional Direct Prediction
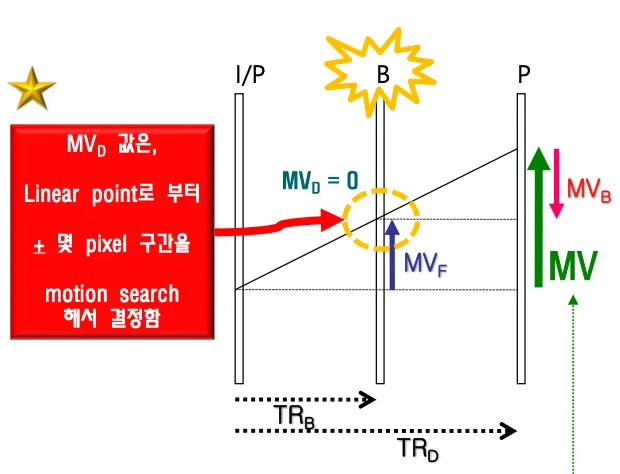
B-frame이 아니라 B-vop이다. 코딩효율의 향상을 위해서 양방향 예측을 사용한다. I-VOP 혹은 P-VOP간의 비례에 의해서 B-VOP을 자동으로 계산한다(Linear의 경우). Linear일 경우에는 자동계산되므로 MV값을 보내지 않고 Linear가 아닐 경우 MV의 보정을 위해서 delta값을 인코더에서 보낸다.
보정값(MVDB)이 전송된 경우 해당 보정값을 통해서 MV를 보정한다.
motion vector difference
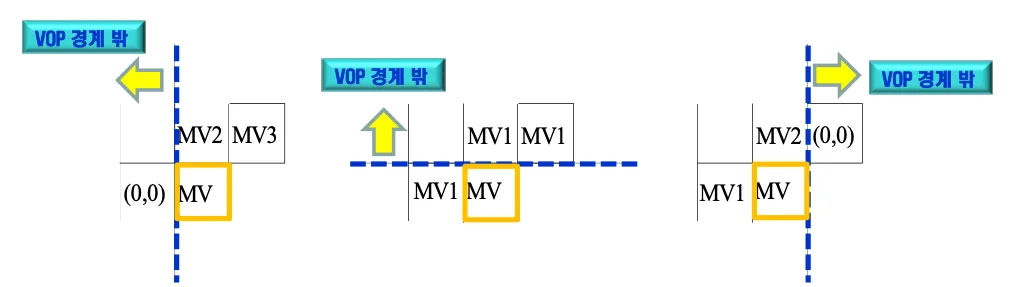
VOP경계 밖은 주변 블록이라도 믿지 않는다. (0,0)으로 처리하거나 사용할 수 있는 값을 median으로 사용
global motion compensation
global mv가 없다면 모든 블록에서 local mv를 보내야한다.
residual 역시 global mc이후에는 residual을 현저하게 줄일 수 있다.
global motion의 종류: panning rotation zoom-in zoom-out
Content/Object-based ME/MC
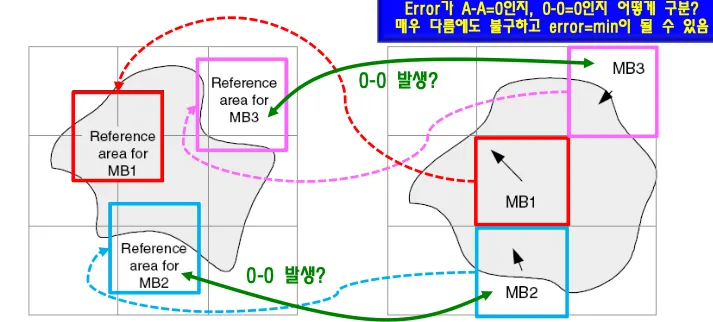
object경계 밖에는 pixel값이 없다. 경계 블록들은 픽셀값 있는곳과 없는곳이 겹쳐있다.
값 -값이 0인 경우와 그냥 0인 경우를 구분할 수 없어서 픽셀값 = 0에 의해서 cost function에 문제가 발생한다.
패딩을 통해서 픽셀값이 0이 되는 경우를 삭제한다.
아무것도 없는곳은 128 즉 중간값을 채워넣음
•
horizontal repetitive padding: 투명한 영역을 채움
•
vertical repetitive padding: interpolation으로 채움
•
extended paadding: 외부 MB를 128로 채움.
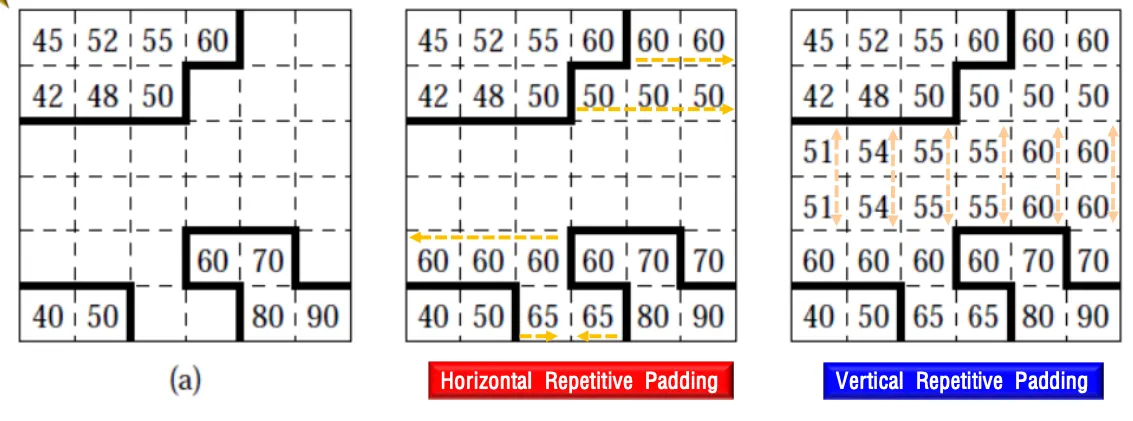
Basic Motion Technique
Polygon Matching

Shape내의 Pixel값에 대한 motion만 처리한다. Alpha ≠0이 아닌 경우에만 SAD계산한다.
Alpha값이 있는 픽셀에 대해서면 SAD를 계산함
motion vector를 구했는데 너무 difference가 크면 intra mode를 사용함(오리지널 영상)
Texture Coding
2d-dct object경계 밖이 0인데 그대로 dct하면 경계면에서 엄청난 high frequency가 생긴다
일반적인 2D-DCT를 적용할때 boundary에서 발생하는 엄청난 절벽에 대한 처리를 하는 방법이 필요함.
어차피 shape밖은 쓰레기라서 버리면 된다. 버려도 되는 데이터를 임의로 만들기 위해 내부 픽셀값의 평균값을 밖에 채워넣는다. 하지만 경계파트에서 약간의 edge가 발생하는데 그 경계파트를 smooth하기 위해서 LPE패딩을 사용함. 이후 shape정보가지고 자르고 나머지는 버린다.
inter는 residual이니까 라플라시안 분포를 가지므로 평균값은 0이 되고 패딩을 0으로 넣는다.
Shape-Adaptive DCT
shape에 적합한 dct를 적용해서 효율을 높일 수 있다. ⇒ 고화질에 유리
shape정보를 알고있으니 shape 내부의 픽셀 값들에만 dct를 적용한다.
shape을 구성하는 블록들을 쭉 밀어서 모아놓는다. 민 상태에서 DCT를 수 하고 그 계수를 다시 왼쪽으로 밀어서 다시 DCT하고 zigzag스캔해서 비트스트림으로 보낸다. 디코더는 역순 역방향으로 수행한다.
shape을 인코더가 디코더에게 보내므로 가능한 것이다.
Adaptive DC/AC Prediction
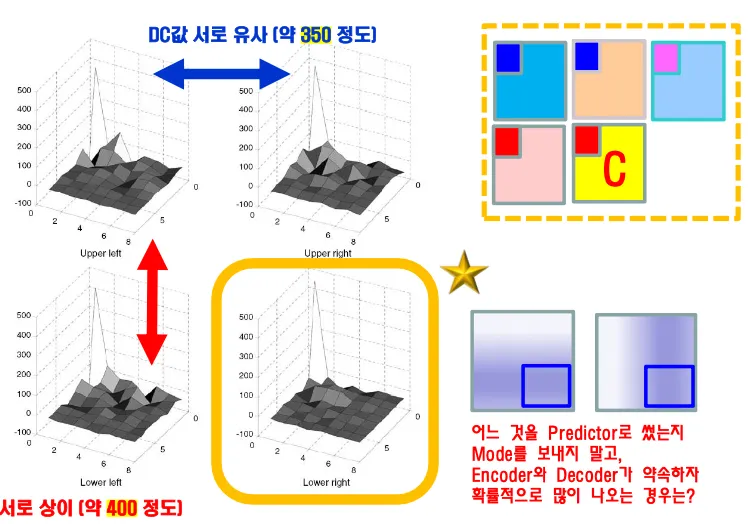
DC coefficient를 보낼 때 예측을 통해 데이터를 줄인다. 주변 데이터와 유사하므로 값이 0을 중심으로 라플라시안 형태로 모이므로 어디랑 비슷한지 predictor를 이용해서 데이터를 줄일 수 있다. 하지만 어디와 비슷한지 mode를 보내면 데이터가 늘어나므로 인코더와 디코더가 누구를 predictor로 쓸지약속해서 모드정보를 보내지 않고 처리하도록 한다.
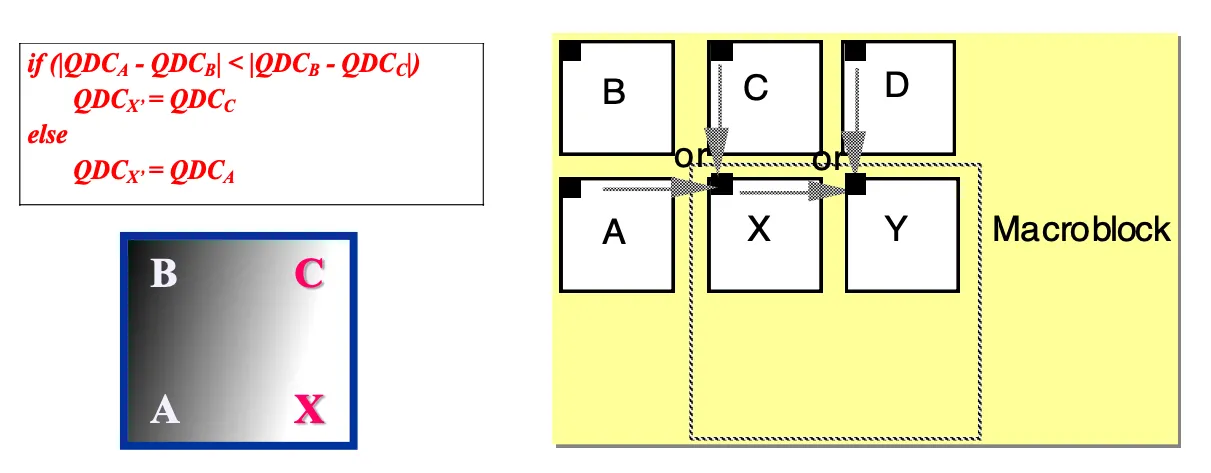
a와b비교해서 b와c를 비교한거보다 differencerk 작으면 위쪽의 DC값을, 그렇지않으면 왼쪽으로 predict
AC Prediction도 동일하다. 이전 블록의 첫번째 행이나 첫번째 열을 현재 블록의 AC predict에 쓴다.
•
DC (Direct Current): 블록의 평균 밝기를 나타내는 0Hz 성분. 변환 코딩에서 블록의 첫 번째 계수로 저장됩니다.
•
AC (Alternating Current): 0Hz를 제외한 나머지 주파수 성분으로, 영상의 세부적인 변화(텍스처, 경계선 등)를 나타냅니다.
Binary shape coding
shape을 어떻게 전송할까? object 밖은 다 0이고 object안은 채워져있다. boundary block을 처리해야 한다.
Vertex-based Shape Coding
Error에 약하다. 잘못된 vertex를 가리키면 object내에 채워지는 texture가 왜곡되어서 처리된다.
하지만 일반적으로 block based shape코딩보다 효율이 좋다.
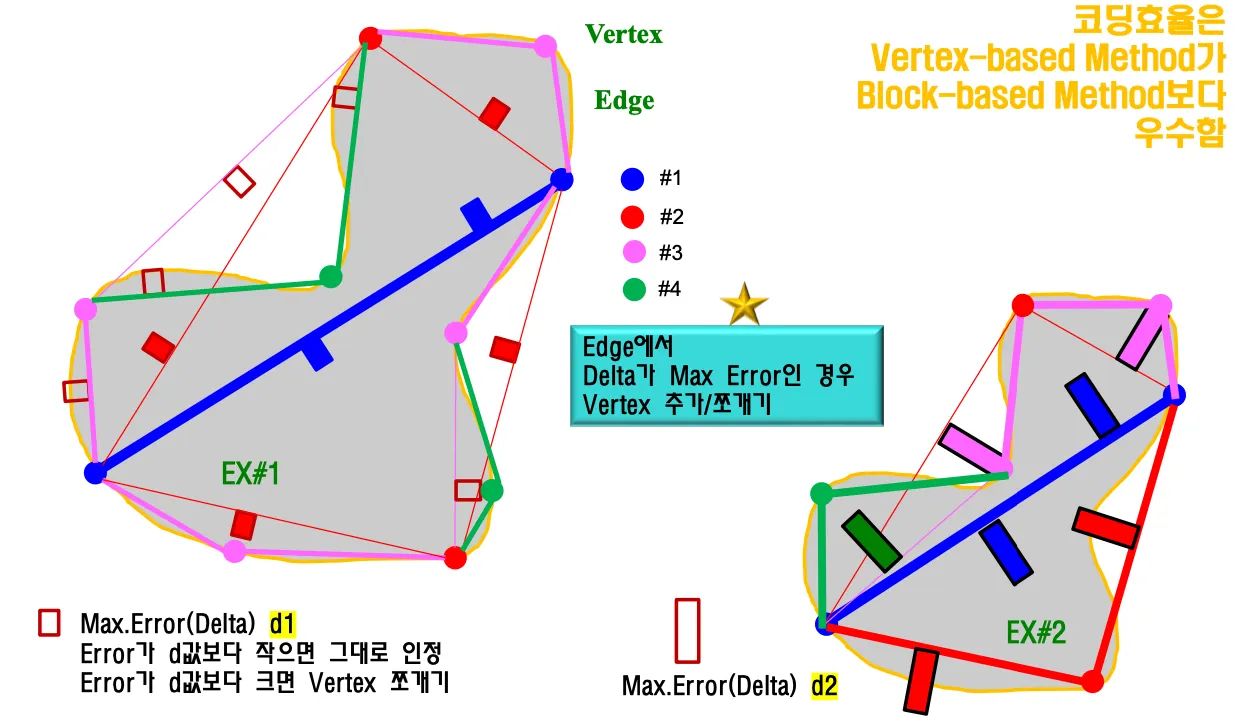
block based shape coding
에러에 강해야 하는 상황이라 block-based를 채택했다. 블록 안에서만 에러가 국한되게 만들어서 propagation을 막고 localization할 수 있다.
shape정보를 너무 많이 담으면 mv, dct정보를 충분히 보낼 수 없다.
shape정보를 얼마나 정확하게 보내야하느냐에 따라서 boundary block내의 정보를 rate control한다
shape정보를 깨끗하게 보냈는데 texture가 적으면 어색하고 shape을 적게 보내면 삐뚤삐뚤해보인다.
16x16 MB를 16개의 4x4 BAB(Binary Alpha block)으로 나누어서 구성한다. 각 BAB의 threshold ⇒Error를 허용하는 척도를 넘어서면 수정이 필요하고 그 이하는 허용한다.
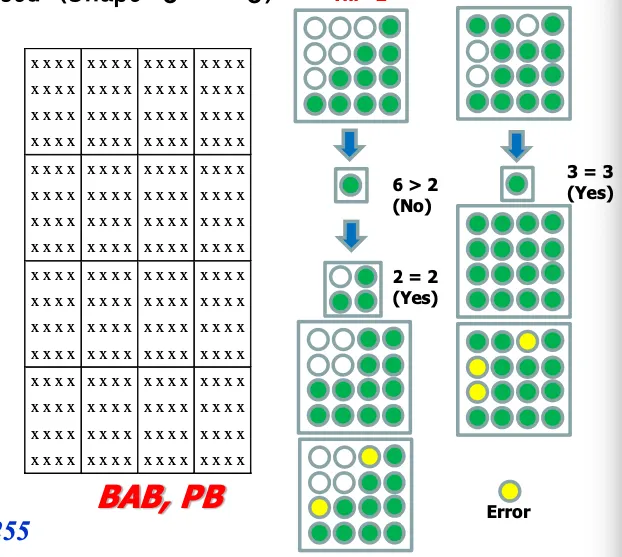
threshold와 비교해서 downsampling해도 quality차이가 없으면 축소된 alpha map으로 처리한다.
에러가 허용치를 넘어가면 downsampling한다. 그다음 다시 upsampling하면 error가 발생할건데 허용범위면 그냥 채운다.
acq가 0이면 error척도를 만족하지 못하는 bab가 있다는 거니까 수정한다.
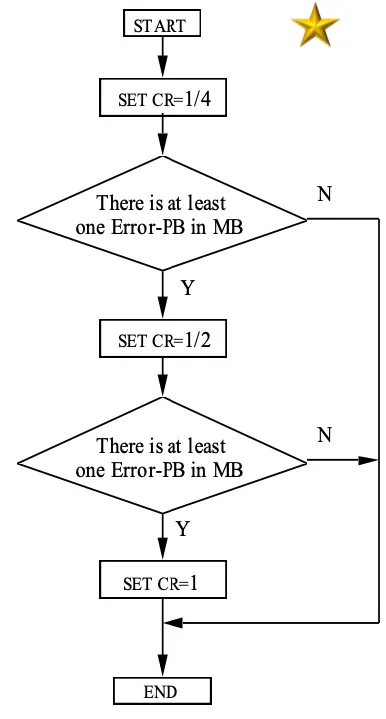
CAE(context based arithemtic coding)
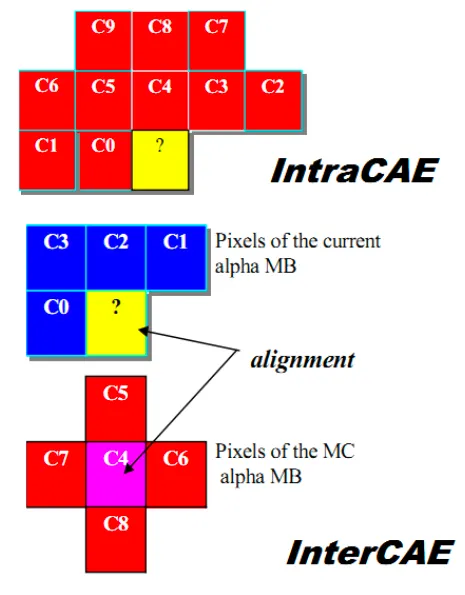
그전 픽셀값들을 훨씬 더 많이 보는 형식이 intra CAE이다. 10개의 픽셀값을 사용함.
많은 값을 봐서 트렌드를 봐서 1인지 0인지 알 수 있는 확률이 높아진다.
inter일 경우에는 현재 픽셀의 주변값과 reference frame의 자기 픽셀값 주변의 상하좌우 값
inter는 9개의 픽셀값을 봄.
error resilience
에러가 발생해서 correction하려면 에러가 발생했는지를 알수있어야한다
에러 detection을 위해서 flag를 사용한다. 에러를 수정할지 못할거같으면 숨길것인지를 결정한다.
•
Resynchronization: 일정한 간격으로 resync marker를 심는다 = flag. Error가 발생한 이후 Marker가 발견되면 error localization된다. 480비트 단위마다 하나씩 marker를 단다.

•
Data Recovery: RVLC를 사용해서 recovery. 거꾸로 해도 같은 VLC를 보내서 Forward VLC와 Backward VLC를 비교해서 에러가 발생한 부분 확인. 실제로 에러가 발생한 부분이 작을 때 최대한 해석해서 recovery하는 방법으로 에러가 많이 발생할수록 도움이 된다. 하지만 데이터를 다시 받아와서 수정하는 과정이 복잡하기 때문에 잘 안쓰인다.
•
Error Concealment: Error를 수정하지 않고 은닉한다. 이전 frame에서 현재 위치의 영상 데이터를 그대로 가져와서 메꾸면 frame이 순간적으로 지나가니까 잘못된것을 인식하지 못함.
다른 방법은 두번째 resync marker를 MV와 Texture사이에 넣어서 MV에서 에러가 발생해도 텍스쳐는 살릴수 있도록 하는 방법이 있다
NEWPRED
P-VOP = predictive coding의 장점은 프레임간 데이터가 유사한 경우 데이터를 크게 줄일 수 있다는 장점이 있지만 에러가 발생했을때 에러가 propagation된다는 문제가 있다. 프레임 갈때마다 전달되어서 커지는것이 predictive의 단점이다 . i-frame이 와서 초기화될때까지 계속 이상해진다.
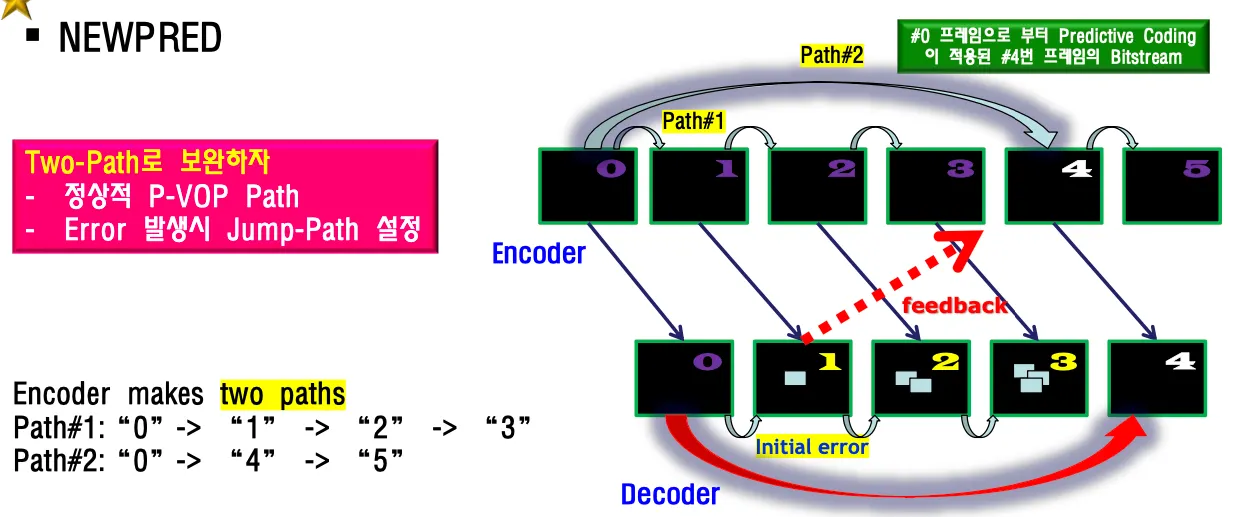
NEWPRED는 시간축 상의 영상간 error propagation을 막는 방법.
two-path를 사용해서 predictive path를 건너뛰는 path를 하나 만든다.
정상적인 P-VOP path 하나와 Error발생 시 Jump-Path를 설정한다.
1번프레임에서 에러 발생한것을 디코더가 알게 되면 4번째 프레임 디코딩할때 0번으로 prediction한다.
단점은 바로 옆 프레임이 아니기 때문에 프레임간 유사도가 떨어져서 압축성능이 감소한다. 하지만 에러가 많이 발생한다면 쓸만함.
Scalable Video coding
고성능 디코더에 화질이 나쁜 동영상을 보여주는것은 싫고 저성능 디코더에 화질이 좋은 동영상을 보내줘도 디코딩할수 없다. 디바이스의 디코더 성능에 맞춰서 데이터를 보내줘야 할 필요가 있다.
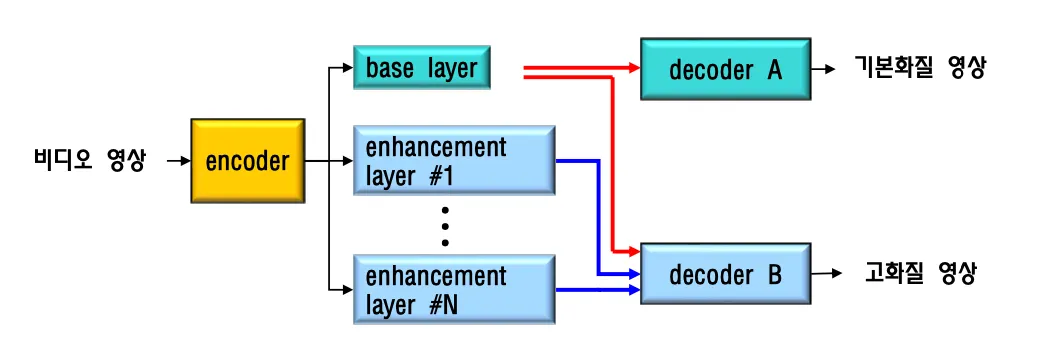
low performance 디바이스에서는 basic quality의 영상을 보내준다.
temporal sacalability와 spatial scalability ⇒ frame rate를 조절 + 영상크기 resolution을 조정
비트스트림을 영상크기별로 다 갖고있다가 보내줄수도 있고 encoder에서 base layer를 먼저 만들어서 decoder에 보내주고 enhancement layer를 거쳐서 고화질 영상을 보내줄수도 있다.
Spatial Scalability
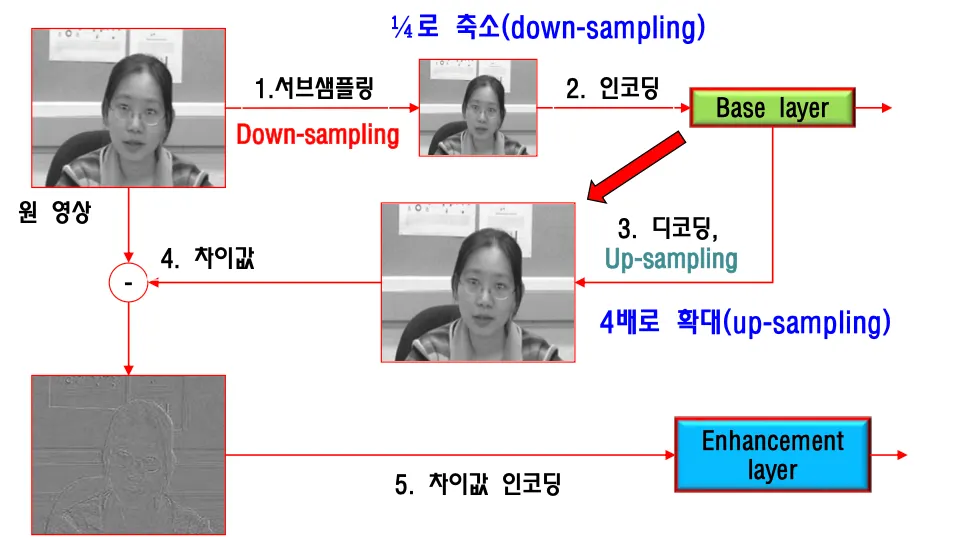
원영상을 down-sampling해서 작게 만들고 인코딩해서 base layer로 만들어서 보낸다.
base layer를 4배로 up-sampling해서 원영상과의 difference값을 계산해서 차이값을 인코딩해 enhancemet layer로 보낸다. high pass filtering과 유사하다.
Temporal Scalability
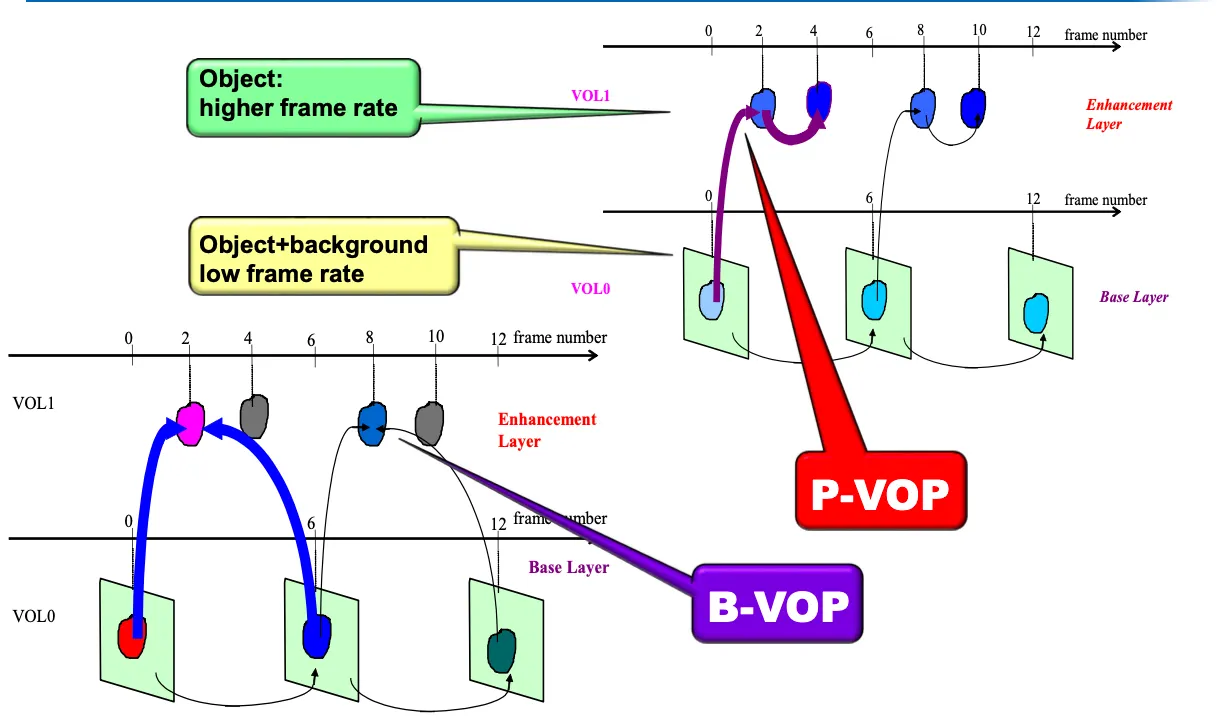
Enhancement layer에서는 P-VOP의 경우 object를 더 보내서 hz를 높이고 B-VOP의 경우 과거, 미래 object를 가지고 object를 더 만들어낸다.
